大模型行业的战火,正在从"基座智商"烧向"终端入口"。
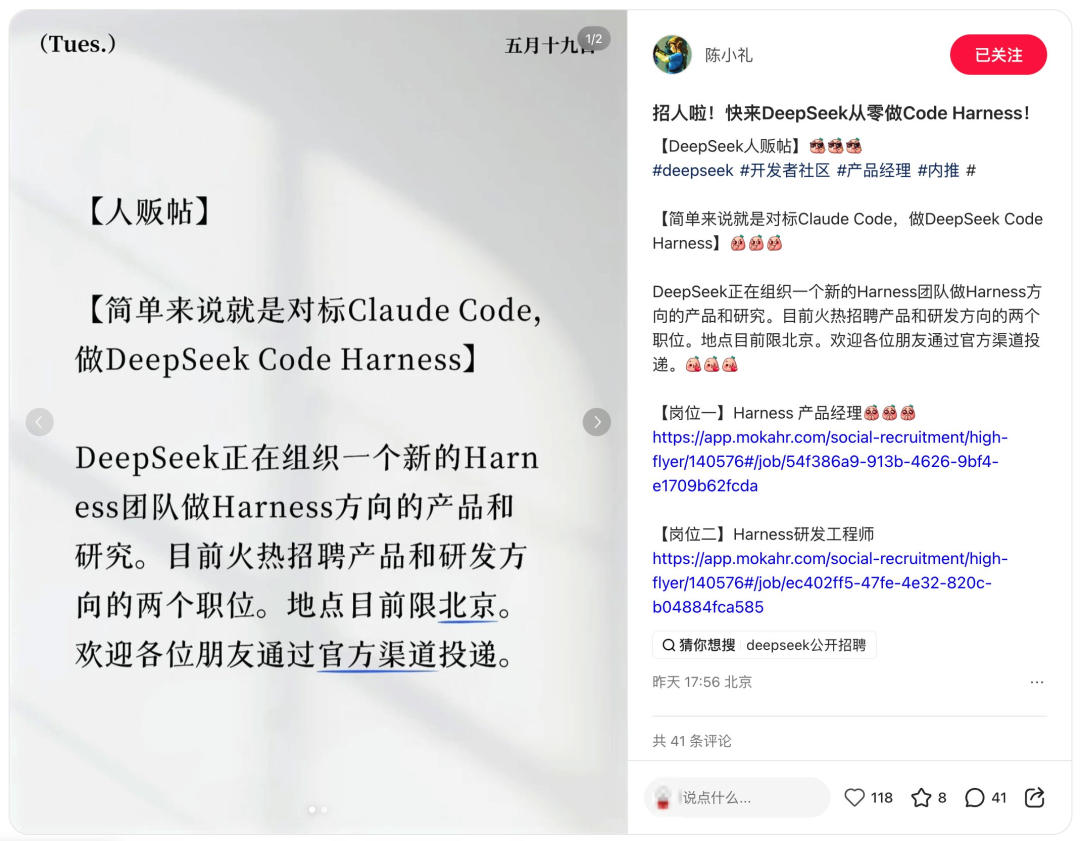
5月19日,DeepSeek 资深研究员陈德里在小红书上发了一条招聘贴,证实内部正在组建全新的"Harness"(代码智能体工程)团队,目标直指 Anthropic 旗下的明星产品 Claude Code。
这条消息的冲击力不在于"DeepSeek 要做编码工具了",毕竟一家有模型的 AI 公司做编码工具再正常不过。真正值得注意的是:一家习惯于底层模型研究的公司,终于开始跨出实验室,亲自下场打造桌面端生产力入口。
招聘信息显示,DeepSeek 目前在北京海淀区开放了 Harness 产品经理与研发工程师两个岗位。新成员将全程参与"DeepSeek 桌面端 Agent 产品"研发全过程。招聘描述将核心路径定义为 Model + Harness = Agent。
与其说这是一次例行的团队扩张,不如说这是 DeepSeek 从"模型公司"向"产品公司"战略转向的第一个组织信号。
一、Model + Harness = Agent:工程哲学
很多外行人不理解,为什么 DeepSeek 已经有了这么聪明的模型,还要组建团队去做"Harness"。打个比方,DeepSeek 的模型就像一匹日行千里的"超级神马"。它力大无穷,什么路都能跑。但光有马不行,你得让它拉车。这个 Harness 团队,干的就是打制"马具"和"马车"的活。
以前 DeepSeek 只管养马,把马借给别人拉车。可别人做的马鞍可能磨腿,缰绳可能太松,马车轮子还总掉。结果就是:马虽好,车跑得磕磕绊绊,坐车的人还以为是马不行。
现在的 DeepSeek 反应过来了:要想车跑得又快又稳,就得自己打马具、造车。更关键的是,只有自己亲自赶车,才能感觉到哪段路有坑,哪种跑法马最省力。赶车人学到的每一条"路况经验",都能回来喂给自家的马,让它下次跑得更聪明。
在技术层面,Harness 团队要做的事情可以拆解为五个核心模块:
- 上下文管理:让 Agent 理解长程对话和项目结构
- 工具调用:让 Agent 操作外部 API、数据库和文件系统
- 文件读写:让 Agent 处理实际项目文件
- 终端执行:让 Agent 执行命令并与系统交互
- 测试反馈闭环:让 Agent 从错误中学习、迭代改进
这五件事,正是 Claude Code 能够成为"最强编码 Agent"的核心能力。其在 SWE-bench Verified 取得的 87.60% 的惊人成绩,很大程度上得益于模型之外的工程能力,即上下文处理、工具编排与反馈闭环。
此前,DeepSeek 某位研究科学家在接受媒体采访时曾给出一个颇有预见性的判断:
「做 Agent 的公司一年后都会消失,因为肯定做不过我们。」
这句话背后的底层逻辑显而易见:DeepSeek 认为 Agent 赛道最终会收敛到拥有基础模型的公司手中,独立的 Agent 创业公司很难构筑起持久的壁垒。但收敛并不意味着"不做产品"——恰恰相反,既然 Agent 是模型的自然延伸,那最应该亲自下场做的,正是模型公司自己。
这种"模型公司亲做 Agent"的思路,刚好与 Anthropic 收购 Stainless 时的战略表述同频。Anthropic 在官方公告中明确提到:"AI 前沿正在从'能回答的模型'转向'能行动的智能体',而智能体的能力取决于它们能连接到什么。"两家科技巨头最终选择了同一条路:把 Harness 层的控制权从第三方工具手里收回来,变成模型能力的自然延伸。

二、从"秀参数"到"做产品":中国AI的拐点信号
DeepSeek 此前最显著的身份标签是"开源模型公司"。从 V2 到如今的 V4 系列,它在 Hugging Face 上发布的开源模型一次次刷新了中国 AI 的技术天花板。但有一个事实常被忽略:在开发者生态中,DeepSeek 过去从未亲自做过面向开发者的桌面端生产力产品。
这与 DeepSeek 一贯的文化有关。梁文锋曾在多个场合表达过"专注基础研究"的定位。DeepSeek 的团队构成也印证了这一点:研究人员的比例远高于产品经理和工程师。但 Harness 团队的组建打破了这一定位。
更深层的信号在于时间节点。2026 年 5 月的这一周,AI 编码领域同时发生了三件大事:
- Google I/O 发布 Antigravity 2.0,推出全新的独立桌面应用,把 AI 编码从 IDE 插件升级为多 Agent 编排平台
- Anthropic 以 3 亿美元收购 Stainless,将 API 连接层直接纳入模型基础设施
- DeepSeek 组建 Harness 团队,亲自下场做代码智能体产品
三件事发生在同一周绝非巧合。它们共同指向一个明确的方向:AI 竞赛的焦点,正在从"谁有更好的模型"转向"谁有更好的产品闭环"。
更深层的背景是,DeepSeek 正在推进其成立以来的首次外部融资。据公开信息显示,本轮募资总额直奔 500 亿元人民币(约 73.5 亿美元),有望创下中国 AI 企业最大单笔融资纪录。Harness 团队的组建,正是这笔天量资金在产品端的第一个落子。
模型能力会快速商品化,但产品体验、生态绑定、以及由开发者工具筑起的护城河只会持续加深。
Google 和 Anthropic 已经用行动验证了这一点,而 DeepSeek 的选择意味着,中国 AI 头部玩家也全面看清了牌局的下一幕。
三、代码智能体的四方格局
当前的 AI 编码工具市场已经形成了清晰的竞争格局:
| 选手 | 核心优势 | SWE-bench | 年化收入 | 路线 |
|---|---|---|---|---|
| Anthropic Claude Code | 编码智能+工程判断力 | 87.60% | ~25亿美元 | 深度 |
| OpenAI GPT-5 | 数亿用户基数+完整开发循环 | — | — | 广度 |
| Cursor | 极致用户体验 | — | ~20亿美元 | 体验 |
| DeepSeek Harness | 成本+开源+中文优化+数据飞轮 | 待发布 | — | 性价比 |
DeepSeek Harness 在这个牢固的格局里,至少能找到四个维度的差异化生存空间:
- 极致的成本优势:DeepSeek V4 系列的 API 定价远低于 Claude 和 GPT。如果 Harness 延续这一补贴策略,它将成为全球性价比最高的编码 Agent。
- 原生的开源生态:DeepSeek 模型在开源社区拥有极高的活跃度,此前开发者已自发推出了 DeepSeek-TUI 等项目。官方 Harness 能够完美收拢并互补这些自发力量。
- 中文编码的天然护城河:Claude Code 和 OpenAI 都是以英文场景为主进行优化的。面对中文技术栈中的 API 文档、特定社区生态,DeepSeek Harness 在国内市场拥有语言和文化上的绝对优势。
- 最关键的数据飞轮:Harness 团队的底牌不仅是"做一款产品",更是通过真实项目中的代码测试、报错反馈,合规地反哺到底层模型的迭代闭环中。

四、Harness 背后的三层拐点信号
当然,DeepSeek Harness 目前还处于团队组建阶段,距离产品正式上线至少需要 6-12 个月的时间。这个时间差构成了巨大的不确定性:在这段窗口期里,Claude Code 的领先优势可能会进一步扩大。如果 Google 刚刚在 I/O 大会上发布的 Antigravity 2.0 也在同一时间抢占了更大的市场,DeepSeek 留下的入场空间将被进一步压缩。
对于仍在招兵买马的 Harness 来说,这注定是一场与时间的正面赛跑。
但抛开产品层面的不确定性,Harness 团队的组建本身释放了三层更深远的信号:
第一层——对 DeepSeek 自身:组织进化。从"开源模型实验室"到"产品公司",这意味着团队结构、决策逻辑、人才画像的全面重塑。如果成功,DeepSeek 将拥有中国 AI 领域继阿里 Qwen Code 之后第二个原生代码 Agent 产品。
第二层——对中国 AI 产业:竞争升维。过去两年,中国 AI 公司的竞争焦点一直是"谁的模型参数更多、跑分更高"。但从 2026 年开始,竞争正在加速向"谁的产品更好用、谁的生态更完善"转移。这是一个典型的"窗口期博弈":未来 12-18 个月,代码智能体市场将完成产品形态的初步固化。率先完成"模型→产品→数据"闭环的公司,将在下一个阶段获得结构性优势。
第三层——对开发者:更多选择、更低价格。当 DeepSeek 把"免费+开源+中文优化"的编码 Agent 推向市场时,Claude Code 和 OpenAI 编程版工作流的定价压力将显著增大。过去 AI 编码工具的价格已经呈现下降趋势,DeepSeek 的入局将加速这一进程。
总结
DeepSeek Harness 的组建,是中国 AI 的一道分水岭。分水岭的一边是"我有个好模型",另一边是"我有一款好产品"。从这一刻起,中国 AI 公司不再只是秀参数的人,也要成为做产品的人。
DeepSeek 的入局时间不算早,但它带着模型能力的底牌和开源社区的口碑入场。这步棋的胜负,取决于 Harness 团队能否在窗口期内跑通从"开源模型"到"产品体验"的最后一公里。
企业级 Agent 不是一个模型问题,而是一个工程问题。谁能把模型能力和实际业务系统打通,谁就拥有真正的竞争力。