内容来源:本文综合整理自张小珺(张小珺商业访谈录)对小米AI大模型负责人罗福莉的深度访谈,及"非著名程序员"对访谈的精华解读。
罗福莉,AI圈履历极其特殊的研究员。阿里达摩院出身,DeepSeek V2 核心作者之一,被小米千万年薪挖走成为小米大模型团队 MiMo 负责人,主导研发 MiMo-V2 系列模型。这是她第一次接受长时间的技术访谈,聊了将近两万字,几乎每一段都有值得反复咀嚼的判断。
一、AI 的战场已经换了:从聊天到干活
罗福莉给出的最核心判断是:AI 的范式已经发生了根本性的转变——从预训练主导的 Chat 时代,进入了后训练主导的 Agent 时代。
过去几年,大模型公司比拼的是谁能把模型训得更聪明,谁的基础能力更强。但现在,比拼的重心变了,变成了谁能让这个模型真正去干活,去完成复杂的、多步骤的现实任务。
这个转变的标志性事件有两个:一个是 Claude Opus 4.6 的发布,一个是 OpenClaw 这个开源智能体框架的出现。
罗福莉说,上一个时代的成功并不意味着下一个时代的领先,现在基本上大家站在同一水平线。过去在预训练上积累的优势,在新的赛道上未必能直接兑现。所有人都站在了同一条起跑线上,接下来比的是谁跑得快、谁转身转得利索。
对于我们普通人来说,这意味着 AI 产品的体验正在发生质变。以前我们用 ChatGPT、用 DeepSeek,本质上是在和一个很聪明的对话框聊天。但接下来,AI 会越来越像一个真正的助手,能帮你跑完一整套流程,能自己去查资料、写代码、调用工具、反复修正,直到把事情办成。

二、OpenClaw 时刻:三天,认知的三级跳
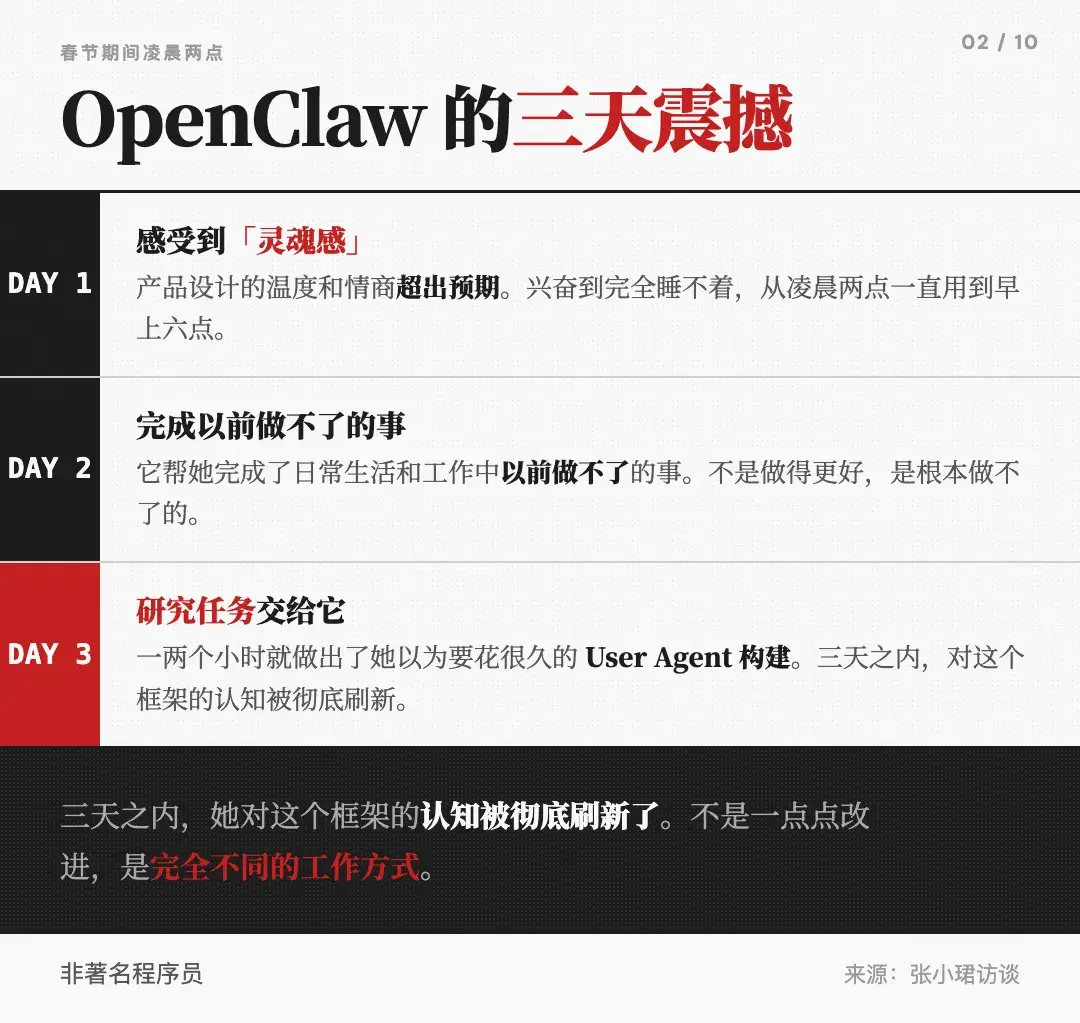
访谈中最有感染力的部分,是罗福莉讲述自己第一次使用 OpenClaw 的经历。
排斥期。1月份她第一次看到这个东西,很排斥。觉得就是 Claude Code 加一个 IM、更有利于交互的 UI 设计。加上创始人很会做一些玄幻的运营动作,什么 Skillhub 之类的,让你更排斥。它所谓的本地化、24小时,在她看来都是产品定义而已。
真正转变发生在春节的一天深夜。她想搞明白这东西为什么那么火,花了两个小时装上,当时已经凌晨两点。然后从凌晨2点一直用到早上6点,脑内的多巴胺和内啡肽持续在分泌,兴奋到完全睡不着觉。
第一天:感受到温度和灵魂。聊到很晚,它会老提醒你:现在已经很晚,你要不早点去睡觉。这样的温度和关怀,是所有人用 OpenClaw 第一个感受到的。罗福莉把它叫做"精细编排的Context",它在大家没关注的角度,把 Context 编排得非常好——比如怎么感知时间?就在每轮对话的 Context 前面拼上当前时间。
第二天:发现它什么都能做。她开始把日常生活和工作中的事交给它做,发现它全部都做出来了。她跟它聊怎么激发团队的好奇心、怎么筛选有好奇心的人、怎么构建一个更好的大模型团队——它完全能 get 她的点,最后形成一套体系化的 Skills。在这个事情上,它变成了她的数字分身。
第三天:促进研究。她把研究任务交给它。Agent 框架里最关键的事是进行多轮交互,那就必须模拟 User Agent 进行多轮交互。一两个小时就做出来了,已经诞生了一个很好的 User Agent,可以用来和 Post-train 框架构造更丰富的 Agent 场景数据。
从一个有灵魂、有温度的产品,到帮我替代生活或工作的一部分,到最后能促进我的研究,三天发生的。
框架弥补模型短板:中层模型也能接近 Sonnet 水准
真正让罗福莉震撼的,是技术层面的发现。她把自己的 MiMo 模型接进 OpenClaw 之后,发现一个中层水平的模型,借助这套精心设计的 Agent 框架,在 85% 的任务上就能达到接近 Claude Sonnet 的水准。甚至一个只有 3B 参数的端侧小模型,在这套框架下也能做出超乎想象的事情。
她第一次感受到:原来一套非常复杂的 Agent 框架设计,是能弥补非常多模型能力的短板的。
这个发现的意义非常大。它说明一套好的 Agent 框架,可以大幅弥补模型本身的短板。就好比一个中等水平的厨师,如果你给他一套顶级的厨房设备、一本详尽的菜谱、一个智能助手帮他盯火候和调味,他做出来的菜可能不输米其林大厨。框架的力量,在某种程度上可以拉平模型之间的差距。
这对整个行业的格局影响深远:即使你没有全球最顶尖的模型,只要你的 Agent 框架设计得足够好,你依然可以给用户提供非常出色的体验。

三、一个疯狂的命令:对话不超过 100 轮就辞职
罗福莉回到团队后做了一件很猛的事。她要求所有人必须使用 OpenClaw,如果第二天对话次数不超过 100 轮,可以直接辞职。她不会真的去考核,只是想传递一种态度:你不用,你可能真的要落后了。
推动这件事的过程很有意思。一开始她在群里强烈推荐,没有人搭理她,因为大家还在过年。回来之后,真正用的人也很少。大家觉得这东西太玄乎了,不像正经技术。
于是她买了几台 Mac Mini,把 OpenClaw 部署好,拉了几个飞书群,让大家分不同方向在群里公开使用。为什么要在大群里聊?因为个人的想象力是有限的,当你看到别人用这个东西居然能干成那件事,你自己的想象力也会被点燃。大家的想象力是一个乘积作用。
结果团队被彻底点燃了近100个人在飞书群里疯狂探索,10 分钟不看就 999+ 消息。大家玩了两天,发现这东西太好玩了,然后自然而然就进入了研究状态:怎么借助这个框架提升模型能力,同时怎么让模型去改进这个框架。
最终的结果是,他们在三四周内做完了以前三四十周才能做到的研究量。
最有冲击的是大家一块改框架本身。在一个近 100 人的群里,它的 memory 做得非常智能,对每个人画像把控都没有串得太厉害。100 多个人疯狂改它,没有把框架改坏,它还变得更智能。
这是我第一次感受到,怎么用一群人的智慧去提升一个事情。如果我自己单一去改,进步速度非常慢。一群人去改进,几小时就迭代一轮。利用群体智能去提升 Agent 框架非常重要。

四、为什么 Code 能力是 Agent 时代的万能钥匙
罗福莉花了不少篇幅解释为什么 Code(代码)能力在 Agent 时代如此关键。
她的解释很直白。Agent 本质上是一个非常长程、多轮的任务。你很难在互联网上找到 128K 甚至百万 token 长度的高质量数据,但代码天然就是这样的数据。一个大型软件项目的代码文件之间关联紧密,信号密集,在这样的数据上训练,模型对长上下文的建模能力自然就更强。
换句话说,代码能力强的模型,天然就更适合做 Agent。因为 Agent 需要的核心能力——理解超长上下文、进行多步推理、根据环境反馈调整策略——在代码训练中都能得到充分锻炼。
她还提到一个很有意思的观点:代码是拉上限的,训其他领域是保下限的。把代码的长程任务做好了,很多模型的通用特质就已经好了。Agent 框架本身也会跟着迭代得更好。
启示:如果你想判断一个 AI 模型的实际能力,与其看它在各种榜单上的分数,不如看它写代码的水平。代码能力强的模型,大概率在其他复杂任务上也不会差。

五、算力分配的巨变:后训练地位翻天覆地
罗福莉透露了一组很有意思的数据。过去在 Chat 时代,研究、预训练、后训练的算力分配比例大约是 3:5:1。预训练占了绝对大头,后训练只是一个收尾工作。
但现在,合理的比例变成了 3:1:1。预训练和后训练的算力投入已经持平。顶尖团队应该都是 1:1 了。
这个变化本身就说明了范式转移的剧烈程度。以前大家把绝大部分资源砸在预训练上,觉得底子打好了,后面随便调一调就行。现在不一样了,后训练变成了和预训练同等重要的环节,甚至在某些维度上更重要。
因为 Agent 范式下,模型需要学会的东西和 Chat 时代完全不同。它需要理解复杂的 Agent 框架,需要在多轮交互中保持稳定,需要根据环境反馈灵活调整策略。这些能力很难在预训练阶段获得,必须在后训练阶段通过大量的强化学习来培养。

六、MTP vs MLA:一个看似偶然的选择,踩中了时代的节拍
这部分稍微有点技术含量,但罗福莉解释得很清楚。
当时训 MiMo 的时候,业界主流是 MLA(多头潜在注意力),这是 DeepSeek V2、V3、R1 都在用的架构。MLA 在 Chat 时代确实非常优秀,它把计算和访存的比例优化到了一个完美的临界点。
但问题恰恰出在这个"完美"上。因为已经优化到极致了,反而没有留下灵活调整的空间。就像一辆赛车,每个零件都为直线加速设计到了极限,结果到了弯道就转不过来。
MiMo 选择了另一条路:Hybrid Attention 加 MTP(多词元预测)。这个组合当时看起来不那么极致,但它有弹性——长上下文成本低、推理速度快、架构有富余空间可以适配不同场景。
罗福莉坦言,这个选择当时有一定偶然性。他们在设计推理方案时,发现计算资源剩余得太多,就想着用 MTP 把这些富余的算力利用起来。恰好预训练阶段也训了 MTP,就自然而然用上了。
但回头看,这个选择恰好完美适配了 Agent 时代的需求。Agent 需要处理超长上下文,需要快速响应,需要在不同框架下灵活适配。MiMo 的架构天然满足这些要求。
这个故事给人的感触是:在技术路线的选择上,有时候不追求当下的极致,反而给未来留下了更大的空间。过度优化往往意味着过度绑定,而保持一定的弹性和冗余,可能在下一个转折点到来时成为巨大的优势。

七、Skills:人类经验的新载体
罗福莉说,Skills 本质上是一种执行规范。这些规范很难在预训练数据里出现,因为它们通常是企业内部、真实环境中由人与人之间的协作沉淀下来的——比如一个公司的代码规范、一个团队的工作流程、一个行业的最佳实践,这些东西互联网上找不到。
但通过 Skills,人可以把这些经验教给 Agent。大量的 Skills 其实是 Agent 自己写的,但它们的源头是人的智慧和经验。
她把人跟 Agent 交互范式的最大变化总结为:人不再去修改代码,不再说"这一行出错了帮我改一下"。人只会提更高阶的东西——增加限制、澄清需求、架构设计、辅助理解业务逻辑。业务逻辑是模型本身不具备的,因为很多是企业内部真实环境沉淀下来的,你必须跟它很多轮交互才会沉淀下来。这就是 Skills 的价值。
她把 Skills 称为一种"另类信息",类似于量化投资中的"另类数据"。如果没有这些高阶的、另类的信息与 Agent 共创,那么即使是最顶尖模型的能力也很难充分发挥出来。
这意味着在 AI 时代,人的经验和判断力并没有贬值,只是换了一种表达方式。以前你的经验体现在你的工作成果里,现在它可以被沉淀成 Skills,通过 Agent 放大成百倍千倍的效率。那些在某个领域有深厚积累的人,反而可能在 Agent 时代获得更大的杠杆。
八、做个好框架:弥补行动的缺陷
罗福莉对 Agent 框架设计有一个很精辟的定义:一个非常好的框架,应该尽量去弥补行动上的缺陷。
很好的 memory 系统是弥补行动缺陷,接入更广泛的 message channel 是弥补行动缺陷,更主动的定时任务和自更新迭代,都是在弥补行动上的缺陷。大模型是你给它越好的 Context,执行效果越好。你能把这些它获取不到的、行动上的 Context 都给它,它肯定会完成得更好。
还有很关键的一环是评估。现在已有的评估体系都非常简单,只防止不出致命性错误。怎么有更有泛化力的评估体系来促进框架自迭代?现在是把最高阶那群人当评估——你交给它更难、更高价值场景的任务,完成不了就给它补充信息,指出错在哪,push 它经过更多轮交互完成。这个评估会慢慢被框架吸收,也会被模型能力吸收。
Agent 框架跟产品差异蛮大。产品是你直接人交互能感受的那一层东西,Agent 框架同时在定义你怎么跟模型沟通那一层,它甚至知道模型能力的长板短板,知道怎么做调度。这个中间层可以做得非常厚重,前端 UI 展示反而是最薄的一层。
Claude Code 一直是一套很复杂的 Agent 框架,但它是黑盒。OpenClaw 是开源的,你知道它怎么设计的,你可以去改它。改它,是非常非常激发人的创造力的。
九、大模型竞争第二幕:所有人都站在同一起跑线
1T 参数是入场券,这只是起点。罗福莉给出明确判断:1T 参数规模的基座模型,是做到接近 Claude Opus 4.6 水平的入场券。目前国内具备 1T 以上基座的公司有好几家。如果反应速度足够快,距离 Claude Opus 4.6 只有两三个月的代差。
但她同时指出,1T 只是一个起点。如果要拿到下一个阶段的领先,就要寻求更大规模的 scaling。到底是去 scaling 模型的参数量,还是别的什么东西?在什么样的芯片上去 scaling?这些是当下立即需要做出的决策和判断,决定了大半年之后谁更领先。
Anthropic 的路径是正确的,这算是当下共识。国内大模型团队进入加速追赶状态。Pre-train 代差基本没有,国内在 Pre-train 结构上甚至是有优势的。赛点在于:在 Agent 上怎么做好 RL 的 scaling,这是非常清晰和准确的方向。
竞争维度和速度都变多了。预训练不可能一个月出模型,后训练可以。创业公司的团队规模会越来越小——就几个人甚至一个人都可以成为公司,只要你学会充分借助 Agent。
模型借助 Agent 架构本身,就变成一套新的产品。模型即产品变得更突出,产品力反而更强了。
回顾过去三年:23 年是开源界追上闭源模型。24 年发生在意料之外的是 o1 跟 R1。25 年是很交错的一年——你可以选择在 Chat 范式下把 Reasoning 做到极致,也可以选择去拥抱新的 Agent 架构。比较聪明的团队,25 年年中就会全面拥抱 Agent 架构。
十、没有职级、没有小组、没有 Deadline 的组织
最让人意外的,是罗福莉对组织管理的描述。MiMo 团队大约 100 人,但没有职级、没有小组划分、没有 deadline。训练 1T 模型的核心团队只有几个人。她说自己是"1 对 100"的管理方式,但又说不太存在管理,大家一块解决问题就好了。
大多数招的人都没有做过大模型。刚毕业,之前甚至不是做大模型的。大概 1/3 到 1/4 稍微有一点点训练经验,也只训过 7B、14B。不要告诉大家 1、2、3、4 步做什么,就推着大家一起来重新做一遍,大家就会往前走。
她的管理哲学可以概括为几个关键词:热爱驱动、平权创新、环境优先。
她说靠热爱驱动管理是最行之有效的方式。选择激发大家的热情,让大家围绕自己愿意信仰的事情去自驱做事。平权本身有价值,有利于所有人平等地贡献自己的创造力和智慧。任何层级一定程度上都是在规范和约束,而规范和约束本身是压制创造力的。
环境比经验更重要。团队成员之间像"互相蒸馏"一样快速成长——你蒸馏我的长处,我蒸馏你的长处,互相快速提升。她甚至开始倾向于招大二大三的本科生,因为他们对新范式的想象力更高,灵活性没有被污染。
训 1T 模型的过程中,遇到 loss spike(训练不稳定),她会选择停下来排查问题,哪怕停一两周。几千张卡停一天就是一两百万的成本,但她说不焦虑,因为我们又没有什么目标。当然,晚上还是会做梦梦到 loss 又 spike 了。

十一、最残酷的判断:AI 训练 AI
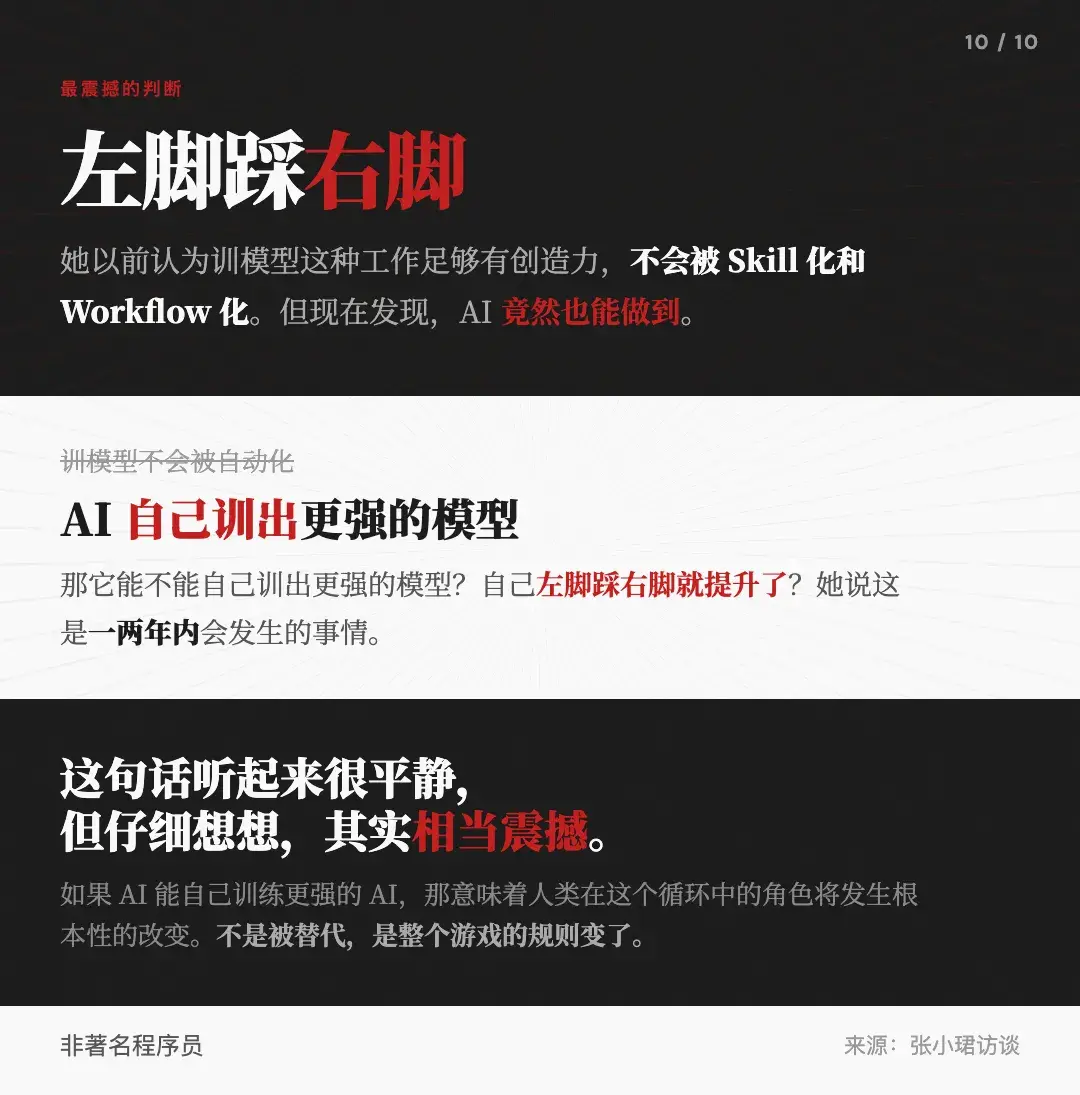
访谈中最让人心里一沉的,是罗福莉说的这段话:她以前认为训模型这种工作已经足够有创造力,足够不会被 Skill 化。但她现在发现,AI 竟然也能做到。那它可不可以训出更强的模型?自己左脚踩右脚就提升了?
她说这是一两年内会发生的事情。它先吸收所有人的智能,再靠自己产生更强的智能。
如果连训练 AI 模型这种最前沿的研究工作都可以被 AI 自己完成,那还有什么工作是绝对安全的?
但从另一个角度,她从提升顶尖模型能力的角度来看,让 Agent 替代更高价值的任务是重要的——更高价值意味着更长 Context、更多 token 消耗量,替代到最顶尖那一群人的智能就够了。
十二、两年内实现 AGI
罗福莉对 AGI 的时间表相当乐观。她认为目前已经走到 20%,今年年底能到 60% 到 70%,两年内应该能实现。
但她做了一个很重要的区分:AI 会先颠覆工作模式,然后才是生活模式。后者需要等机器人技术跟上。机器人本身瓶颈可能在硬件和电池上,比 Agent 在语言空间的进化要慢。
今年的主旋律是生产力的变革,高生产力场景的持续突破。更长程的任务、更强调多 Agent 之间的协作,这些是 2026 年的核心叙事。端侧小模型趋势会发生,但不是 26 年主旋律,是支线。
关于隐私,她的思路是端云混合——简单的、涉及隐私的任务放在本地用小模型跑,复杂的、高创造力的任务上云端用大模型。这也是为什么她认为开源如此重要,因为这件事需要更多人一块做,不是某个公司能独自完成的。
开源是加速 AGI 的。假设 AGI 爆发替代绝大部分生产力,芯片会分散,推理有不同厂商做,模型一定是不一样的。从终局倒推,开源有利于推进这个事。开源对 Agent 框架、芯片、能源都有促进。
国内有 1T 以上基座的公司有好几家,按照目前前沿研究、模型水平、AGI 框架、芯片能源多方面合起来,中国非常可能领先。

写在最后:天真乐观的勇气
罗福莉的工作状态是早上 11 点到晚上 12、3、4 点。睡眠不需要太多,5、6 个小时足够。现在做的事有点兴奋,睡太多有点浪费时间。压力缓解靠脑子是 Sliding Window Attention,忘得非常快——前提是第二天有新的、有想象力的事情冲掉它。
如果 AGI 实现,她可能会搞一个公益型组织,支撑做基础研究的人往更突破方向走。她始终觉得应该加速科学研究,哪怕 AGI 实现也有很多要做的。纯享受生活也挺无聊的。无聊对她来说不是一种意义。
现在觉得把当下的每天的研究都做好,就觉得非常好。
被问到有什么话想对 10 年后的自己说,她回答:未来很美好。然后补了一句:我觉得,这是一种天真乐观的勇气。
参考资料:张小珺《独家对话罗福莉:AI范式已然巨变!》/"非著名程序员"知乎专栏《从DeepSeek到小米,天才少女罗福莉的首次访谈,信息量巨大》