RAG和SQL,我全都要!实战教程:构建能自主决策的混合查询Agent
你有没有遇到过这样的困境:用户问你一个问题,你得先判断是该去文档库里翻翻,还是该查查数据库?更头疼的是,如果判断错了,给出的答案要么不准确,要么干脆答非所问。
今天我想和你聊聊一个实战项目——RAG-SQL Router。这不是什么高深莫测的理论,而是一个能真正解决问题的智能系统。更重要的是,我会把完整的实现思路和代码都分享给你,让你也能动手搭建一个。
一、为什么需要这样一个系统?
先说说实际场景。假设你在做一个企业内部的智能问答助手:
场景1:非结构化数据查询
"公司最新的休假政策是什么?"
"产品功能文档里关于API鉴权的部分怎么说的?"
这类问题的答案藏在PDF、Word文档、Wiki页面里——典型的非结构化数据,最适合用RAG(检索增强生成)来处理。
场景2:结构化数据查询
"去年第四季度销售额最高的三个地区是哪些?"
"目前有多少活跃用户?"
这些问题需要的是精确的数字,答案在数据库里——需要Text-to-SQL来解决。
问题来了:当用户随便问一个问题,系统怎么知道该用哪种方式回答?
这就是RAG-SQL Router要解决的核心问题:让AI自己判断该走哪条路。
二、系统架构:Agent如何做决策?
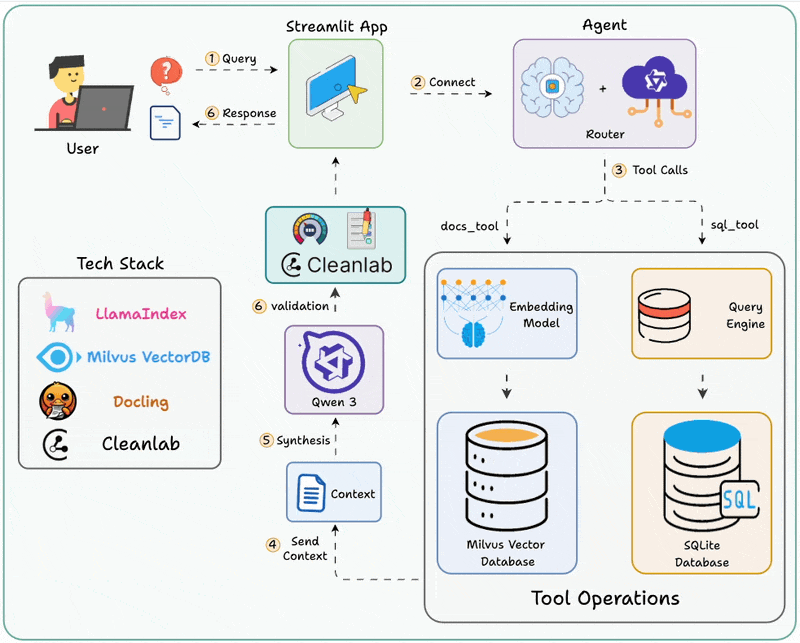
整个系统的核心是一个路由Agent,它的工作流程是这样的:
智能体根据用户问题分析意图后,自主选择文档检索或数据库查询工具来获取信息并返回结果。
关键组件解析
Router Agent(路由智能体)
这是整个系统的大脑。它基于LlamaIndex的Workflow框架构建,能够:
理解用户问题的语义
判断问题类型(文档检索还是数据查询)
选择合适的工具
甚至可以同时调用多个工具
RAG工具(向量检索引擎)
负责处理非结构化数据:
使用LlamaCloud作为向量数据库
支持PDF、Word等文档格式
通过语义相似度检索相关内容
SQL工具(自然语言转SQL引擎)
负责处理结构化数据:
将自然语言转换为SQL查询
执行数据库查询
返回结构化结果
Cleanlab Codex(质量保障层)
这是个亮点!很多人做Agent,但没人关心输出是否靠谱。Cleanlab Codex提供:
自动检测不准确或无用的回答
为每个回答提供可信度评分
实时验证查询和响应
允许专家直接改进回答,无需改代码
三、动手实现:完整代码解析
让我带你一步步搭建这个系统。我会用最实际的代码,而不是空谈理论。
第一步:环境准备
# 创建项目目录mkdir rag-sql-routercd rag-sql-router# 创建虚拟环境python -m venv venvsource venv/bin/activate # Windows用: venv\Scripts\activate# 安装依赖pip install llama-index llama-index-llms-openai \ llama-index-embeddings-openai \ llama-index-indices-managed-llama-cloud \ sqlalchemy streamlit nest-asyncio
第二步:配置API密钥
创建 .env 文件:
OPENAI_API_KEY=your_openai_keyLLAMA_CLOUD_API_KEY=your_llamacloud_keyLLAMA_CLOUD_ORG_ID=your_org_idLLAMA_CLOUD_PROJECT_NAME=your_projectLLAMA_CLOUD_INDEX_NAME=your_index
第三步:搭建SQL查询引擎
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, insertfrom llama_index.core.query_engine import NLSQLTableQueryEnginefrom llama_index.core import SQLDatabase# 创建示例数据库engine = create_engine("sqlite:///:memory:")metadata = MetaData()# 定义城市统计表city_stats = Table( 'city_stats', metadata, Column('city', String, primary_key=True), Column('population', Integer), Column('country', String),)metadata.create_all(engine)# 插入示例数据rows = [ {"city": "Toronto", "population": 2930000, "country": "Canada"}, {"city": "Tokyo", "population": 13960000, "country": "Japan"}, {"city": "Berlin", "population": 3645000, "country": "Germany"},]with engine.connect() as conn: for row in rows: conn.execute(insert(city_stats).values(**row)) conn.commit()# 创建SQL数据库对象sql_database = SQLDatabase(engine, include_tables=["city_stats"])# 创建自然语言SQL查询引擎sql_query_engine = NLSQLTableQueryEngine( sql_database=sql_database, tables=["city_stats"],)
这段代码做了什么?
创建了一个内存SQLite数据库(适合演示,生产环境换成MySQL/PostgreSQL)
定义了城市统计表,包含城市名、人口、国家字段
插入了一些示例数据
用NLSQLTableQueryEngine包装数据库,它能把"人口最多的城市"这样的问题转成SQL
第四步:搭建RAG检索引擎
from llama_index.indices.managed.llama_cloud import LlamaCloudIndeximport os# 连接到LlamaCloud索引rag_index = LlamaCloudIndex( name=os.getenv("LLAMA_CLOUD_INDEX_NAME"), project_name=os.getenv("LLAMA_CLOUD_PROJECT_NAME"), organization_id=os.getenv("LLAMA_CLOUD_ORG_ID"), api_key=os.getenv("LLAMA_CLOUD_API_KEY"),)# 创建查询引擎rag_query_engine = rag_index.as_query_engine()
LlamaCloud是什么?
简单说,它是一个托管的向量数据库服务:
你上传文档(PDF、DOCX等)
它自动切分、向量化、建索引
你只需要调用API查询
当然,你也可以用Qdrant、Pinecone、Weaviate等替代。
第五步:将查询引擎包装成工具
from llama_index.core.tools import QueryEngineTool# SQL工具sql_tool = QueryEngineTool.from_defaults( query_engine=sql_query_engine, name="sql_query_engine", description=( "用于查询城市统计数据,包括人口、国家等信息。" "适合回答关于数字、排名、统计类的问题。" ),)# RAG工具rag_tool = QueryEngineTool.from_defaults( query_engine=rag_query_engine, name="document_search_engine", description=( "用于搜索文档内容,适合回答关于政策、流程、" "说明等需要从文档中查找信息的问题。" ),)
为什么要包装成工具?
这里的description非常关键!Agent会读这些描述来判断该用哪个工具。所以描述要:
清晰明确:说清楚工具能做什么
区分明显:让Agent能轻松分辨使用场景
举例说明:提示适用的问题类型
第六步:构建Router Workflow
这是整个系统最核心的部分:
from llama_index.core.workflow import ( Event, StartEvent, StopEvent, Workflow, step,)from llama_index.llms.openai import OpenAIfrom typing import List, Any# 定义事件类型class PrepEvent(Event): """准备阶段完成事件""" passclass ToolCallEvent(Event): """工具调用事件""" tool_calls: List[Any]# 定义Router Workflowclass RouterWorkflow(Workflow): def __init__(self, tools: List[QueryEngineTool], **kwargs): super().__init__(**kwargs) self.tools = {tool.metadata.name: tool for tool in tools} self.llm = OpenAI(model="gpt-4") @step async def prepare_chat(self, ev: StartEvent) -> PrepEvent: """准备对话消息""" # 获取用户查询 user_msg = ev.query # 构建系统提示 system_prompt = self._build_system_prompt() # 存储到上下文 self.query = user_msg self.messages = [ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_msg} ] return PrepEvent() @step async def handle_llm_call(self, ev: PrepEvent) -> ToolCallEvent | StopEvent: """调用LLM决策""" # 准备工具定义给LLM tools_def = [ { "type": "function", "function": { "name": name, "description": tool.metadata.description, "parameters": { "type": "object", "properties": { "query": { "type": "string", "description": "用户查询" } }, "required": ["query"] } } } for name, tool in self.tools.items() ] # 调用LLM response = await self.llm.achat( messages=self.messages, tools=tools_def ) # 检查是否有工具调用 if response.message.tool_calls: return ToolCallEvent(tool_calls=response.message.tool_calls) else: # 没有工具调用,直接返回答案 return StopEvent(result=response.message.content) @step async def handle_tool_calls(self, ev: ToolCallEvent) -> StopEvent: """执行工具调用""" results = [] for tool_call in ev.tool_calls: tool_name = tool_call.function.name tool_args = eval(tool_call.function.arguments) # 执行工具 tool = self.tools[tool_name] result = await tool.aquery(tool_args["query"]) results.append({ "tool": tool_name, "result": str(result) }) # 组合结果 final_answer = self._combine_results(results) return StopEvent(result=final_answer) def _build_system_prompt(self) -> str: """构建系统提示""" return """你是一个智能助手,能够访问以下工具:1. SQL查询引擎:用于查询结构化数据2. 文档搜索引擎:用于搜索文档内容根据用户问题,选择合适的工具。如果需要,可以同时使用多个工具。""" def _combine_results(self, results: List[dict]) -> str: """组合多个工具的结果""" if len(results) == 1: return results[0]["result"] combined = "根据查询结果:\n\n" for i, res in enumerate(results, 1): combined += f"{i}. 从{res['tool']}得到: {res['result']}\n" return combined
这个Workflow是怎么工作的?
prepare_chat: 接收用户问题,准备系统提示和对话消息
handle_llm_call: 调用LLM,让它决定用哪个工具(或多个工具)
handle_tool_calls: 实际执行工具调用,获取结果
如果有多个结果,组合起来返回
关键点在于:
第七步:创建Streamlit界面
import streamlit as stimport asyncio# 页面配置st.set_page_config(page_title="RAG-SQL Router", page_icon="🤖")st.title(" 智能路由问答系统")st.markdown("**问我任何问题,我会自动选择最佳方式回答!**")# 初始化工具和workflowif "workflow" not in st.session_state: # 创建工具 tools = [sql_tool, rag_tool] # 初始化workflow st.session_state.workflow = RouterWorkflow( tools=tools, timeout=60.0 )# 聊天历史if "messages" not in st.session_state: st.session_state.messages = []# 显示历史消息for message in st.session_state.messages: with st.chat_message(message["role"]): st.markdown(message["content"])# 用户输入if prompt := st.chat_input("在这里输入你的问题..."): # 显示用户消息 st.session_state.messages.append({"role": "user", "content": prompt}) with st.chat_message("user"): st.markdown(prompt) # 调用workflow获取答案 with st.chat_message("assistant"): with st.spinner("思考中..."): # 运行workflow result = asyncio.run( st.session_state.workflow.run(query=prompt) ) # 显示答案 st.markdown(result) # 保存助手回答 st.session_state.messages.append({"role": "assistant", "content": result})# 侧边栏:显示可用工具with st.sidebar: st.subheader("🔧 可用工具") st.write("1. SQL查询引擎") st.caption("查询城市统计数据") st.write("2. 文档搜索引擎") st.caption("搜索文档内容") if st.button("清空对话"): st.session_state.messages = [] st.rerun()
第八步:运行系统
打开浏览器,访问 http://localhost:8501,试试这些问题:
SQL类问题:
RAG类问题:
"文档里提到的政策要点是什么?"
"关于API使用的说明在哪里?"
混合问题:
四、加入Cleanlab Codex:让输出更可靠
前面的系统已经能工作了,但有个问题:怎么知道AI的回答靠不靠谱?
这就是Cleanlab Codex的价值。它能:
自动检测问题回答
提供可信度评分
支持专家反馈
集成代码示例:
from cleanlab_codex import CleanlabCodex# 初始化Codexcodex = CleanlabCodex(api_key=os.getenv("CLEANLAB_API_KEY"))# 在workflow中使用@stepasync def validate_response(self, ev: StopEvent) -> StopEvent: """验证响应质量""" # 获取原始回答 response = ev.result # 验证质量 validation = codex.validate( query=self.query, response=response, context=self.retrieved_context ) # 添加可信度评分 confidence = validation.trustworthiness_score if confidence < 0.7: response += f"\n\n 可信度: {confidence:.2%} (建议人工确认)" else: response += f"\n\n 可信度: {confidence:.2%}" return StopEvent(result=response)
五、实际应用场景
这套系统不是玩具,我们来看看能解决什么实际问题:
场景1:企业知识库
问题: 公司有大量文档(员工手册、产品文档、流程规范)和业务数据(销售、用户、财务)。员工经常不知道去哪找信息。
解决方案:
RAG工具索引所有文档
SQL工具连接业务数据库
员工直接问问题,系统自动路由
效果:
减少80%的重复咨询
提升员工自助查询效率
数据和文档统一入口
场景2:客户服务系统
问题: 客服需要回答产品使用问题(文档)和订单状态(数据库)。
解决方案:
RAG工具索引产品文档、FAQ
SQL工具连接订单系统
客服输入问题,系统提供参考答案
效果:
场景3:数据分析助手
问题: 业务人员不会写SQL,但需要经常查数据。
解决方案:
SQL工具连接数据仓库
RAG工具提供分析方法论文档
自然语言查询,自动生成SQL
效果:
降低对数据团队的依赖
提升数据驱动决策效率
减少重复分析工作
六、关键经验和坑
搭建这个系统时,我踩过不少坑,分享几个关键经验:
1. 工具描述要精准
坑: 最开始我的SQL工具描述是"用于查询数据"——太模糊了!结果Agent经常选错。
解决: 改成"用于查询城市统计数据,包括人口、国家等信息。适合回答关于数字、排名、统计类的问题。"——具体、清晰、有例子。
2. 处理好并发调用
坑: 用户问"东京人口多少?文档里怎么说的?"——需要同时调用两个工具,但结果怎么组合?
解决:
Workflow支持并发step
在_combine_results里做好结果聚合
让LLM再做一次总结
3. 数据库连接要健壮
坑: SQLite内存数据库重启就没了,生产环境不能用。
解决:
# 生产环境用持久化数据库engine = create_engine( "postgresql://user:pass@host:5432/db", pool_pre_ping=True, # 检查连接有效性 pool_size=10, # 连接池)
4. Token消耗要控制
坑: 每次查询都把全部上下文传给LLM,token消耗巨大。
解决:
5. 错误处理要完善
坑: SQL语法错误、网络超时、API限流都会导致系统崩溃。
解决:
try: result = await tool.aquery(query)except SQLAlchemyError as e: result = f"数据库查询失败: {str(e)}"except TimeoutError: result = "查询超时,请稍后重试"except Exception as e: result = f"系统错误: {str(e)}" # 记录日志 logger.error(f"Tool error: {e}", exc_info=True)
七、性能优化建议
如果你要把这套系统用到生产环境,这些优化必不可少:
1. 缓存机制
from functools import lru_cacheimport hashlib@lru_cache(maxsize=1000)def cached_query(query_hash: str): """缓存查询结果""" # 实际查询逻辑 pass# 使用时query_hash = hashlib.md5(query.encode()).hexdigest()result = cached_query(query_hash)
2. 批量查询
对于相似查询,批量处理:
async def batch_query(queries: List[str]): """批量执行查询""" tasks = [workflow.run(query=q) for q in queries] return await asyncio.gather(*tasks)
3. 监控和日志
import loggingfrom datetime import datetimelogging.basicConfig( level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('rag_sql_router.log'), logging.StreamHandler() ])logger = logging.getLogger(__name__)# 在关键位置记录logger.info(f"Query received: {query}")logger.info(f"Tool selected: {tool_name}")logger.info(f"Response time: {elapsed:.2f}s")
4. 限流保护
from functools import wrapsimport timedef rate_limit(max_calls: int, time_window: int): """限流装饰器""" calls = [] def decorator(func): @wraps(func) async def wrapper(*args, **kwargs): now = time.time() # 清理过期记录 calls[:] = [c for c in calls if c > now - time_window] if len(calls) >= max_calls: raise Exception("请求过于频繁,请稍后再试") calls.append(now) return await func(*args, **kwargs) return wrapper return decorator@rate_limit(max_calls=10, time_window=60)async def handle_query(query: str): """处理查询,每分钟最多10次""" pass
八、总结
看到这里,你大概已经能感受到:RAG-SQL Router 这东西看起来像“多加了一个路由层”,但真正解决的是落地时最容易被忽视的一件事——把“该去哪儿找答案”这一步交给系统,而不是交给用户。
很多企业内部问答做不起来,并不是因为模型不够强,而是因为入口不够统一:同一句话问出来,有时候是制度条款,有时候是数据口径,有时候还夹杂着流程步骤。人能凭经验判断“先查文档还是先查库”,但系统如果没有这个判断能力,就会变成两种尴尬:
Router 的价值,就是让这两套能力不再互相拖后腿,而是互相补位:需要确定性的时候走SQL,需要背景解释的时候走RAG,复杂一点的问题就两条路一起跑,最后再把结果合到一张桌子上给你。
4个“神器”把Claude Code Skills用到飞起(并附通义灵码Lingma替代玩法)
你是不是也这样?每次想让AI帮你处理PDF、写个报表,都得重新写一遍Prompt。说了一堆要求,结果它还是没按你的意思来。
卡住了?
别急,问题不在你,也不在AI。真正的问题是:你在重复劳动,而不是提效。
今天我要告诉你一个真相——Skill 是资产,Prompt 是消耗品。
你每写一次Prompt,就像烧掉一张钞票;而你建一个Skill,就像存下一笔钱。前者花完就没了,后者能一直生利息。
那怎么才能快速搞到这些“技能资产”?我给你扒出4个真正好用的神器,让你从“找-装-用-建”一口气闭环。
一、神器一:skills.sh —— Skill 的“应用商店”
你有没有想过,其实已经有成千上万个现成的Skill,早就被人做好了?
比如一键提取发票表格、批量生成PPT、自动写单元测试……这些不是幻想,而是真实存在的Skill。
它们在哪?就在 skills.sh。https://skills.sh/
这玩意儿就像是AI Agent时代的App Store,由Vercel团队维护,收录了超过2800个高质量Skill。而且不只是Claude Code能用,Cursor、OpenCode这些主流工具也都兼容。
最夸张的是,光是前100个热门Skill,总安装量就超过了500万次。
所以呢? 这意味着你根本不用自己造轮子。90%的常见任务,别人已经替你跑通了。
打开终端,直接去逛店就行。
二、神器二:4 个核心命令 —— 像装 npm 包一样管理 Skill
你说:“道理我都懂,可怎么装啊?”
简单。就跟装npm包一样,一行命令搞定。
npx skills add vercel-labs/agent-skills
就这么一句话,一个前端开发全家桶Skill就装上了。
但别只会这一招,真正高效的玩家都掌握这4个命令:
装:npx skills add <skill> —— 想要啥,直接加
更:npx skills update —— 所有Skill一键更新
搜:npx skills find <关键词> —— 本地搜索已装的Skill
建:npx skills init —— 初始化自己的Skill项目
说实话,我自己一开始也是手动建文件夹,后来发现完全没必要。这些命令才是现代AI工作流的标配。
那问题来了:如果我不知道该装哪个呢?
三、神器三:find-skills —— 用“人话”搜索,不知道名字也能找到
你肯定遇到过这种情况:你知道自己想要什么,但就是说不清那个Skill叫啥名。
比如你想“把日志转成可视化图表”,但你不知道有没有对应的Skill,也不知道去哪里找。
这时候,find-skills 就是你最好的朋友。
先装上它:
npx skills add vercel-labs/skills --skill find-skills
然后你就可以直接对AI说:
“帮我搜索一个数据分析的skill”
或者:
“有没有skill能帮我写unit test?”
它会立刻调用 npx skills find data analysis,返回一堆匹配结果,甚至还能一键安装。
有一次我试的时候,随口说了句“找个做PPT的skill”,它当场就推荐了三个,还告诉我哪个下载最多。
所以呢? 这意味着你再也不用翻GitHub、查文档、记链接了。只要你会说话,就能找到你要的工具。
四、神器四:skill-creator —— 零代码造专属 Skill,找不到就自己造
但总有那么些需求,全网都搜不到现成的Skill。
比如你要对接公司内部API,或者按你们团队的规范生成代码模板。
这时候怎么办?自己造。
别怕,不是让你写代码。skill-creator 就是干这个的。
它的安装命令是:
npx skills add anthropics/skills --skill skill-creator
注意,这里拼写是 anthropics(复数),不是 anthropic。
装好之后,你只需要跟AI说:
“帮我创建一个Skill,能把PDF转成PPT”
它就会开始问你:
这个Skill叫什么名字?
是个人用还是团队共享?
要不要加水印?要不要统一字体?
问完一轮,它自动生成整个Skill文件夹,连脚本都给你写好了。
有一次我让它打包一个ImageMagick图片处理工具,几分钟后,我就有了一个能批量压缩、裁剪、格式转换的Skill。
所以呢? 这意味着你不再是AI的“打字员”,而是成了它的“产品经理”。你负责定义需求,它负责实现。
五、一套最省心的 Skill 工作流(四步闭环)
现在,我把这四个神器串起来,给你一套完整的操作流程:
第一步:先去 skills.sh 逛一圈,看看有没有现成的 (90%的需求,到这里就解决了)
第二步:实在找不到,就用 find-skills 直接说人话搜 (剩下9%的需求,靠这一招拿下)
第三步:还没有?那就用 skill-creator 对话式创建 (最后1%,自己动手,丰衣足食)
日常维护:每周运行一次 npx skills update,保持所有Skill最新
这套流程跑通一次,后续全是复利。
更重要的是,你可以把这套东西分享给同事。一个人建,全组用。这才是真正的团队提效。
六、Skill 是资产,Prompt 是消耗品
我们再来对比一下:
你每天写的日报、做的数据清洗、写的代码模板,都是高频重复任务。把这些全都Skill化,你就等于给自己造了一支AI小分队。
它们不会离职,不会摸鱼,也不会忘记你的要求。
所以呢? 别再把时间浪费在重复描述上了。把你最常用的3个任务,今天就变成Skill。
七、通义灵码(Lingma)替代玩法:同样的“找-装-用-建”闭环
你说:“我是用通义灵码的,这些不适用吧?”
错。Lingma 同样支持Skill化工作流,只是机制不同。最简单的方法就是对话窗口输入要安装的skills。
先会使用再懂原理也不迟。
它的Skill是基于文件的(File-based Skills),放在 .lingma/skills 目录里就行。
你可以选择两种路径:
放进去之后,重启IDE或Reload Window,再输入 / 查看列表,就能看到你的Skill了。
所以呢? 这意味着你可以在团队项目里统一标准。比如把《代码提交规范》做成一个Skill,新人一拉代码就能用。
八、Lingma 自建私有 Skill 流程
想把公司规范、私有 API、常用模板封装进去,Lingma 这条路反而很顺:就是建文件夹 + 写 SKILL.md。
这些都是让AI自动完成的,你只要给AI下达指令即可。下面这些步骤都是AI自己完成的。
创建一个命名清晰的文件夹,比如 my-company-api-standard
写一个 SKILL.md,包含:
名称
描述
能力说明
触发指令(比如“请按公司API规范生成接口”)
可选:加个 template.java 或 rules.json,在文档里引用就行
测试时,用典型提问验证输出是否符合预期
比如我们做过一个“统一包装Result”的Skill,只要AI生成接口代码,就会自动加上 Result.success(data),不会再漏。
九、Lingma 使用小贴士
我知道你肯定会遇到这些问题:
还有个变通法:写个脚本,自动把Skill下载到 ~/.lingma/skills,再重启IDE,实现“一键安装”。
团队协作建议:优先用项目级路径,提交到仓库,所有人同步更新。
十、总结
看到这儿,你应该明白了:
真正的提效,不是写更多Prompt,而是把经验沉淀为Skill。
AI时代的核心竞争力,是把重复劳动变成数字资产的能力。
所以,我建议你:
立即行动:今天就装上 find-skills 和 skill-creator
实践建议:选一个你最烦的重复任务,比如写周报、整理会议纪要,把它变成Skill
团队升级:Lingma用户赶紧把 .lingma/skills 提交到项目仓库,共建标准化工作流
你会发现,当你第一次看到AI自动执行你定义的流程时,那种感觉——
真的很爽。
拥有一台“完整电脑”的 AI:OpenClaw 如何重新定义下一代“数字员工”?
很多人第一次用 Agent 都会兴奋一阵:它能写方案、能列清单、能把你没想清楚的地方“补齐”。但用着用着,落差就来了——它会给建议,却不替你把事做完;
它能把流程讲得头头是道,却不会真的去系统里点、去网站里查、去表格里填;
更要命的是,它“做过就忘”:下次遇到同样的问题,你还得从头再说一遍;
它还必须等你来触发,不能像一个同事那样,到了点自己开工、出了异常自己上报。
于是你会发现:很多所谓的 Agent,本质上仍像“高级聊天”。
问题来了:你真正想要的是一个“能聊的助手”,还是一个“能交付的数字员工”?
我越来越确定的一句话是——真正的分水岭,不是更聪明,而是能不能在真实电脑环境里长期做事。
这也是我想聊“龙虾”(OpenClaw)的原因。
一、为什么很多 Agent 体验仍像“高级聊天”
先把常见的落差摊开讲透:
会给策略建议,但无法落地执行:你问“怎么做增长”,它给你 10 条方法;你问“把这 10 条落到飞书任务里并排期”,它就开始含糊。
做过就忘,经验无法复用:今天帮你写了客服话术,明天同样的问题又要再解释一遍背景。
必须人来点一下才动:它没有“工作节奏”,更没有“值班机制”,无法持续跑。
你会发现,这类产品的核心能力在“输出”,而不是“交付”。而交付意味着:在你的真实工作环境里,把结果做出来,并且可验证、可追溯、可复用。
二、什么是“龙虾”(OpenClaw)
一句话定义:OpenClaw 不是聊天窗口里的助手,而是“拥有一台完整电脑、能长期执行任务的 Agent”。
如果用三种形态对比,会更直观(建议你把这张表收藏起来):
形态 | 能力边界 | 记忆方式 | 技能来源 | 运行方式 | 典型体验 |
|---|
Chatbot | 主要输出文本建议 | 基本无长期记忆 | 固定(靠模型) | 被动响应 | “我给你建议,你自己去做” |
普通 Agent | 能调用工具,但常在沙箱 | 依赖对话上下文 | 半固定(预置工具链) | 通常需人工触发 | “我能帮你做一点,但经常卡边界” |
龙虾(OpenClaw) | OS 级执行:像人一样用电脑 | 文件持久化 | 可扩展、可手册化沉淀 | Cron 7x24 自动化 | “我在后台把事做完,并把经验写下来” |
你会发现,“龙虾”这个比喻挺贴切:不是嘴更甜,而是爪子更能干活——能抓取、能搬运、能反复做,而且越做越熟练。
三、四大支柱:决定“能不能交付”
把 OpenClaw 的差异拆开看,本质是四个支柱:环境、记忆、技能、自动化。
3.1 环境(Environment):从“给建议”到“进现场干活”
很多 Agent 最大的问题是“不在现场”。它知道怎么做,但它不在你的电脑里,就无法完成闭环。
OpenClaw 的关键是具备真实 OS 能力,比如:
当 Agent 真的“拥有一台完整电脑”,能做的事就变了:不再停在建议层面,而是能产出可验证结果——一个文件、一条数据更新、一份报表、一次成功的发布记录。
3.2 记忆(Memory):用文件把经验固化下来
仅靠对话窗口的“上下文”,记忆是脆弱的:窗口一关就散、信息一多就挤、协作也难审计。
更稳的方法其实很朴素:把关键信息写进磁盘。
例如用 MEMORY.md、TODO.md、RUNBOOK.md 之类的文件,把这些东西固定下来:
项目背景、目标、边界条件
已验证可行的做法、踩过的坑
关键账号/链接/路径(可控范围内)
每次执行的输出物和校验方式
我很认可一个原则:用过但没记录 = 等于没用过。
因为没沉淀,就谈不上复用、传承与审计,更谈不上“数字员工”。
3.3 技能(Skills):Skill 的本质是“操作手册”
很多人一提 Skill,会以为是“插件”或“函数”。但在 OpenClaw 这类体系里,Skill 更像是:
Skill = Operation Manual(操作手册)。
它把“怎么做”变成可重复执行的步骤:
遇到异常怎么办、如何回滚、如何验收、边界条件是什么。
真正的飞轮是这样的:
遇到问题 → 解决问题 → 把过程写成手册 → 下次直接按手册执行 → 越用越熟练
这会形成一种特别重要的资产:私有智慧。它不靠“模型灵光一现”,而靠“把灵光写成流程”。
3.4 自动化(Automation/Cron):从“临时任务”到“常态运行”
如果没有调度机制,Agent 永远像“临时工”:你叫一次它动一次。
Cron/调度的意义在于,把高频、规律、需要持续盯的工作,从“人肉提醒”升级为“系统生物钟”:
每天早上自动生成日报
每 30 分钟巡检关键数据/告警
定时抓取竞品动态/行业信息
社区自动回复 + 汇总高频问题
发现异常自动开工单、发消息、留证据
这才叫 7x24 无人值守交付:不是更会说,而是到点就干、出事就报、干完有结果。
四、OpenClaw 怎么搭起来:一个能自我强化的闭环
如果你把 OpenClaw 当成系统来看,它不是“一个大模型 + 几个工具”,而是一个闭环架构。
4.1 多通道接入:让它出现在你的工作流里
真正好用的 Agent,一定在你常用的地方出现:
飞书(Feishu)/ Telegram / Discord……你在群里 @它,它在后台“操作电脑”完成任务,然后把结果回传。
好处是:它不是一个孤岛应用,而是嵌进团队协作链条。
4.2 核心组件全景:大脑、记忆、手脚、生物钟
4.3 “完整电脑”带来的闭环价值
一旦能在真实电脑环境里做事,闭环就成立了:
发现问题 → 执行操作 → 记录沉淀 → 下次复用
这意味着 Agent 的价值从“一次性聪明”变成“长期可交付”,而长期可交付会带来复利。
五、组织化协作:一群 Agent 如何像团队一样运转(Agent Roles)
当 Agent 能长期做事之后,下一个升级不是“让它更强”,而是“让它分工”。
从“一个助手”,升级为“可调度的组织系统”。
你可以想象一个最小的 Agent 小队排班表(示例):
Commander(总指挥):每小时统筹推进,拆解/分配任务,检查进度
Advisor(参谋):每小时提供策略建议与风险提示
Community(社区官):每 30 分钟互动、收集反馈、汇总问题
Writer(笔杆子):每 2 小时产出内容初稿/标题/配图清单
Ops(运营官):每 6 小时巡检数据、流程优化、异常归因
这样做的优势很现实:
六、核心认知升级:Agent 是新一代软件(卖结果,不卖工具)
传统软件卖的是工具:给你功能,你自己点;给你面板,你自己配;给你流程,你自己跑。
Agent 时代更像卖结果:你把目标交给它,它在你的工作环境里把结果交回来。
这也解释了另一个关键壁垒:Skills(经验)比模型更重要。
把失败和修正写进流程,才能形成长期复利与护城河。Agent 越跑越像“老员工”,靠的就是这套沉淀。
七、为什么 OpenClaw 更像 Tool AGI
如果用一个更宏观的词来概括,我会把它称为 Tool AGI:
不一定像人一样思考,但能在工具世界里完成复杂目标。
它的能力跃迁来自“组合”,而不是单点模型能力:
电脑环境 + 记忆 + 技能 + 自动化
落到场景上,会非常具体:
个人:超级助理 / 第二大脑 / 自动化生活与工作
团队:运营自动化、内容生产、客服/社区、数据巡检与告警
组织:流程再造,“数字员工”编制化,把重复性岗位先软件化再智能化
八、总结
OpenClaw 的关键从来不是“更会聊天”。
它真正代表下一代 Agent 的地方在于:能在真实电脑环境里长期做事,并把经验沉淀成可复用资产。
当 Agent 具备了“电脑、记忆、技能、作息”,它就不再是一个聊天框,而更像一个数字同事:能交付、能复盘、能成长,也能被组织化调度。
这才是分水岭。
OpenClaw 成本高?那是你没用路由!实测:一句话配置,立省 80% Token
你在用 OpenClaw(或者任何 AI Agent 框架)的时候,默认所有的 prompt 都发给同一个模型。
但仔细想想,这合理吗?难怪费用高。
"帮我写一段处理并发的 Python 代码"——这需要强推理能力,值得用 Claude Opus。
"今天天气怎么样"——这就是个闲聊,用最便宜的模型绰绰有余。
你当然知道这个区别,但你没有时间给每一个 prompt 手动判断该用哪个模型。于是要么全用贵的,要么全用便宜的,两条路都是死路。
真正的解法是:在你的应用和模型之间加一层路由。
一、什么是 LLM 路由
LLM 路由(LLM Router)可以理解成一层中间件:夹在你的应用和各家模型 API 之间。
每个 prompt 进来,它先读内容,判断这是哪种任务,然后把请求转发给最合适的模型。对上层业务代码来说几乎是透明的:你照常“发请求”,路由器在背后做决定。
听上去很直觉,但真正难点在于:它凭什么知道“哪个模型更合适”?
很多路由方案的思路是看 Benchmark:coding 得分高就接代码任务,数学得分高就接推理任务。问题在于,Benchmark 反映的是“模型有多强”,但你真正需要的是“你更愿意把哪类任务交给谁”。这两件事并不等价。
工程里最常见的情况是:模型 A 在榜单上更强,但你更喜欢用模型 B 处理对话式的 Agent 流程;或者某个模型在综合能力上没那么极致,但在“成本/速度/稳定性”组合上更适合作为默认入口。
路由应该服务的是“你的偏好”,而不只是“分数”。
二、Plano 的路由思路为什么不一样
Plano 是一个开源的 AI 原生代理(更准确说是 proxy/平台),把路由、编排、安全护栏和可观测性整合在一起。
它的路由核心是 Arch-Router-1.5B。和常见“按 Benchmark 分配任务”的方式不同,它走的是偏好对齐:在训练数据上更强调“人类/开发者在真实使用里倾向怎么选”,而不是只问“哪个模型更聪明”。
落到使用层面,就是你可以直接在配置里用自然语言写偏好,不需要规则引擎、不需要正则、不需要写一堆 if/else:
之后你基本就不用管了。每个 prompt 进来,Plano 自动匹配、自动转发。
如果路由错了怎么办?这也是 Plano 很实用的一点:它把可观测性做得很顺手。你能追踪每一次路由决策,看它为什么把某个请求分给了某个模型,然后只要调整偏好描述就能纠正,而不是去改一堆业务逻辑。
三、实操:把 OpenClaw 接到 Plano 上
下面用 OpenClaw 举例(但思路适用于任何“默认把所有 prompt 发给单一模型”的 Agent 工作流)。
1)设置 API Key
在 .env 里配置好你要用的两个模型的 key:
export KIMI_API_KEY="your_kimi_key"export ANTHROPIC_API_KEY="your_claude_key"
2)写 Plano 配置文件
新建 plano.yaml,把 providers 和你的偏好写进去:
providers: - name: kimi model: kimi-k2.5 api_key_env: KIMI_API_KEY - name: claude model: claude-opus-4.6 api_key_env: ANTHROPIC_API_KEYrouting_preferences: - task: "conversation, agentic tasks" preferred_model: kimi - task: "code generation, testing, reasoning" preferred_model: claude
这里的 routing_preferences 不需要你写规则,它更像是在对路由器说“我的使用习惯是什么”。
3)启动 Plano
plano start --config plano.yaml --with-tracing
--with-tracing 强烈建议加上:后面你验证路由、排查误判、微调偏好描述都会省很多时间。
4)启动 OpenClaw
openclaw installopenclaw start
需要接 WhatsApp/Telegram 的话,也是在这一步配。之后可以用:
检查服务状态。
5)让 OpenClaw 指向 Plano(关键一步)
在 OpenClaw 初始化向导里,选择 LLM 提供商时这样填:
Provider 类型:Custom OpenAI-compatible
Base URL:http://127.0.0.1:12000/v1
API Key:随便填,比如 none(Plano 会处理真实 key)
Context Window:至少 128000 tokens
这样 OpenClaw 的所有请求都会先打到 Plano 的 12000 端口,再由 Plano 根据偏好把请求转给 Kimi 或 Claude。对 OpenClaw 来说,它只是换了一个“更聪明的后端”。
四、路由效果大概长什么样
配好之后,你会得到类似这样的分工:
用户 Prompt | 路由到 |
|---|
“帮我写一段处理并发的 Python 代码” | Claude Opus 4.6 |
“今天天气怎么样?” | Kimi K2.5 |
“分析这个日志文件,找出异常模式” | Claude Opus 4.6 |
“讲个笑话” | Kimi K2.5 |
“给这个函数写单元测试” | Claude Opus 4.6 |
开启 tracing 后,你还能看到接近这种粒度的决策过程:
用户请求:"生成一个单元测试函数"
→ 任务分类:code + testing
→ 路由决策:Claude Opus 4.6(匹配偏好配置)
→ 实际调用:Anthropic API
当你发现某类任务被分错了,最简单的修正方式不是改业务代码,而是回到 plano.yaml,把偏好描述写得更贴近你的语境。
五、总结
我们做 AI 应用时,浪费了太多时间在“选模型”上——仿佛只要选对了,后面就一劳永逸。
但现实里很少存在一个模型能同时在“成本、速度、稳定性、推理、代码、对话、工具调用”上都最优。Claude Opus 和 Kimi K2.5 各有长处,这是事实,争不出绝对高下。
真正该问的问题从来不是“哪个模型最好”,而是:
这个具体任务,应该用哪个模型?
智能路由的价值,就是把“每次都要做选择”这件事,交给一个专门干路由的小模型去做。你只要定义一次偏好,之后每个 prompt 自动选择,既不需要人工干预,也不需要你改任何业务逻辑。
最后你会得到一个很现实、也很舒服的结果:简单任务上省下来的 token 成本,可以用来保证复杂任务上的质量不妥协。
这才是更像工程的权衡方式。
装了 OpenClaw 依然不会用的真相:不是你不聪明,是你没学会“治理”
你有没有这种体验:兴冲冲装好 OpenClaw,打开一看,Tools 一大堆、Skills 一长串,像刚搬进一间设备齐全的厨房——刀具、烤箱、料理机全在,但你连“先开火还是先洗菜”都不确定。
更要命的是,你隐约感觉它很强,却又不敢用:全开怕出事,全关又等于白装。于是 OpenClaw 变成了一个“看起来很忙、其实没产出”的摆设。
一、安装只是开始,配置才是灵魂
1)真实痛点:为什么很多人装完 OpenClaw 后依然不会用
很多人第一次接触 OpenClaw 的路径几乎一致:
最终就会走向两个极端:
全开:功能确实多,但心里发毛,担心安全风险和隐私
全关:最安全,但也最没用,等于白装
OpenClaw 的痛点从来不是“不会聊”,而是“不会管”。
2)本文目的
这篇文章想解决的其实就三件事:
把 25 个 Tools 的能力与风险讲成你能用的“开关逻辑”
把 53 个官方 Skills 讲成你能选的“场景清单”
给你一套可直接抄作业的“安全 + 高效”最小可用配置
3)核心观点
OpenClaw 不是聊天机器人,它更像一个 Agent 操作系统。
真正的核心从来不是模型有多聪明,而是三件事:
你用得越深越会发现:这套系统的本质,是在“能力”与“安全”之间,找到一条能长期跑的平衡线。
二、核心认知:搞懂 Tools 与 Skills 的本质区别
很多人用不好 OpenClaw,不是因为配置复杂,而是把 Tools 和 Skills 混成了一锅。
1)Tools = AI 的“器官”
Tools 决定的是:AI 能不能做某种动作。
read / write:能不能读写文件(手脚)
web_search:能不能获取外部信息(感知)
exec:能不能在系统里执行命令(力量)
如果不开 Tool,AI 就算知道答案,也只能“建议你怎么做”,无法替你做。
2)Skills = AI 的“教科书”
Skills 更像是行为模式和流程说明:
你可以把 Skill 理解成“剧本”,把 Tool 理解成“演员能不能动手”。
3)一个关键误区
安装 Skill ≠ 授权权限。
很多人以为“我装了 Gmail Skill,它就能帮我管邮箱”。但真正决定它能不能动你邮箱的,是 Tools 里的权限,以及你有没有完成登录/OAuth。
4)能力真正生效的三个条件
任何 Skill 想真正跑起来,至少要满足这三条:
Tools 允许它做那类动作
CLI 或桥接工具已安装(否则只是“理论上能”)
你完成了账号授权(OAuth/登录)
缺一不可。你遇到的“它怎么不动”,大概率就卡在这里。
三、架构核心:OpenClaw 的同心圆三层防御体系
我很喜欢用“同心圆”理解 OpenClaw,因为它把能力边界和安全策略天然绑在了一起:越靠里越基础、越靠外越强大也越危险。
Layer 1:核心能力(8 个 Tools)
这是底盘,负责:
策略很简单:几乎所有用户都要开,但要把“最危险的那一项”管住——也就是 exec。
我个人的底线是:exec 必须开审批(Approvals)。它是最后一道安全防线。
Layer 2:进阶能力(17 个 Tools)
这一层开始像“外挂”,包括:
浏览器自动化
长期记忆
多任务并行
自动通知
定时任务
硬件控制
我的建议是:按需开,别被功能诱惑。
推荐开启的两个很实用:
谨慎开启的两个:
核心原则就一句话:按需开启,而不是功能导向。
Layer 3:知识层(53 个 Skills)
这层本质上是“外部服务说明书”,覆盖:
风险点也很明确:很多 bundled Skills 默认会自动加载。技能越多,不代表效率越高,反而更容易误触发、越权和误操作。
最佳策略是:白名单控制——用 allowBundled 只加载你真的需要的那几项。
四、Layer 1 核心工具详解(真正的生产力底座)
1)文件系统能力:生产力的地基
常见的文件相关 Tools(不同环境名字略有差异)大致包括:
read / write
edit / apply_patch
这类能力一旦开对了,OpenClaw 才会变得像“助手”,而不是“顾问”。它可以:
自动改代码、写脚本
批量处理文档(重命名、格式化、抽取信息)
把一堆重复操作拼成稳定流程
很多人以为效率来自“更多技能”,但我见过真正效率提升最大的,反而是:把文件读写能力开对、路径权限管好。
2)执行命令(exec):最强能力,也是最大风险
exec 是那种“开了会爽、开错会哭”的能力。
我的建议很硬:必须开启审批模式,尤其是下面几类操作必须人工确认:
删除、覆盖、清空类命令
涉及凭据、密钥、环境变量的操作
安装来源不明的脚本或包
会改系统配置的命令
你可以让它拟命令、解释命令、准备脚本,但“扣扳机”这一下,最好永远是你点确认。
3)网络访问能力:让它不再只会背知识点
web_search、web_fetch 这类工具的价值很直接:
让 AI 能获取实时信息
做研究、查资料、比对版本更新非常高效
但也要注意:网络能力会带来“信息污染”和“被诱导”的风险,尤其是自动执行链路里,尽量别让它从网页上抓到一句命令就直接跑。
五、Layer 2 进阶工具详解(自动化的开始)
1)浏览器自动化:强,但必须留刹车
浏览器工具能做的事包括:
但原则我只认一个:最后一步必须人工介入。
尤其是涉及付款、提交表单、发送信息这种“一旦点下去就不可逆”的动作。
2)长期记忆:越用越顺手,也越需要边界
长期记忆(如 memory_search、memory_get)的意义是:
个性化:它知道你的偏好、项目背景、常用格式
长期协作:你不用每次从零讲一遍
经验沉淀:它会越来越像你的“第二大脑”
但建议你一开始就定规矩:哪些能记、哪些不记(比如账号、密码、隐私信息一律不进记忆)。
3)多 Session 并行:把“同时做事”变成可控
并行能力适合三种场景:
如果你经常遇到“聊着聊着跑偏”,并行 session 是解决方案之一。
4)消息通知:只给自己,别替你对外说话
message 的正确打开方式是:
只给自己发送提醒或摘要
不直接替代对外沟通(尤其是工作群、客户)
你可以让它写好消息草稿,但“发出去”由你决定。这条规矩能省掉很多尴尬。
5)自动化任务:cron + gateway 才是“能跑起来”的系统
当你把 cron + gateway 组合起来,你就进入了 OpenClaw 的“自动化舒适区”:
一个特别实用的例子:每天早上自动推送 Daily Brief:
这个组合的意义在于:你不再是“想起来才用 AI”,而是让它在固定时间把信息送到你面前。
六、Layer 3:53 个官方 Skills 场景解析(怎么选才不乱)
1)重要提醒:默认自动加载不等于默认安全
Skills 多不等于强,默认自动加载更不等于适合你。你真正需要的是:
列出你高频场景
白名单只启用必要技能
让系统稳定、可预测
2)笔记管理:选你真正用的那一个
典型的笔记类 Skill 包括:
Obsidian
Notion
Apple Notes
Bear
建议很现实:你用哪个,就开哪个;别为了“以后可能用”先全开。因为一旦涉及同步、授权、索引,就会带来额外风险和维护成本。
3)工作生产力:最值得优先配置的一类
比如:
Google Workspace 自动化
邮件与日历管理
这类 Skill 的价值很稳定:省时间、省脑力、可量化。
4)即时通讯:建议默认偏保守
WhatsApp / Slack / Discord 这类我通常建议:
原因很简单:对外沟通一旦自动化,出错的成本太高。
5)开发者生态:最容易做出“实战价值”
GitHub、CI/CD、远程调试这一类,适合:
随时查看项目状态
自动生成 issue/PR 草稿
汇总 CI 失败原因、给出修复建议
它特别适合“你做决策,AI 做脏活累活”。
6)密码管理:高风险区
密码管理类 Skill 风险很高:一旦授权,就等于把最核心的资产交给系统链路。
建议两条路二选一:
七、最小可用方案
1)配置原则(我一直遵守的三条)
想不到使用场景的,坚决不开
能力越强,管控越严(尤其是执行与对外动作)
不可逆操作必须人工完成
这三条能让你用得久,而不是爽两天就关掉。
2)推荐 Tools 配置
我日常会开启的方向:
文件能力(读写编辑)
网络能力(搜索/抓取)
记忆能力(谨慎使用)
自动化(cron + message)
Session 并行(避免互相干扰)
我会默认关闭或非常谨慎的:
3)推荐 Skills(少而稳)
我一般只开这些“稳定高频”的:
邮件
日历
GitHub
天气
总结/归纳类(把信息变成可执行清单)
能力少,但系统会非常稳定。你会明显感觉到:它开始像一个可靠的助手,而不是一个随机发挥的聊天工具。
4)一个真正能提升体感的自动化案例:Daily Brief
我的做法是:
设定每天 6:47 自动发送
内容固定三块:邮件摘要 + 天气 + 待办事项
这件事的价值不在于“多酷”,而在于它把你的早晨从“到处打开 App 找信息”变成“信息主动来找你”。你坚持两周,工作流会发生肉眼可见的变化。
八、安全红线:哪些能力绝对不能乱开?
1)高风险 Skills:越方便越要小心
例如:
这些最容易成为注入攻击、越权访问的入口。别赌运气。
2)exec 的最后防线:审批必须开
再强调一次:exec 不开审批,迟早出事。
你可以让它跑,但你必须在关键步骤上“按下确认”。
3)第三方 Skills:社区繁荣,也意味着参差不齐
面对第三方 Skill,我的建议是三件事:
能看代码就审一下
最小权限原则
先沙箱测试,再接入主环境
九、认知升级:别让 AI “裸奔”
很多人以为“AI 不够强”,所以不停换模型、追新版本。用到后面你会发现,真正的问题其实是:缺乏治理。
真正的竞争力来自:
自动化能力(能持续跑)
安全架构(可控、可预测)
个性化工作流(贴合你自己的节奏)
OpenClaw 的价值不在于陪你聊天,而在于成为你个人的“可执行系统”。
十、总结
OpenClaw 最打动我的地方是:它不是一个单点工具,而是一套可以长出来的体系——像“个人操作系统”,像“一人公司基础设施”,也像你自己的“数字员工平台”。
如果你现在还在“全开/全关”之间摇摆,建议你做三件事:
检查现有配置,把默认全开的技能收回来
从白名单开始,只留最必要的 Tools 和 Skills
先跑通一个 Daily Brief 这样的自动化,再逐步扩展
你会发现:当你开始精确控制,而不是堆功能,OpenClaw 才真正变得好用。
重新定义企业AI架构:为什么说“MCP连接器+Skills技能库”是让AI干活的关键?
把SOP变成AI能力:用MCP打通企业内部系统,安全可控地让AI“能办事”
很多企业在引入大模型之后,都会经历一个相似的阶段:演示时很惊艳,内部试用也能写文案、改措辞、做总结;可一旦把它放进客服、运营、供应链、财务这些“真业务”里,就会迅速卡住——不是它不聪明,而是它没有“手”和“权限”,更没有“流程”。
你让它回答“退款规则是什么”,它能说得头头是道;但你让它“查一下这个用户的订单状态、核对是否满足条件、创建工单并通知用户”,它就开始绕圈:要么编造,要么让你去系统里自己点。
问题从来不在“会不会聊天”,而在“能不能办事”。
一、企业真正缺的是“会聊天的AI”
通用的ChatGPT/Claude这类模型,优势是知识广、表达强、推理好——它们“知道很多、答得像”。但企业落地时,常常变成另一种尴尬:它说得很对,但解决不了你的问题。
因为企业的答案不在公开互联网上,而在内网系统里:
于是矛盾出现了:模型再聪明,也没法直接替你“点按钮、查记录、写工单、发短信、改地址”。
所以真正的灵魂拷问是:
如何把公司内部SOP与知识库,变成AI可调用、可治理、可复用的 Skills?
换句话说:让AI不仅“能回答”,更“能按公司规则把事办完”。
二、从“知识库(RAG)”到“技能(Skills)”差在哪
这两年很多企业第一步会做RAG(检索增强生成),把资料接进来,让模型“有据可查”。这一步很重要,但它的天花板也很明显。
1、RAG擅长解决什么
查得到:能从知识库里检索到相关内容
答得像:组织语言、解释条款、给出建议
可引用:把出处贴出来,提升可信度
但RAG经常止步于“解释/建议”。你要的是结果,它给的是指导。
2、Skills补齐的,是“执行能力”
企业真正需要的是一套可控的“动作库”,让模型能把流程跑起来:
调系统:查订单、查物流、查权限、创建/更新工单、发短信、生成退款申请
遵循SOP:条件判断、步骤编排、异常处理、回退策略、转人工兜底
权限与风控:谁能调用哪些工具、哪些字段可见、哪些动作必须二次确认或审批
如果把RAG理解为“会翻资料”,那Skills更像“能按SOP去做事”。
3、企业级验收标准
要让业务部门“敢用”,至少要满足这些要求:
接下来核心问题就变成:这套“技能化”的能力,怎么用工程方式做出来。
三、MCP + Skills 的私有化部署架构
用 MCP 把内部系统能力标准化暴露给模型,用 Skills 把 SOP 封装成可复用业务动作,用私有化部署保障安全与治理。
1、MCP是什么:把“连接方式”标准化
你可以把MCP理解成“AI时代的USB‑C”。
过去我们做Agent对接系统,经常是N对N:
一个模型/应用要接多个系统,每个系统要写一套SDK/接口适配;换模型还得重来一次。
MCP的价值在于:它把“模型 ↔ 工具/数据”的连接协议统一起来。
内部系统只要通过MCP Server以标准方式暴露能力,支持MCP的模型/Agent就能复用同一套能力,不用每次重新定制集成。
2、系统架构
落地时建议把边界切清楚,尤其是内网安全边界:
模型/Agent层
可私有部署LLM,也可托管(取决于合规要求)
负责意图理解、决策、调用工具与组合技能
MCP Server层(内网关键边界)
Skills层
把SOP流程产品化:可组合、可版本化、可回滚
把“经验型流程”变成“工程可执行流程”
治理层
3、MCP接入内部数据源:先把边界立住
常见接入对象包括:CRM、工单系统、订单库、物流、知识库、权限系统等。接入策略上,强烈建议遵循“三个优先”:
优先只读:先把查询类能力打通(订单/物流/政策/工单状态)
优先白名单:查询条件、字段范围、接口范围全部白名单化
优先最小权限:按角色、按动作、按字段授权;敏感字段默认脱敏
可写操作(改地址、退款、发券等)一定要做风险分级:
把“能做”建立在“敢放开”之上。
4、Skills怎么设计:把SOP工程化
SOP落地成Skills,不是把文档丢给模型就结束了,而是要像做接口一样做“定义”。
一套可用的Skills通常会明确:
输入/输出:需要哪些参数,返回什么结果
前置条件:权限校验、数据校验、状态校验
步骤编排:按业务顺序调用哪些工具
失败分支:哪些错误可重试,哪些必须转人工
回退与兜底:写操作失败如何补偿,如何保证一致性
粒度上建议从“小而稳”开始:
先做原子技能(查订单、查物流、创建工单),再组合成端到端流程(查询→判断→处理→通知)。越早追求“大而全”,越容易在权限、异常、体验上翻车。
最后别忘了版本管理:规则变了、话术变了、字段变了,都要能追溯变更、能一键回滚。
四、企业客服机器人从0到1
以客服场景为例,这类项目最适合验证“技能化”的价值:需求高频、流程相对标准、指标也好衡量。
1、项目目标
降低人工接待压力
缩短响应时间
提升一次解决率(别只追求“回复率”)
场景范围建议从这些开始:
订单查询、物流追踪、退款规则解释、创建/更新工单。先覆盖“查询+记录”,再逐步走向“修改+执行”。
2、分阶段实施路径
场景选择与ROI评估
优先:高频、规则明确、风险可控。别一上来就做退款直通。
数据梳理与权限定义
列清楚系统清单、字段清单、角色与操作边界。很多项目失败不是模型问题,而是“到底能不能看、能不能改”没定义清楚。
MCP接入:先只读,再可写
先接订单/物流/政策/工单状态等查询能力。稳定后,再引入创建工单、改地址等写能力。
Skills封装:把TOP SOP变成技能
把最常见的TOP流程做成技能,并明确异常路径与转人工兜底话术。越清晰,体验越稳定。
联调与评测:别只测回答质量
除了准确率/召回、幻觉率,还要看:
上线与治理:灰度发布 + 审计回放
灰度、监控告警、审计与回放要一开始就有。否则一旦出问题,你连“它到底做了什么”都复盘不了。
3、关键难点与对策
SOP/知识更新频繁:用“版本化Skills + 内容发布流程”联动,别靠人工口口相传
风险操作(退款/改地址):权限校验 + 二次确认 + 审批/复核,把风险动作关进笼子
体验一致性:统一回复模板与品牌话术;失败时明确告知原因并顺滑转人工
4、结果怎么展示
建议用这几类指标向上汇报,更容易形成持续预算:
自助解决率
转人工率
工单创建成功率
CSAT/满意度(或服务评价)
平均处理时长(AHT)
五、总结
企业AI的胜负手不在“会说”,而在“能做、敢用、可控”。
MCP把内部系统能力打通,让连接从“定制集成”走向“标准接口”
Skills把SOP变成可执行能力,让模型从“建议者”变成“办事员”
私有化部署与治理体系,让每一次调用都有权限、可审计、可回放
真正可落地的路径往往很朴素:
从一个低风险、高频场景起步,先做“可控闭环”;先只读后可写,先原子后组合,先灰度后全量。做到这一步,你会发现大模型不再是“演示工具”,而是能被业务依赖的系统能力。
别被OpenClaw 14000 个 skills吓到! 高手只用这几十个技能(附实战工作流)
我最近打开 OpenClaw 的技能市场,愣了整整三分钟。
页面上滚动条细得像一根头发,往下拉,拉,再拉——14000 多个 Skills,密密麻麻排列着,每一个都在说"我很有用,选我"。我关掉页面,重新泡了杯茶,心想:这玩意儿我到底该怎么用?
像极了走进一家巨大的五金城——扳手、螺丝刀、电钻、焊机一应俱全,但你只想把家里那条松动的桌腿拧紧。结果逛了半小时,手里拿着三样“看起来很厉害”的工具,回家还是没动手。
这就是多数人用 OpenClaw 的真实卡点:不是不会用,而是不知道从哪用起、该装哪些、怎么组合起来真正“干活”。
大模型是“大脑”,Skills 是“手脚”。没有 Skills,它更像顾问;装对 Skills,它才像一个能交付结果的执行者。
这篇文章不带你“收藏 14000 个”,而是帮你搭一套覆盖 80% 场景的“最小高效技能栈”,并且给你能直接照抄的工作流。
一、当 OpenClaw 装上“手脚”,世界真的变了
很多人对 OpenClaw 的误解是:它就是一个更会聊天的 AI。
但你很快会发现——聊天解决不了“把附件批量下载、提取数据、汇总成表、再发回邮件”这种工作。它能告诉你怎么做,却做不了。
Skills 的意义就是把“知道怎么做”变成“直接去做”。
你面对 14000+ Skills 的选择困难,本质上不是你选择能力差,而是技能库的设计本来就不是让你逐个学会的。
说句扎心的:一天试一个,要 37 年。你不可能靠“勤奋”解决筛选问题,只能靠“方法”。
二、重新认识 OpenClaw:不止于“多”
OpenClaw 是一个低代码 / AI Agent 自动化引擎,让大模型具备调用工具、访问资源、执行流程的能力。
14000 的真相不是“你需要装这么多”,而是“它能扩展到这么多”。
普通用户和高手的差距也不在于“装了多少”,而在于:
接下来先别急着装技能,先穿防弹衣。
三、 高能预警:狂欢前,先穿“防弹衣”
如果你把 Skills 当“插件”,那安全就不能当“提醒”。
尤其是 2026 年之后,大家对供应链投毒已经不陌生:CVE-2026-25253 漏洞 + ClawHavoc 事件(335 个恶意 Skills 混入库),这类事的共同点是——它不需要你“点错按钮”,它只需要你“装了它”。
我建议把安全当作默认配置,而不是遇到问题再补票。最实用的就是“安全三件套”:
Skill Vetter:安装前自动扫描代码/权限/可疑行为
Sandbox Runner:隔离运行高风险技能(网络、文件、进程)
Key Guardian:监控 API Key 异常调用(频率、目的地、异常时间段)
选技能的黄金原则也很朴素,但很有效:
高星 + 高下载量 + 近期有更新 + 来源认证。别迷信“功能强”,先看“可追责”。
在 OpenClaw 的世界里,信任是昂贵的,验证是必须的。
四、核心技能矩阵:先画地图,再挑装备
给 14000 个技能建一张地图。在列具体推荐之前,先帮你建立一个全局视角。把所有技能粗暴地归成六类,基本上就能覆盖 95% 的使用场景:
效率基石类——文件处理、系统控制、终端命令。不管你是什么职业,这一层几乎人人都用得上。
网络与数据类——网页抓取、API 调用、数据库交互。开发者和做运营的人会在这里花最多时间。
AI 与大模型类——LLM 串联调用、OCR、语音转文字。如果你在做内容或者有大量非结构化数据要处理,这一层是宝矿。
数据分析类——Excel/CSV 处理、可视化、自动报告生成。职场人最高频的需求,这一层往往能直接省掉半天的重复劳动。
创意生产类——文案写作、脚本生成、社媒内容适配。创作者的效率倍增器。
垂直行业类——财务对账、HR 筛选、电商上架。专业性强,但一旦用对,带来的价值远超通用工具。
技能库越大,越需要分类思维。你不需要记住每个技能的名字,但你必须知道它们在地图里的位置。
接下来进入最关键的部分:我更推荐你从“30 个核心技能”起步,而不是从“我是不是要全装”开始焦虑。
五、真正该装的那些:30 个足够了
第一层:底座(让 AI 先"活"下来)
Shell是绕不开的起点。文件管理、脚本运行、目录操作——几乎所有复杂工作流都绕不过命令行这一层。不懂代码也没关系,很多操作你只需要告诉 AI 你想做什么,它会帮你生成命令。
Brave Search 或 Bing Search,两个选一个即可。让 AI 具备实时联网搜索的能力,免费计划每月 2000 次调用,日常够用。没有搜索能力的 AI 就像个闭目塞听的书呆子,有了它才算真正接地气。
Memory Search,长期记忆检索。你曾经告诉它的偏好、历史记录、项目背景,它都能在后续对话里主动调用。装上之后你会发现,每次对话不用再重复交代背景了。
第二层:办公与开发(把 AI 变成超级实习生)
GitHub Manager:查 Issue、跟进 PR 状态、生成周报摘要,开发者标配。周一早上十分钟,上周所有代码变更一目了然。
Excel/CSV Wizard:自动清洗脏数据、生成图表、做交叉分析。我把一份格式混乱的销售表格扔进去,不到两分钟出来了一份干净的分析报告。这种事我以前要花一个小时。
Email Automator:自动收取、分类、生成摘要,还能按模板起草回复。如果你每天要处理大量邮件,这个东西能帮你把收件箱从噩梦变成清单。
Ship-Learn-Next:说实话这个名字起得有点奇怪,但功能很实用——它帮你追踪行动闭环,盯的是产出而不是计划。跟 GTD 工具的区别在于,它会主动追问你"上次说要做的那件事,做了吗"。
第三层:创意与生活(私人助理感)
Content Creator:写完一篇内容之后,自动适配成微信公众号、小红书、LinkedIn、Twitter 等不同平台的格式和语气。别小看这个"改格式"的步骤,我之前每次都要手动改,费的时间比写稿子还多。
Remind-Me:不是普通的日历提醒,它做的是上下文关联提醒。比如你在聊一个项目的时候提到"三天后记得跟进",它会在三天后提醒你,并且附带当时的对话背景,不需要你再翻记录。
Travel Planner:行程规划加票务查询,出差族的好帮手。把你的出行需求和时间窗口告诉它,它会给你一个可执行的方案,包括备选路线。
以上这些是我自己高频使用的核心层。按自己的情况挑着装就行,不需要全部上。安装步骤很简单:直接将 Skill 的 SKILL.md 文件链接或官方网页链接发送给 OpenClaw,AI 会自动完成安装。
六、管理技能别乱堆,用"同心圆"结构
很多人把 Skills 当插件乱装一通,到最后上下文窗口被撑爆,整个 Agent 响应变慢,自己也搞不清哪些还在用。
我用的是同心圆架构:
内核层:高频率、高权限的技能,Shell、搜索、记忆检索这些放在这里。这一层严格审核,一旦确定就几乎不动。
中间层:日常办公技能,根据近期工作重心按需开启。这周在写报告就开数据分析类,这周在做内容就开创意生产类。
外层:实验性技能,新发现的、不确定好不好用的,放在这里试。用完即关,甚至用完就卸载。
这样一来,常驻内存的技能永远保持在一个合理数量,既不影响性能,也方便随时审计"我现在给 AI 开放了哪些权限"。
七、工作流组合,才是真正拉开差距的地方
单个技能的价值是线性的;把几个技能串联成工作流,价值是指数级的。
给你三个能直接照抄的工作流案例:
案例 1(职场白领):日报自动化
流程:邮件附件自动下载 → 提取数据 → 填入 Excel → 发送日报
你只需要 5 个技能,搭一次之后每天都省事。
一句话指令示例:
“每天 17:50 拉取‘日报数据’主题邮件的附件,汇总到周表,生成图表并发给我和主管。”
案例 2(内容创作者):热点到分发
流程:热点搜索 → 要点提炼 → 文案生成 → 多平台格式适配 → 一键分发/定时发布
关键不是“写得快”,而是“稳定输出且风格统一”。
一句话指令示例:
“抓取今天关于 XX 的权威信息,输出 3 条选题角度,每条给:标题、开头 80 字、结尾引导关注。”
案例 3(开发者):竞品动态日报
流程:抓取竞品更新 → AI 摘要 → 自动邮件推送到团队
做一次,团队每周都能受益。
一句话指令示例:
“每天 9:00 拉取竞品 release note 和关键 PR,生成 1 页摘要并发到组内邮件列表。”
八、进阶一点:不只是"用",还可以"改"和"造"
改:大部分 Skills 内部有 Prompt 模板,你可以根据自己的使用场景微调。比如 Content Creator 默认的写作风格偏正式,你可以把模板改成更口语化的版本,用起来更顺手。
串:多个简单的 Skill 可以用 Chain 逻辑连接起来,数据从一个技能的输出直接进入下一个技能的输入。这是构建复杂工作流的核心手法。
造:当 14000 个都不够用(这种情况虽然少,但确实会遇到),你可以自己写一个 Skill 上传到社区库。文档写得够清楚、场景够具体,很快会有人 Star,社区还有荣誉榜和积分激励机制。
九、你可能会问的几个问题
装太多 Skills 会卡吗?
会。至少会占用上下文管理与权限管理成本。按同心圆原则:常驻少、按需开、实验用完删。
第三方 Skills 安全吗?
不默认安全。必须配合安全三件套,优先“高星+高下载+近期更新+来源认证”,权限最小化。
跨平台支持如何?
Windows / Mac / Linux 基本都能用,但涉及系统命令、文件路径、权限模型的技能可能有平台差异。
技能库更新频率?
社区驱动为主,官方认证库通常按周审核更新。越活跃的技能越要看维护记录与 Issue 响应速度。
十、总结
OpenClaw 的上限,取决于你赋予它的技能广度与深度。但更重要的是,深度比广度值钱得多。
10 个真正融入工作流、每天在用的技能,远胜过收藏了 1000 个却只是偶尔打开瞧一眼的清单。
别让你的 OpenClaw,只会在沙滩上夹人。
揭秘OpenClaw+Playwright Skill:用说话替代编码,重新定义自动化
明明需求说得清清楚楚:"去这个网站,把这几个字段整理成表格。"结果每次还是得自己坐下来,打开开发者工具,分析 DOM,写选择器,跑脚本,报错,贴日志,再改……
你可能也试过用 ChatGPT 来"提效":让它帮你写段 Playwright 代码,拷贝过来跑,报错了再把日志贴回去,改 selector、加等待、处理弹窗。折腾半天,最后发现:自动化的根本不是流程,是你和 AI 之间的来回拉扯。
这不是真正的自动化,只是把人肉操作换成了人肉调试。
真正让我觉得有什么东西变了的,是今年初开始用 OpenClaw + Playwright 这套组合之后。
一、我们到底在解决什么问题
先把问题说清楚,省得后面讲方案显得像在无病呻吟。
传统爬虫的死穴,现在做过采集的人都懂:requests 写得行云流水,发出去的请求拿回来的 HTML 里只有一个 <div id="app"></div>。面对 JS 动态渲染和无限滚动,HTTP 请求根本打不进去。
于是你转向 Selenium 或者 Playwright 脚本。确实能拿到数据了,但维护成本让人绝望——页面改个类名,你的选择器就失效了;想处理个滑块验证码,又得调第三方 API,写一堆回调逻辑。
市面上也不是没有别的选择。n8n 这类低代码平台在处理多 Tab 切换、特定轨迹滑动这种复杂交互时力不从心;Apify 这类云服务虽然强大,但没有现成的 Actor 脚本,你要么掏钱定制,要么回去自己写代码。
真正缺的,从来都不是"会不会写脚本"。缺的是:有没有一种方式,让你只负责说清楚目标,执行交给机器,结果能直接拿来用。
这就是"AI 辅助你执行"和"AI 自己去执行"之间的本质差距——大概相当于"给我一张地图"和"帮我开车到目的地"。
二、OpenClaw 和 Playwright,为什么是这两个
OpenClaw 是今年初在 GitHub 上突然火起来的开源项目,定位很清晰:基于大语言模型做决策和任务调度的 AI 执行框架。它擅长理解自然语言,能把你的一句"抓取所有商品并保存",实时转化成包含 page.goto、page.fill、page.evaluate 的可执行代码,还能在任务出错时通过 DOM 语义理解自动调整选择器,不用人工重写。
Playwright 这边就不多说了,微软 2020 年开源的,现在已经是浏览器自动化的事实标准。和 Selenium 比,最关键的区别是自动等待——执行 click() 或 fill() 之前,它会自动判断元素是否可见、可交互、未被遮挡,不需要你手写 time.sleep。这对 AI 生成的代码来说尤其重要,因为 AI 根本不知道你的网络有多慢、某个动画要跑多久。
另外 Playwright 的 API 语义本身就接近自然语言:page.goto(url),page.click(selector),page.fill(selector, value)——AI 生成这类代码的准确率明显比 Selenium 高。原生支持多 Tab 操作、网络请求拦截(直接捕获 API 响应拿 JSON,比解析 HTML 稳得多)、截图和轨迹录制、文件下载处理,这些加在一起,构成了整套方案的执行底座。
两者的分工很清楚:OpenClaw 是指挥官,Playwright 是特种部队。 一个负责决策,一个负责动手,调用链路是这样的:
你用自然语言说出需求 ↓LLM 理解意图 → 选择对应 Skill → 生成调用参数 ↓run.py 接收参数 → 启动 Playwright → 执行浏览器操作 ↓结构化结果回传给 LLM → LLM 继续推理 → 最终输出给你
三、Skill 是整套方案的核心,得专门说说
OpenClaw 里有个叫 Skill 的机制,是整件事能跑通的关键。
你可以把 Skill 理解成给 AI 装上的一个标准化工具。文件读写是一个 Skill,调用外部 API 是一个 Skill,操作浏览器也是一个 Skill——也就是 Playwright Skill。
一个 Skill 的目录结构是这样的:
skills/playwright-skill/ ├── SKILL.md # 给 AI 看的说明书 ├── spec.yaml # 输入参数和输出结构的定义 ├── template.md # AI 组织调用的 Prompt 模板 └── run.py # 真正干活的执行引擎
SKILL.md 是给 LLM 的"工具手册",让它知道什么情况下该调这个 Skill、传什么参数、能拿到什么结果。run.py 才是真正启动浏览器的地方。
这个拆分很重要:AI 负责决策,Python 负责执行,两者完全解耦,各自独立维护和升级。
很多人会问,Playwright 脚本我自己也会写,为什么要多这一层封装?
因为裸脚本的问题不是不能用,是不能持续用。你写了一个 300 行的爬虫,三个月后自己都看不懂选择器为什么那样写。网站改版了,要重新 debug 半天。有新人加入,得花两小时给他讲解上下文。
Skill 化之后不一样:spec.yaml 定义了标准化接口,调用方不需要知道内部实现;错误处理和重试在框架层面统一管理,而不是每个脚本各自写一套 try-catch;多个 Skill 可以被 LLM 按需自由组合,LoginSkill + ExtractSkill + ExportSkill,像乐高一样,每块都是独立可测试、可替换的。
四、实战一遍:抓取招投标网站的中标公告
说原理容易,来看个真实的案例。
任务背景:某省招投标官网,需要抓取近一个月所有中标公告的详细信息——项目名称、招标单位、中标单位、中标金额、预算金额。
难点:页面是 SPA,JS 动态渲染,直接 requests 只能拿到空壳 HTML;公告列表需要按日期 Tab 切换,每个 Tab 下还有多页;详情页每条记录要单独点进去,数据分布在不同区域;有简单的登录态校验。
以前做这个任务,光分析页面结构、写初版脚本就得大半天,调试和处理边界情况再加一天。
现在的做法:
第一步,部署和配置。 服务器上启动 OpenClaw,启用 Playwright Skill。配置文件核心几项:
browser: headless: true timeout: 30000 viewport: width: 1920 height: 1080concurrency: max_tabs: 3 request_delay: 1500 # 每次操作至少间隔 1.5 秒output: screenshot_on_error: true
headless: true 是后台无界面运行,省资源。request_delay 是为了模拟人工节奏,降低被识别为爬虫的概率,这个后面还会专门说。
第二步,下达指令。 这是最省事的一步,不用写一行代码,直接在对话框输入:
请访问 [网站URL],先用账号 [账号] 密码 [密码] 登录,然后点击"中标公告"Tab,从今天往前数 30 天,对每一天的 Tab 逐一点进去,翻页直到加载完全部公告,对每条公告点进详情页提取项目名称、招标单位、中标单位、中标金额(万元)、预算金额(万元),最后整理成 Markdown 表格保存到 output.md,遇到金额缺失的记录用"未披露"填充。
第三步,AI 拆解任务,多 Skill 协作执行。
LLM 收到指令后,把任务拆成几个子步骤:LoginSkill 处理登录,保存 Cookie 供后续复用;NavigateAndFilterSkill 循环处理每一天的日期 Tab,点进去、翻页、收集公告链接,输出一份 URL 列表;DetailExtractSkill 逐条打开详情页,等待动态内容渲染完成再读取,不会因为"元素还没出现"就报错;ExportSkill 做数据清洗,统一金额格式,写入 Markdown 表格。
整个过程大概 4-8 分钟,取决于网络和公告数量。
对比一下前后:
指标 | 以前(纯脚本) | 现在(OpenClaw) |
|---|
初次开发耗时 | 6-12 小时 | 5 分钟下达指令 |
调试和迭代 | 每次页面改版重写 | 修改自然语言描述,AI 重新适配 |
所需技能 | Python + Playwright + 页面分析 | 会打字 |
可复用性 | 脚本绑定特定网站 | Skill 通用,换网站改指令即可 |
五、几个让效果翻倍的实用技巧
上下文复用,性能提升 80%。 不要每次任务都启动新的浏览器实例。利用 Playwright 的 BrowserContext,在 OpenClaw 里实现多任务并行——像一个浏览器里开多个无痕窗口,互不干扰但共享内核,启动速度快得多。
资源拦截,只取所需。 在指令里加"忽略图片和样式",OpenClaw 会生成对应的路由拦截代码:
await page.route('**/*.{png,jpg,css}', route => route.abort());
页面加载速度能提升 50% 以上,对抓取大量列表页尤其有效。
人类化操作,对抗反爬。 不要让点击发生在毫秒级。指令里加上"操作时模仿人类,每步之间随机停顿 1-3 秒",OpenClaw 会引入随机延迟和贝塞尔曲线鼠标轨迹。
大型项目用页面对象模型(POM)。 虽然 AI 能自适应改版,但超大型项目建议在 OpenClaw 里把"登录""翻页""提取"封装成独立的 Skill 模块。这样网站改版时,只需要更新对应的那一块,其他流程照常运行。
六、能做什么?几个真实的落地场景
除了爬数据,这套组合在实际项目里还有几个方向:
自动化回归测试:告诉 AI "遍历我们产品的主要功能流程,记录每一步截图,如果出现 500 报错或 UI 元素对不上,生成 Bug 报告"。本质上就是让 AI 扮演测试工程师,自动走测试用例。
竞品价格监控:设定时任务,每天早上 AI 打开竞品定价页,截图加提取价格,和前一天对比,有变动就推送飞书群。不需要维护一套专门的监控服务,一个 Skill 组合搞定。
批量后台操作(RPA):管理后台里有 200 个历史订单需要逐条核对状态然后关闭,这种重复性操作交给 AI,比让人点两小时鼠标更快更准。每次操作自动截图留证,出错自动停下来等人处理。
内容生成流水线:抓取行业新闻 → 调用大模型生成摘要 → 格式化写入 Notion 数据库。Playwright Skill 负责取原材料,后续加工由 LLM 自己完成,整条流水线自动跑。
七、该说的坑,一个都不省
验证码是真正的硬关。 Cloudflare 的 5 秒盾、复杂图像识别验证码、行为验证(拖拽滑块)——这些 Playwright 直接搞不定。要结合代理 IP 池降低被识别概率、合理的随机延迟模拟人工节奏,必要时接入第三方打码服务。request_delay 别设太短,这个配置项比你想象的重要。
内存消耗比你想象的大。 开一个 Chromium 实例大约吃 200-400MB 内存。三个 Tab 并发,基础内存消耗就到 1GB 了。本地跑没问题,但 max_tabs 别设太高,生产环境建议用带独立内存的云服务器,配合任务队列合理调度。
Selector 写法决定脚本寿命。 AI 生成的代码也要注意审查这一点:优先用 data-testid、aria-label、role 属性来定位元素;其次用文本内容定位("点击包含'提交'字样的按钮");尽量避免 .container > div:nth-child(3) > span 这种结构性 CSS 路径。结构路径一旦改版就失效,而基于语义的描述,换个版本依然有效。
账号安全别图省事。 涉及登录态的 Skill,账号密码不能明文写在指令里。用 OpenClaw 的凭证管理机制,通过环境变量或加密存储传入。
最后,注意访问礼节。 不是每个网站都欢迎你爬。看 robots.txt,设合理的访问频次,别一秒发几十个请求。这既是技术实践,也是基本的职业素养。
八、总结
我不是在说"以后再也不用写代码了"——这不现实,也没必要这么绝对。
但确实有一类工作在快速消失:那种"你知道该做什么,就是没时间去做"的重复性自动化任务。浏览器操作是最典型的例子,因为浏览器是软件世界最通用的接口。
OpenClaw + Playwright Skill 这套组合,本质上是把"编写程序控制计算机"这件事,降低到了"用自然语言指挥一个懂工具的 AI"这个层级。Skill 体系是这里的关键——它把一次性脚本变成了可复用的标准化能力,让 AI 不只会思考,还会执行,还会把执行结果结构化地交回来,驱动下一步推理。
拒绝“高门槛”劝退!AutoClaw如何让OpenClaw的“最强打工人”飞入寻常百姓家?
你是不是也曾感叹,AI 聊天机器人虽然聪明,却总像一位“动口不动手”的朋友?让它查资料、写摘要可以,但一旦需要它自动整理晨报、连续处理多个任务,甚至写完代码并自己测试——往往到一半就“掉线了”。直到 OpenClaw(常被昵称“小龙虾”)的出现,我们才看到 AI 正在迈向下一个形态:智能体(Agent)。它不仅会回答,更会规划、能调用工具、可连续执行,真正帮你把事情“做完”。但想拥有这样一位智能伙伴,门槛却高得令人却步:每月高昂的云服务租金,或是在本地部署时无穷无尽的依赖报错和配置噩梦……Agent 虽强,却把大多数人挡在了门外。就在昨晚,这个局面被悄然打破。智谱 AI 正式发布了 AutoClaw 桌面应用,它只做一件事:史诗级地降低 OpenClaw 的使用门槛。就像安装 QQ 或微信一样,你现在只需点击几下,就能在本地电脑上运行一个完整的 OpenClaw 智能体。 AutoClaw 发布后,终于赶在第一时间为你带来了这份测试体验。在AutoClaw出现前,普通人想体验OpenClaw,通常面临三重门:- 金钱门槛:需要租用云服务器,按月付费,还没创造价值就先投入。
- 技术门槛:需要配置Python环境、处理各种依赖库冲突,非开发者极易从入门到放弃。
- 体验门槛:即便成功部署,也可能是“阉割版”的云端方案,功能不全,响应还受网络影响。
正是这些门槛,催生了“500元代安装服务”甚至“排大队”的魔幻现象。Agent本该是普惠的技术,却成了少数极客的玩具。二、 AutoClaw是什么?给你的电脑“装”一个永久数字员工AutoClaw是智谱AI推出的官方本地化OpenClaw客户端。它的核心逻辑异常简单:下载 → 安装 → 使用。全程就像安装一个普通软件,无需租服务器、无需配环境、无需预先配置API Key。- 真·零成本启动:应用本身免费下载安装。自带免费的智谱模型额度(Pony-alpha-2)让你可以立即开始体验,不满意零成本卸载。
- 真·完整能力:直接在本地运行完整的OpenClaw框架,没有云端方案可能存在的功能裁剪或“降智”问题,能力不打折。
- 真·数据安全:所有任务处理和数据都留在你的本地电脑,不经过任何第三方服务器,隐私和安全有绝对保障。
- 真·无缝融入:可一键接入飞书等办公软件,让你能在最熟悉的IM里直接给“龙虾”派活,实现移动办公。
除了“一键安装”这个最大的颠覆点,AutoClaw在体验上也做了深度优化:安装完成后,你会发现自己瞬间拥有了一个“AI团队”。AutoClaw预置了超过50个Skill(技能),覆盖了内容创作、飞书办公、代码开发、营销增长、金融投研等七大高频场景。- 内容创作:帮你一键生成小红书文案、公众号文章、视频脚本,并可以排期发布。
- 办公提效:自动阅读分析飞书群消息生成日报、整理云文档、管理日程。
- 代码助手:从根据PRD写网站,到写代码、测试、Debug,提供全链路支持。
- 研究分析:自动爬取行业资讯、生成研报、分析股票信息。
2、独家首发:为Agent而生的“最强引擎”Pony-alpha-2AutoClaw还有一个隐藏王牌:抢先体验智谱专为Agent场景打造的神秘新模型Pony-alpha-2。还记得之前在OpenRouter上匿名测试、表现惊艳的Pony Alpha吗?Pony2是它的进化版。普通大模型擅长聊天,但在需要多步规划、连续调用工具的复杂任务中容易出错。Pony-alpha-2就是为解决这个问题而生,它在响应速度、任务规划稳定性和工具调用成功率上都有显著提升。简单说,用上它,你的“小龙虾”会更聪明、更可靠,复杂任务“一次过”的概率大大增加。 | | |
| | |
| | |
| | |
| | |
| 支持自带模型(GLM/DeepSeek/Kimi等),也可付费升级 | |
| | |
四、 实测:一个人,如何用AutoClaw运作一个“公司”?- 早上8:00:还没起床,AutoClaw已自动抓取指定领域的行业新闻和竞品动态,生成一份排版精美的《晨间简报》,准时推送到你的飞书。
- 上午10:00:喝着咖啡对AutoClaw说:“帮我规划这周的小红书内容”。几分钟后,一份包含热点选题、爆款大纲、甚至发布排期表的方案就已就绪。
- 下午14:00:将一个产品功能需求丢给Coding Agent。它在后台自动编写代码、运行测试,你只需要做最后的审阅和优化。
- 晚上20:00:Social Media Scheduler技能自动将打磨好的内容,按计划发布到各个平台。而你,已经可以安心下班。
这一切,都跑在你自己的电脑上,无需云端付费,数据绝对私有。- 下载安装:访问智谱AI官网(或直达下载地址:https://autoglm.zhipuai.cn/autoclaw/),根据你的系统(Windows/Mac)下载安装包。
- 一键安装:运行安装程序,过程与安装普通软件无异,全程无复杂配置。
- 启动使用:安装完成后打开AutoClaw,使用手机号注册登录。你可以直接使用内置的免费模型开始体验。
- 接入飞书(可选但推荐):在应用内找到“一键接入飞书Bot”的选项,按照引导完成配置,即可在飞书里随时随地给你的“数字员工”派活儿了。
- 下达指令:“请帮我收集湖南移动低空经济相关的AI商机,并且保存到飞书文档里面”,很快就把任务干完了。
AutoClaw的出现,其意义远不止是一个好用的工具。它标志着AI Agent能力正从“云端高塔”走向“个人桌面”,从“极客玩具”变成“生产力工具”。未来,懂得如何利用AI Agent的人,其个人效能可能会堪比一个团队。现在,获取这个“数字同事”的成本和技术门槛已经归零。无论是好奇的尝鲜者,还是寻求提效的自媒体人、开发者、运营或分析师,都值得花一分钟下载试试。
为什么说 OpenClaw 不是“更强的智能体”,而是“元智能体”(Meta-Agent)?
如果你最近在关注智能体(Agent),大概率会遇到一种奇怪的分裂感:
一边是各种演示视频:AI 自动整理邮箱、跑脚本、写代码、发邮件,像个不知疲倦的数字员工;
另一边是你真想自己搭一个,发现要接模型、配工具、做记忆、写工作流、搞权限隔离……最后往往以“算了,先用回聊天框”结束。
OpenClaw 被讨论得多,一个很重要的原因是:它让智能体这件事从“工程项目”变成了“系统能力”。更准确地说——它更像一个元智能体。
所谓“元”,不是噱头,而是一条分界线:
普通智能体解决的是“我能不能帮你做事”,元智能体解决的是“我怎么组织一群能做事的家伙,把事做成”。
这两者差的不是一点点,是层级。
一、先把“元智能体”说清楚:它操作的对象,是智能体本身
我们常见的智能体,工作方式大致是:
你给目标 → 它规划 → 调工具 → 执行 → 给结果
它的操作对象是外部世界:邮箱、日历、网页、文件、代码库。
而“元智能体”(Meta-Agent)多了一层:
它的操作对象不仅是外部世界,还是智能体系统本身——包括能力、规则、队伍、路由、记忆结构、执行边界。
简单来说就是:
这也是为什么很多人把 OpenClaw 称为 “Agent OS”(智能体操作系统):它不试图成为最聪明的那个“员工”,它更像提供公司运转的制度、部门、流程、工具库和权限体系。
二、OpenClaw 的“元”到底体现在哪?不是概念,而是几件很硬的事
1)最关键的一条:它能改写自己的能力边界(Self-Modification)
OpenClaw 最具争议也最具代表性的特性,是它能创建、编辑自己的技能文件(常见是 SKILL.md 一类)。这意味着它不是在“用工具”,而是在“造工具”。
你可以想象一个场景:
你连续一周都让它做同一种整理工作(比如固定格式的日报、固定结构的会议纪要、固定路径的文件归档)。很多系统最多是“记住你爱这么干”,下次回答更贴合。
而 OpenClaw 的野心更像是:
把这件事固化成技能,让下次执行更短、更确定、更像流水线。
这一步的性质很微妙:
它不再只是优化输出,而是重写“自己能做什么”的边界。Peter Steinberger(OpenClaw 的作者)也提到过类似意思:人们总在讨论“自修改软件”,他做着做着发现它就发生了——并不是写一篇论文证明,而是落在了工程实现里。
从系统论角度看,这是“元智能体”最典型的标志:它能对自身结构施加影响。
2)它能“用自身构建自身”(Bootstrapping):把自己当作可操作对象
更进一步,OpenClaw 让智能体“知道”自己在哪里运行、源码在哪、文档在哪、工作区怎么组织、用的是什么模型。
这不是自恋式的“自我介绍”,而是工程上的“自举”:需要调试时,你甚至可以对它说——
“去读一下源码,找出这段行为为什么会发生。”
普通智能体很少能做到这一点,因为它们通常只是挂在某个产品界面上的“执行层”。而 OpenClaw 把“运行时”和“工作区”开放给智能体,使得它具备一种元认知能力:能把自己纳入因果链。
当一个系统开始能分析、修改、调试自己的运行逻辑,它就从“应用”向“平台”迈了一大步。
3)多智能体不是“多开几个窗口”,而是可编排、可路由、可协作的“组织结构”
很多产品也说自己支持多智能体,但往往停留在“多个角色提示词”或“多个子任务并行”。
OpenClaw 的多智能体更像“组织架构”:
每个 Agent 有独立的记忆、工作区、日志与权限边界,互不污染
不同 Agent 可以使用不同模型(便宜的跑杂活,强的做关键决策)
通过绑定(Bindings)机制做确定性路由:消息不是“谁都能看见”,而是有优先级、有匹配规则地分发给该处理的人
甚至支持 agent-to-agent 的直接通信与委托(你可以理解为“同事之间能发工单”)
这意味着它不仅能执行任务,还能管理“谁来执行任务、怎么交接、怎么汇总”的问题。
这正是元智能体的典型职责:编排与调度智能体群体。
4)Skills 不是插件那么简单,而是一层“动态能力层”
OpenClaw 的 Skills 生态经常被拿来类比“应用商店”,但更值得看的其实是它的加载机制:它不是把所有技能一次性塞进上下文,而是按需注入——任务触发时才把相关技能内容加载进来,且支持热重载(文件改了,很快就能生效)。
这背后的系统含义是:
它在管理自己的“认知资源”——什么能力在场、什么时候出现、以什么形式出现。
你可以把它理解成一种“渐进式上下文披露”:需要的时候才给大脑看说明书,不需要时就别占内存、别增加干扰。
对普通用户来说,这体验是“技能很多,系统却不笨重”;
对架构来说,这是一种元层能力:动态配置自身能力集合。
5)它的定位不是“我来思考”,而是“我来管理思考者”
OpenClaw 最大的取舍之一,是“模型无关”。
它不把自己绑定在某个大模型上:Claude、GPT、DeepSeek、本地 Ollama,都能接。换句话说,它把“思考”外包给模型,把自己做成:
网关(多渠道入口)
路由(分发到谁)
运行时(怎么执行工具)
记忆(怎么存取)
权限与隔离(能做多大动作)
技能系统(能力怎么扩展)
这句很关键:
OpenClaw 不以自己会思考为核心,它以自己能“管理思考与行动”作为核心。
这也是“元智能体”的核心抽象:它管理智能体,而不仅仅扮演智能体。
6)它还能改“性格”和“规则”:把提示词工程变成可维护的配置工程
OpenClaw 的工作区里会有类似 SOUL.md(人格)、AGENTS.md(规则)、IDENTITY.md(身份)等文件。更重要的是,它可以通过对话去修改这些配置,从而让系统行为发生长期变化。
这意味着你不只是“用它一次”,而是在“养一套系统”:规则变更、协作规范、风险边界,都能逐步迭代。这种可演化性,正是元系统的味道。
三、把这些拼起来,你会发现它更像“公司”,不是“员工”
如果用一个更直观的比喻:
它解决的不是“某件事怎么做”,而是“做事这套体系怎么组织得更稳定、更可扩展”。
你开始像管理团队一样管理 AI:
设立不同岗位的 Agent
给不同岗位不同权限
用路由规则把任务分发给合适的人
用技能库不断扩展组织能力
用记忆与配置沉淀企业/个人的工作方式
这就是“元”的含义:关于智能体的智能体。
四、但也必须泼一盆冷水:元智能体的代价是真实的风险
越像“操作系统”,权限就越高,后果就越重。
OpenClaw 这类系统绕不开两类风险:
安全漏洞与工程风险:有安全机构审计提到过大量漏洞,其中包含高危项。这类系统一旦被利用,影响不会停留在“回答错了”,而是可能触达文件、邮件、终端与凭证。
Prompt Injection / 诱导执行:当智能体会读文档、逛网页、处理邮件时,它可能被恶意内容“指挥”去做不该做的事。更麻烦的是,一旦进入执行链,它可能为了“完成任务”而忽视你临时发出的停止指令——这不是玄学,是典型的自动化系统失控路径。
所以现阶段它更适合:愿意做权限管理、愿意把任务拆出安全边界的人。把它当成“能删邮件的玩具”,往往会吃亏。
五、总结
过去两年大家争的是模型谁更强,但对大多数人而言,真正重要的问题是:
AI 能不能持续、稳定、可控地帮你把事做完?
OpenClaw 的价值恰恰在这里:它把智能体从“单次表演”变成“可运行的体系”,把你从一个对话框用户,推向了一个 AI 团队的管理者。
所以它被称为“元智能体”,并不是因为它更玄,而是因为它干了一件更现实的事:
把智能体这门手艺,从少数工程师的装配工作,变成了一套可被组织、可被迭代、可被管理的基础设施。
当 AI 开始不只是帮你做事,而是帮你“搭一套做事的系统”,很多人以为的“未来”,其实已经在门口了。
个人助手 OpenClaw 到企业级 OpenClaw,还有多远?
有个朋友上周跟我说,他用 OpenClaw 把自己的工作效率提高了三倍——自动整理会议纪要、自动回复常见客户消息、自动跑数据脚本,甚至把浏览器操作都托管给 AI 去做。
他兴奋地跟公司 IT 部门分享了这个"神器",结果换来的是一封措辞严肃的邮件:"请立即卸载,未经审批的自动化工具不得接入公司网络。"
这件事让我想了很久。明明是同一套系统,个人用起来如虎添翼,企业却避之不及——这中间到底隔了什么?
一、一个越来越明显的问题
2026 年初,OpenClaw 凭借"本地执行、完全开源、多模型兼容"的特性在开发者圈子里彻底炸了——GitHub 星标突破 30 万,各种私有化部署教程满天飞,技术社区的热度堪比当年 Docker 刚出来那会儿。
很多人已经在靠它干这些事情了:
自动回复 WhatsApp / Telegram 消息,再也不用盯着手机
让 AI 帮写代码、整理文件,把重复劳动全甩出去
调用 Skills 执行脚本,一句话完成过去要手动折腾半小时的任务
连接 Playwright 自动操作网页,表单填写、数据抓取统统自动化
玩过之后你会有一种感觉:这东西稍微再加强一点,其实已经很像企业自动化系统了。
但现实是,大多数企业的 CTO 和 CIO 看到它,第一反应不是兴奋,而是皱眉头。
OpenClaw 离企业级平台,到底还差多少?
二、先把这个东西搞清楚
很多人用 OpenClaw 用得很爽,但说不清它到底是个什么东西。
从架构上看,它本质是一个 AI 消息网关 + 智能体执行框架,核心干了三件事:
第一件:消息统一入口,Gateway,把所有聊天渠道统一起来。 WhatsApp、Telegram、Discord、iMessage、Slack……以前你要开一堆窗口,现在一个 Gateway 全部接管。这解决的是 AI 的"输入层"问题。
第二件:Skills 执行系统,给 AI 装上手脚。 Skills 是 AI 可以调用的能力模块——运行代码、调用 API、操作浏览器、读写文件、查询数据库。以前 AI 只能动嘴皮子,有了 Skills,它才真正能动手干活。
第三件:Agent 决策层, AI 自己想清楚该做什么。 Agent 推理层坐在 Skills 之上,负责理解你说的是什么意思、决定该调哪些工具、按什么顺序执行。这一步让 OpenClaw 从聊天机器人进化成了行动型智能体。
三件事加在一起,你大概能明白为什么那么多人觉得它"很像企业系统"——因为它确实已经具备了企业自动化平台的底层逻辑。
三、个人版 vs 企业级:残酷的对比
但"底层逻辑像"和"真的能用"之间,差距往往比你想象的大。
我整理了一个对比表,直接说清楚问题在哪:
维度 | 个人版现状 | 企业级要求 |
|---|
核心目标 | 极致效率、个性化定制 | 稳定、可审计、标准化、降本增效 |
部署方式 | 本地单机跑 | 集群部署、高可用、容灾备份 |
权限管控 | 拿本机最高权限随便用 | 最小权限原则、细粒度角色控制 |
数据流向 | 数据留本地,加密全靠自己 | 全链路加密、数据隔离、私有大模型 |
容错机制 | 出错就停,等人来修 | 自动回滚、异常熔断、人工审批流 |
成本结构 | 开源免费,只需硬件 | 隐性成本极高(维护、培训、风险兜底) |
看完这张表,你会发现个人工具和企业系统的目标根本就不一样。个人追求"好用",企业追求"可控"。这不是修修补补能解决的问题,而是两套不同的设计哲学。
四、五道真实的门槛
说"差距大"是泛泛而谈。我们来拆解一下,OpenClaw 企业化路上具体要跨过哪五道坎。
第一道:权限体系
这是最基础、也最容易被忽视的问题。
企业系统必须回答一个问题:谁可以做什么? 哪个员工能访问哪些数据?哪个部门可以调用哪些 Skill?哪些 API 调用需要审批?
OpenClaw 目前的权限体系非常轻量,几乎就是"有账号就能用"。对个人开发者来说这是自由,对企业来说这是风险敞口。想进企业场景,必须从头搭一套完整的 RBAC 体系——用户、角色、权限、组织架构,一个都不能少。
第二道:审计与合规
企业最怕的不是系统崩,而是不知道发生了什么。
金融、医疗、国企这类强监管行业,监管机构要求你能回答:谁在什么时间触发了 AI?AI 调用了哪些工具?改了哪些数据?出了问题能不能复现?
这叫审计日志(Audit Log),是合规的基本门槛。目前 OpenClaw 几乎没有完整的审计体系,这意味着企业 IT 根本无法证明"系统合规运行"。不是不想用,是用了没法向监管交代。
这也是为什么 OpenClaw 在企业里常常被打上"影子 IT"的标签——不是坏东西,但是不透明的东西。
第三道:稳定性与容错
个人工具崩了你重启一下,顶多耽误半小时。企业流程崩了是另一回事——财务报销系统出错,供应链下单系统宕机,后果可能牵一发动全身。
更麻烦的是 AI 的幻觉问题。聊天场景下 AI 答错了你纠正一下就行,但企业流程要求极高的准确率——你不能让 AI 把"采购 100 台电脑"理解成"采购 1000 台"。
企业级平台必须在架构层面就把容错设计进去:任务队列、重试机制、失败补偿、服务降级、灾备切换。一句话概括:企业系统是为"出故障"而设计的,不是期待它永不出错,而是出了错要能优雅地处理。OpenClaw 目前更多是开发者工具,离这个标准还差很多。
第四道:规模化能力
个人助手服务一个人,企业系统可能要同时服务几百个员工、应对每天数百万次请求。
这背后是一整套平台工程问题:多租户隔离、负载均衡、分布式架构、横向扩展……每一项单独拿出来都是专门的技术方向。
另外还有一个容易被忽视的隐性门槛:人才。配置和维护 OpenClaw 需要有经验的开发者,普通业务人员上手难度极大。企业系统不能依赖"得有一个懂的人守着"这种前提。
第五道:业务建模能力
这是最本质的差距,也是最难补的一道坎。
企业系统不只是自动化,它必须理解业务。工单管理、客户关系、订单履行、审批流程……这些背后需要工作流引擎、数据模型、表单系统、业务规则。
缺了这层,AI 只能帮你执行动作,但没有办法帮你管理业务。就像你有一个执行力极强的助手,但你得把每件事的来龙去脉都跟他解释清楚,因为他不懂你们公司是怎么运转的。
五、其他 AI 产品是怎么过这道坎的
这条路不是没有人走过,我们可以看看参考案例。
Notion AI → Notion for Enterprise: 从单点的 AI 写作功能,一步步演进成知识管理平台,补齐了权限管理、团队协作、安全审计这一整套企业能力。
GitHub Copilot → Copilot Business / Enterprise: 个人版只是代码补全,企业版加入了企业策略管理、代码隐私保护、完整的审计日志,让 CTO 们可以放心在生产环境里用。
这两个案例背后有一个共同规律:单点突破 → 平台化 → 生态化,每一步的核心都不是"更强",而是"更可信"。
六、OpenClaw 的三条可能路线
如果 OpenClaw 要走向企业,大概有三条路可以选:
路线一:坚守极客工具定位 继续轻量、开源、灵活,成为开发者最强的 AI 工具箱,做 AI 时代的 n8n + 命令行自动化平台。这条路最专注,但天花板也清晰。
路线二:进化为自动化平台(中期目标) 加入工作流编排、任务管理、可视化后台,变成 AI 版的 Zapier 或 n8n。短期可以做到的事情包括:插件生态 + API 开放 + 基础权限管理。这条路有清晰的市场空间,也相对务实。
路线三:成为企业智能体操作系统(长期愿景) 在第二条路的基础上,进一步补齐多租户、细粒度权限、完整审计、企业级集成能力,最终变成一个 AI 原生的企业操作系统——员工通过对话完成所有业务操作。这条路最宏大,但也最难。
另外还存在一条"曲线救国"的路——由第三方企业服务商基于 OpenClaw 内核推出企业级发行版,在上面叠加权限沙箱、操作审批流、统一身份认证(SSO)等能力。或者采用"云端大脑 + 本地执行"的混合架构,让数据和控制逻辑分开管理,在安全和能力之间找平衡点。
七、真正的挑战不是技术,是信任
把前面所有的分析加在一起,你会发现一件很有意思的事:那五道门槛,技术上其实都有解法。权限体系、审计日志、容灾架构……这些都是工程问题,有钱有人有时间,都能搭出来。
但企业最终要跨越的,不是技术障碍,而是信任障碍。
企业真正需要的不是更聪明的 AI,而是一个更可预测、更可控、更可追责的执行系统。他们需要能对董事会、对监管机构、对客户说:这套系统在按照我们预设的规则运行,出了问题我们能找到原因,能追责,能改正。
这种信任不是写几行代码能建立的,它需要时间,需要案例,需要在真实企业环境里反复验证。
对于企业的一个实际建议:既不要一刀切封杀,也不要脑子一热全员推广。更务实的做法是划出一个沙盒——在行政、初级代码辅助这类非核心业务里先试,验证价值,建立流程,再逐步扩大范围。小步快跑,比大破大立稳多了。
八、总结
我一直觉得,软件行业正在发生一次很深刻的范式转移。
过去的企业软件是界面驱动的——你学会了这套 ERP 的操作逻辑,在正确的菜单里点正确的按钮,完成正确的业务流程。软件的本质是"界面 + 规则"。
如果 OpenClaw 走到了那一步——AI 理解需求、AI 调用系统、AI 完成流程——企业软件的交互方式可能真的会变:从"点击按钮"变成"一句话完成操作"。那它就不只是一个 AI 工具,而是下一代企业软件的入口。
OpenClaw 的下半场,不再是比谁更"酷",而是比谁更"稳"。只有穿上"盔甲"的小龙虾,才能真正游进企业的深水区。
至于它什么时候能跨过那条线?我觉得答案不只取决于 OpenClaw 自己——也取决于企业这一侧,愿意以多快的速度学会和 AI 系统一起工作。
你觉得 OpenClaw 距离企业级还差哪一步?
你的公司允许员工私自部署 AI 自动化工具吗?有没有被 IT 部门叫去谈话的经历?
复杂的智能体架构,为什么被OpenClaw变成普通人也能使用的工具?
以前我们整理邮件要怎么做?
我们坐在那里,一封一封翻,删,标记,翻,删……花了一个下午,估计还没清完三分之一。
但是最近用OpenClaw,这个事情交给了我的小龙虾。
用飞书给小龙虾发出指令,十分钟后,6000封邮件被自动分类,日历重新整理,重要会议被标记出来。个人全程没有接触一下电脑。
现在想想:"我们那个下午算什么?"
过去的 AI 是:等你提问 → 给你答案
而现在正在出现的 AI 是:理解任务 → 制定计划 → 调用工具 → 自动执行
OpenClaw,就是这股变化里很典型的一种:它不再试图当“最会聊天的 AI”,而是想做一套能持续运行、能真正干活的智能体系统。
一、AI在变:从“聊天”到“执行”
在理解 OpenClaw 之前,先把这几年 AI 的演化脉络捋清楚,会更容易理解它为什么突然“像个物种跃迁”。
1)第一阶段:聊天 AI
代表就是大家熟悉的那些:
它们的能力核心是——回答问题。
你输入,它输出。
输出完,任务结束。
它很强,但它“不会动手”。
2)第二阶段:AI 工具
后来我们又看到一大批“AI + 单功能”工具出现:
它确实能帮你做事,但流程仍然是你在主导:
你把资料丢进去 → 你挑结果 → 你复制粘贴 → 你自己推进下一步。
AI是工具,你是流程引擎。
3)第三阶段:AI 智能体
现在进入第三阶段,关键词变成:执行。
智能体的特点是:它不仅给答案,还能自己把事情推进下去——
理解目标、拆解步骤、调用工具、执行、检查反馈、再执行。
这不再是一个“对话框”,而更像一个可以长期协作的“数字同事”。
二、智能体到底是什么?把它拆开讲清楚
“Agent”这个词被说烂了,但很多人其实并没真正抓住它和聊天机器人最大的差别。
1)从“输入输出”到“循环行动”
传统大模型的工作方式很像考试:
输入 → 输出
智能体更像做项目:
目标 → 规划 → 行动 → 反馈 → 再行动
这是一个持续循环的系统,而不是一次性的回答。
2)智能体的四个核心能力
一个真正能干活的 Agent,通常离不开四种能力:
能力 | 用人话解释 |
|---|
记忆(Memory) | 它记得你是谁、你习惯什么、上次做到哪 |
工具调用(Tool Use) | 它能操作软件、系统、API,而不是只会打字 |
多步推理(Reasoning) | 它能把复杂任务拆成步骤,并按顺序推进 |
自主行动(Autonomy) | 它能自己决定下一步做什么,不用你每一步都指挥 |
比如你说:“帮我整理会议纪要。”
一个智能体不会只回你一句“当然可以”。它会真的去做:
理解会议内容(可能从录音、文字、邮件里读取)
抽出关键结论
整理行动项和负责人
生成总结文档并发到指定群/邮箱
重点是:你不需要每一步都手动指挥。
3)多智能体协作:一个人变成一支团队
更进一步的,是 Multi-Agent:多个智能体分工合作。
比如:
信息收集 Agent:抓资料、找来源
分析 Agent:归纳、对比、判断
写作 Agent:输出成邮件、报告、文案
在 OpenClaw 的社区里,已经有人搭出过“24小时自动运营”的智能体团队:分类消息、回复客户、整理知识库——像一套小型自动化公司。
三、为什么传统智能体开发这么难?
很多人听完 Agent 会觉得“我也想要一个”,但现实是:你真要自己搭一个可用的系统,复杂度非常吓人。
通常你得自己拼一套“AI 操作系统”:
模块 | 需要的东西 |
|---|
LLM 接入 | OpenAI / Claude 等模型接口 |
Agent 框架 | LangChain / CrewAI 等 |
工具系统 | Tool API、权限管理、执行环境 |
记忆系统 | 向量数据库、检索、索引 |
工作流 | 任务调度、状态管理、失败重试 |
UI 界面 | Web、Bot、CLI 等入口 |
消息系统 | WebSocket、队列、推送等 |
说白了:
Agent 很强,但门槛高到几乎把普通人挡在门外。
这也是为什么:大家都在讨论智能体,但真正“用得起来”的并不多。
四、OpenClaw是什么?
OpenClaw的核心定位可以用一句话概括:
它是一套可以通过聊天来指挥、并自动执行任务的 AI 智能体系统。
它能做的事情不是“写一段话”,而是:
读邮件、分类、回复草稿
管理日历、标记重要事项
操作终端、跑脚本、部署代码
整理文件、抓网页、调用 API
更关键的是:你可以在 WhatsApp / Telegram / Discord/飞书/QQ 甚至命令行里,直接指挥它,就像发消息给一个助手。
一个开源项目的爆发
OpenClaw最初由奥地利开发者 Peter Steinberger 在 2025 年发布,期间经历了几次更名:Clawdbot → Claw → OpenClaw。到 2026 年初,它在开发者社区的传播速度非常快,GitHub 增长明显,用户量也迅速扩大。
很多人把它视为:Agent时代比较重要的开源项目之一——原因不在“它最聪明”,而在“它把复杂的东西做成了可用的东西”。
五、OpenClaw最厉害的地方:把智能体架构“产品化”
你可以把 OpenClaw 理解成:它不是发明了智能体,而是把智能体从“工程装配”变成了“普通人能用的工具”。
下面用“架构 → 功能”的方式,把它对齐讲清楚。
1)感知层 → 多平台消息入口
OpenClaw能接入:
WhatsApp
Telegram
Discord
CLI
Web
所有消息先进入 Gateway 网关。
这相当于 AI 的“耳朵”和“嘴巴”:你在哪说话不重要,它都能听懂并回你。
2)决策层 → Agent 大脑(Runtime)
OpenClaw内部有:
它会判断:你要干什么、这是什么类型的任务、下一步该调用什么能力。
这部分就是智能体真正“会做事”的原因。
3)执行层 → Skills 系统(核心中的核心)
OpenClaw最关键的设计,是 Skills。
你可以把 Skills 理解成:AI能调用的能力模块。
例如:
最重要的一点:Skills 是可扩展的。社区已经沉淀了大量 Skills,你给 AI 增加能力的方式越来越像“安装APP”。
这就是OpenClaw把复杂架构变简单的地方:
普通人不需要理解工具调用、权限管理、执行沙箱,只需要“装技能、下指令”。
4)记忆系统 → 持久上下文
OpenClaw会保存:
所以它可以记住你的偏好、延续上次没做完的事、形成长期协作关系。
这让“助手”更像一个持续存在的角色,而不是一次性对话。
5)ClawHub → 技能生态
ClawHub可以理解成 OpenClaw 的“技能市场”。
开启后,AI 能自动发现、自动加载、自动使用技能。
结果就是:你用得越久,它能做的事情越多。
6)SOUL.md → AI人格系统
OpenClaw还有个很有意思的设计:用一个文件 SOUL.md 来定义 AI 的“人格”。
你可以写清楚:
它的沟通方式(直给还是委婉)
它的价值观(重效率还是重稳妥)
它遇到冲突怎么处理(先确认还是先执行)
这背后其实是一个很现实的问题:
当 AI 开始替你“动手”,它的性格会直接影响结果。
7)模型无关架构:你想用谁都行
OpenClaw不绑定某一家模型,可以接入:
Claude
GPT
DeepSeek
GLM
Kimi
Ollama 本地模型
这让它更像一个“AI运行平台”,而不是某个模型的附属插件。
六、门槛被拉低后,普通人能怎么用?
当智能体不再是“工程师的玩具”,它就开始变得很现实。
1、上班族
每天早上自动收到:
邮件摘要(哪些必须看,哪些可以忽略)
今日日程梳理(冲突提醒、重点标记)
今日待办建议(按优先级排)
你不需要更努力,只是少了很多“机械整理”。
2、创业者
AI自动:
创业者最缺的不是点子,是时间和精力。智能体干掉的恰好是这些“碎但必须做”的活。
3、开发者
一句话让它自动:
甚至有人已经在实践:用手机指挥树莓派部署网站,用智能体处理投诉工单和保险理赔的材料整理。
这类用法的共同点是:你不再操作工具本身,而是交付目标。
七、别盲目乐观:风险与局限也必须讲
智能体越能“动手”,风险就越真实。
安全机构 Kaspersky 曾对 OpenClaw 做过安全审计,报告里提到过:
另外还有很典型的 Prompt Injection 风险:
如果智能体读取了恶意文档或网页内容,可能被诱导去执行错误操作——轻则误删文件,重则泄露数据、执行危险命令。
所以现阶段更现实的结论是:
OpenClaw更适合——
如果你是纯小白,也不是不能碰,但应该从低权限、低风险的任务开始,把权限和边界设置清楚。
八、总结
过去几年,行业热衷于讨论“谁的模型更强”。
但对大多数人来说,更重要的问题其实是:
AI能不能真正帮我把事情做完?
智能体给出的答案是:可以,而且正在变得越来越现实。
而 OpenClaw 这类系统的意义在于:它把原本需要一堆框架、工具、记忆库、工作流才能搭出来的智能体架构,拆成普通人也能理解、也能安装和使用的模块。
当一只“龙虾”用开源的方式,把智能体塞进你的手机里——
真正属于普通人的 AI 时代,才刚刚开始。
这可能是(windows+MC)最详细本地部署Openclaw的方案(原理+实操)
好多兄弟拿着网上那些“一键脚本”教程去跑,结果全是报错:“找不到命令!”“脚本下载失败!”“第四步启动后浏览器打不开!”
讲真的,这些问题我太熟悉了。我自己第一次折腾的时候,光是配环境就搞到凌晨两点,看着满屏红色的报错代码,心态崩得稀碎。特别是咱们在国内,网络环境特殊,直接照搬国外的老教程,那就是纯纯的“自寻死路”。
但是! 只要路铺平了,这事儿其实一点都不难。
这两天我把所有坑都重新踩了一遍,专门针对国内网络环境和国产大模型接口,整理出了一套绝对能跑通的实操方案。不管你是用 Windows 还是 Mac,只要你会复制粘贴,跟着我一步步来,保证你能在电脑上拥有一个真正能“动手”的 AI 助手。
咱们不整虚的,直接开干。
一、OpenClaw到底是啥?先搞清楚你在装什么
在动手之前,咱得先花两分钟弄明白你要装的这玩意儿到底是啥。
很多人是跟风来的,“听说很厉害”、“群里都在聊”,但具体能干啥,其实没太搞明白。
你知道吗?OpenClaw在GitHub上的Star数已经突破31万+了!这是什么概念?它是GitHub历史上增长最快的开源项目之一。
但Star数说了不算。关键是,它到底能帮你干什么?
你用过ChatGPT、Claude对吧?你让它整理桌面文件,它给你列个一二三四五的步骤——但它不会真的动手。
OpenClaw不一样。
它不是聊天机器人,它是一个真正能帮你干活的数字管家。
简单来说,它就是给AI装了一部手机。让AI能通过飞书、Telegram、微信等20多个聊天平台,随时随地帮你干活。
想象一下这样的场景:
你在飞书上说:“帮我把下载文件夹里的PDF按日期归档”,它就真的去扫描、创建文件夹、移动文件。
你在微信上说:“每天早上8点帮我查今日AI新闻”,它就真的每天准时推送。
你在Telegram上说:“读一下桌面上那篇论文,写个500字摘要”,它就真的读了、写了、存好了。
说白了,别的AI只会动嘴,OpenClaw是真的动手。
二、准备篇——你需要知道的4个基础概念
别急着动手。我知道你现在恨不得马上开始,但请给我5分钟。这5分钟的投入,能让你后面节省至少1个小时的困惑。
这就好比玩游戏跳过教程,确实省了两分钟,但打Boss的时候你会被虐得怀疑人生。
2.1 什么是终端/命令行?
这是我被问得最多的问题。“那个黑底白字的东西是不是黑客用的?”
别怕,真的别怕。
终端就像你给电脑发微信。你打字发指令,电脑收到后执行。它不说“好的亲”,直接把结果吐给你。
看到那个窗口了吗?接下来你要做的90%的事情,都是复制粘贴,把我给的命令复制进去,回车,等它跑完。
2.2 什么是Node.js?为什么需要它?
安装OpenClaw的第一步,是安装Node.js。
“这又是啥?OpenClaw不是主角吗?”
好问题。Node.js就像一个翻译官。
OpenClaw是用JavaScript写的,但你的电脑原生不认识JavaScript。Node.js就是把JavaScript“翻译”成电脑听得懂的机器语言。
没有Node.js,OpenClaw就是一堆电脑看不懂的天书。
版本要求:Node.js >= 22。低了它启动不了。
还有一个名词叫 npm,你可以把它理解成Node.js自带的“应用商店”。装Node.js的时候,npm会自动一起装好。
2.3 什么是API Key?为什么需要它?
这个概念非常重要。
结论先行:OpenClaw本身是完全免费的。但它自己没有“大脑”。
它的“大脑”是外接的,来自AI大模型(比如通义千问、Claude、MiniMax等)。
要对OpenClaw说“帮我写首诗”,它需要把你的请求转发给AI大模型。而要调用这些大模型的服务,你需要一个身份凭证,这就是 API Key。
API Key就像健身房的会员卡,器材(大模型)不是你的,但你刷卡就能用。
这里有个容易踩的坑:OpenClaw是AI Agent,每次执行任务可能要来回调用模型好几轮,Token消耗比你手动打字聊天大得多。
刚开始可以在去 硅基流动 (SiliconFlow) 或其他的国内平台注册 。不要一上来就搞Coding Plan计划,都还不知道你能玩openclaw玩多久呢。
所以,给你真正上手后再用的Coding Plan计划。这是专门针对高频调用场景设计的开发者套餐,单价低、用量足,日常运行OpenClaw基本够用,不会动不动就超额报错。
2.4 整体流程预览——就5步,一目了然
步骤 | 干什么 | 预估时间 | 难度 |
|---|
第1步 | 安装Node.js(装翻译官) | 5-10分钟 | 简单 |
第2步 | 安装OpenClaw(装主程序) | 3-5分钟 | 简单 |
第3步 | 运行配置向导 | 5-10分钟 | 中等 |
第4步 | 获取API Key + 配置模型 | 10-15分钟 | 中等 |
第5步 | 首次运行、验证成功 | 2-3分钟 | 简单 |
总计:大约30-45分钟。
三、Mac部署篇——从零开始手把手教你
Mac用户看这里。Windows用户请直接跳到下一章,千万别看混了。
3.1 第一步:安装Homebrew(Mac专属)
Homebrew是Mac整个系统的“命令行应用商店”。
如果你不确定是否安装过,在终端输入 brew --version。如果有版本号,直接跳过这步。
如果没有,复制粘贴下面这行命令,回车:
curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh
注意一个陷阱:输密码的时候,屏幕上不会显示任何字符。没有星号,没有小圆点。这是正常的!只管打完密码,回车就行。
如果卡住不动(国内网络常见问题),请用国内镜像安装:
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
3.2 第二步:安装Node.js
有了Homebrew,安装Node.js就是一行命令的事:
装完后验证一下:
看到 v22.x.x 或更高,完美!
3.3 第三步:安装OpenClaw
主角登场!推荐用官方一键脚本:
curl -fsSL https://clawd.org.cn/install.sh | bash
装完后验证:
看到版本号,你就成功了大半!
如果遇到权限报错(EACCES),在命令前加 sudo 再运行一次即可。
四、Windows部署篇——从零开始手把手教你
Windows用户看这里。Mac的那套命令在这边完全没用,别照搬!把“地基”打好(环境配置)
这步最关键。很多教程一上来就让你敲代码,结果你连工具都没装好,后面全是错。
4.1 第一步:安装Node.js 和git
安装nodjs
Windows不需要Homebrew,直接去官网下载安装包。
访问 https://nodejs.org/en/download
下载 Windows Installer (.msi),选64-bit版本(确保版本>=22)。
双击运行,一路Next,但有一个地方必须注意:
装完后,打开PowerShell(按 Win+R 输入 powershell),输入:
看到版本号就对了。如果慢或者不行就看这个。
安装 Git(下载代码神器)
操作:访问 https://git-scm.com/download/win,下载中文版或英文版都行(建议英文,报错好搜)。
安装:也是一路 Next。有个步骤问你要不要使用 VS Code 作为编辑器,随便选,不影响。
验证:在刚才的 cmd 黑框里输入 git --version,有版本号就 OK。
💡 我的血泪教训: 有兄弟跟我说装完 node 还是提示“不是内部命令”。这通常是因为你没重启命令行窗口!装完软件,必须把 cmd 关掉重新开,甚至重启一下电脑最稳妥。
解决“网络便秘”(国内专属加速)
这步是成败关键。OpenClaw 的包都在国外服务器上,国内直连基本就是转圈转到天荒地老,最后还报错 ETIMEDOUT。
必须执行以下操作:
配置 npm 国内镜像
在命令行(cmd 或 终端)里,务必先执行这条命令:
npm config set registry https://registry.npmmirror.com
这就好比把下载源从美国换到了阿里云,速度直接从几 KB/s 飙升到几 MB/s。
4.2 第二步:安装OpenClaw
极其重要:请以管理员身份打开PowerShell(右键点击搜索结果,选“以管理员身份运行”)。
输入以下命令:
iwr -useb https://clawd.org.cn/install.ps1 | iex
如果遇到“禁止运行脚本”的报错,先执行这行命令解锁:
Set-ExecutionPolicy -Scope CurrentUser -ExecutionPolicy RemoteSigned
输入 Y 确认,然后重新执行上面的安装命令。
装完后验证:
五、通用配置篇——配置向导 + API Key + 首次运行
不管你是Mac还是Windows,走到这一步,接下来的操作完全一样。
5.1 运行配置向导
在终端/PowerShell输入:
openclaw-cn onboard --install-daemon
这会启动一个互动向导,一步步问你问题。
工作区路径:直接回车,用默认。
选择AI模型,下面的步骤不要选择错了:
输入地址和APIkey和模型,下面这些是关键,千万不要搞错了。
没有API Key可以去注册:
打开 https://cloud.siliconflow.cn/i/nRDJFg4z
注册/登录 -> API Keys -> 创建新的API Key。
复制下来,粘贴到终端里。
选择模型,目前我用Pro/zai-org/GLM-5 还可以。
端口配置:直接回车,默认18789。
通信通道:先选“跳过”,后面进阶篇再讲。
安装守护进程:输入 Y,让它后台运行。
5.2 首次运行——见证奇迹的时刻
所有准备工作完成!现在启动引擎:
openclaw-cn gateway --port 18789
看到 Gateway is running on port 18789 字样,就说明成功了。
不要关闭这个窗口(除非你装了守护进程)。
打开浏览器,访问:
如果你看到了一个干净的聊天界面,在输入框里打字:
“你好,介绍一下你自己”
太棒了!AI回复了。这不是网页上的聊天工具,这是跑在你自己电脑上的AI代理。你的数据不出设备,完全掌控在自己手里。
从复制第一行命令到听见AI第一句回复,这30分钟,你跨过了31万人给它点Star之前的那道门槛。
六、进阶玩法——从“能用”到“玩出花”
装好了只是开始。现在的你只发挥了它20%的能力。如果这个没看懂,后面有文章会分享详细的操作。
6.1 接入飞书(真正的杀手锏)
你肯定不想一直坐在电脑前对着浏览器说话吧?
想象一下,你躺在沙发上,用手机飞书对它说“帮我整理桌面PDF”,它在电脑后台默默干活,干完了给你回个消息。这才是数字管家!
简要步骤:
飞书开放平台 (open.feishu.cn) 创建自建应用。
获取 App ID 和 App Secret。
配置权限(批量申请 im:message 等相关权限)。
关键顺序:先在OpenClaw里运行 openclaw-cn channels add 添加飞书渠道,填好ID和Secret,并确保网关正在运行。
回到飞书平台,配置“事件订阅”,选长连接,添加事件 im.message.receive_v1。
发布应用。
现在,去飞书里搜你的机器人名字,发句“你好”,它秒回!
6.2 技能扩展(Skills)
OpenClaw有个超酷的机制叫 Skills。
就像手机装App一样,给OpenClaw装个Skill,它就多一项本事。
安装命令很简单,比如:
openclaw-cn skills install @community/calendar-manager
七、写在最后
说实话,写这篇教程花了我整整一周。每一个报错,都是我自己或读者真实踩过的坑。
技术的最大壁垒,从来不是技术本身,而是那些写教程的人,忘了什么叫“从零开始”。
OpenClaw的“Open”,不只是开源,更是打开。
打开一扇门,让每个人都能拥有自己的AI助手。
你不需要是程序员,不需要懂代码。你只需要会打字,然后告诉它你需要什么帮助。
原来你觉得遥不可及的AI管家,现在就在你的电脑上运行着。
希望大家都能吃上AI时代的大龙虾!
OpenClaw深度拆解:不画流程图,自动化如何轻松实现?
最近一直在折腾 OpenClaw 的时候,实操完之后就在想这到底是怎么实现的?
未必我们用coze、Dify低代码平台或LangGraph等开发框架开发的智能体就可以淘汰了?
我第一反应其实挺质疑的:
这东西连个可视化编排界面都没有,拿什么做流程?
研究了一段时间才发现——问题根本问错了方向。
OpenClaw 从一开始就不是靠“画流程”来实现自动化的,它走的是另一套思路:你只说目标,系统自己想办法把路走出来。
这篇文章就把它的底层逻辑拆一拆:为什么它跟扣子、LangGraph 看起来都在做“自动化”,但其实不是一条路。
一、先说扣子和 LangGraph:它们为什么离不开“流程”
1)扣子(Coze)这类工具:画布连线式
扣子本质是让你在画布上连节点、拉线:
HTTP 请求节点 → 代码节点 → LLM 节点 → 输出节点
每一步做什么、输入输出怎么传、失败怎么兜底……都需要你提前定义好。
它的优点也很明确:确定性强、可审计。你画出来的东西基本就是最终执行路径。
但前提是:你得先在脑子里把流程想清楚,然后把它“翻译”成节点图。
很多时候,真正费劲的不是工具,而是这个“翻译”。
2)LangGraph:把流程图写进代码里
LangGraph 更进一步,它让你用 Python 声明节点和边,本质还是一个有向图(DAG 或带环图),适合需要精确控制状态迁移的场景。
团队里只要有人能写代码,这套非常顺——因为它把“流程”变成了可版本管理、可测试的东西。
二、核心差别:三者的默认假设根本不一样
扣子 / LangGraph 有个共同前提:
你知道该怎么做,只是需要工具帮你落地执行。
OpenClaw 的前提是另一句:
你只知道想要什么结果,让 Agent 自己想怎么做。
这就是为什么你会觉得它“怎么没有流程图”:
因为在 OpenClaw 里,“流程”不是你画出来的,而是 运行时被 Agent 动态规划出来的。
三、OpenClaw 的实际架构:五层把“对话”变成“自动化”
OpenClaw 的运行时大致可以拆成五层(理解这个结构,就理解它为什么不需要画图):
控制接口(消息入口)
WhatsApp、Telegram、Slack、API、Webhook……你从哪发消息都行。
Gateway 控制平面
负责路由、鉴权、调度,把入站请求派发给对应的 Agent 实例。
Agent Runtime(推理核心)
LLM 在这里接收任务、拆解步骤、决定调用哪些 Skills。
Skills / Tools 执行层
每个 Skill 是一个能力单元:可以从 ClawHub 安装,也可以自己用 TypeScript 写。
外部系统集成
GitHub、Notion、Gmail、Slack、Linear……通过 Skills 去调用。
注意这条链路里,压根没有“你画的流程图”这个概念。
你给它一句自然语言,Agent Runtime 自己决定:要分几步、用哪些技能、怎么串起来。
四、一条消息是怎么变成一套自动化流程的?
举个很具体的例子。你在 Slack 里发一句话:
每周一早上,扫描 GitHub 里标了 urgent 的 Issue,
在 Notion 里建一个摘要页,
然后把链接发到 #dev-team 频道
OpenClaw 内部大概会经历这么几步:
第一步:任务理解
Agent 会把这句话拆成几个子目标:
第二步:Skills 匹配
Agent 会去检索本地和 ClawHub 的 Skills 注册表:
有没有 GitHub Skill?
有没有 Notion Skill?
有没有 Slack Skill?
缺的话,会提示你安装/授权。
第三步:Pipeline 组装
OpenClaw 会用一个内部叫 “Lobster” 的 Workflow Shell,把多个 Skill 串成执行链,并把“每周一早上”绑定成 Cron 触发器。
第四步:持久化运行
配置保存下来,之后每周一按时跑,跨会话保持状态。
这里最关键的一点是:
你只做了“说出目标”这一步。剩下的触发器、集成选择、步骤编排,都是 Agent 自动补齐的。
五、Skills 机制:OpenClaw 真正的“可扩展性”来源
如果说扣子靠节点市场,LangGraph 靠代码能力,那 OpenClaw 的扩展核心是 Skills。
你可以把 Skill 理解为“带元信息的函数”:
有名字、描述
有参数 schema
Agent 可以通过语义匹配决定要不要调用它
比如你可以用 TypeScript 写一个读取 GitHub Issues 的 Skill:
// 一个读取 GitHub Issues 的 Skillexport const getUrgentIssues = defineSkill({name: 'get_urgent_issues',description: 'Fetch GitHub issues labeled urgent',params: { repo: z.string() },run: async ({ repo }) => {// 调 GitHub API,过滤 labelreturn octokit.issues.list({ repo, labels: 'urgent' })}})
写完发布到 ClawHub,别人(或者 Agent 本身)就能按需调用。
这点跟 LangChain 的 Tool 很像,但 OpenClaw 这套更强调 “社区注册表 + 自动发现”:Agent 不只是“能用工具”,而是“会找工具”。
六、跟扣子、LangGraph 的差异到底在哪里?
一句话可能说不透,简单拉个对比维度:
维度 | 扣子 / LangGraph | OpenClaw |
|---|
编排方式 | 可视化节点 / 代码 DAG | 自然语言 + Agent 动态规划 |
流程控制 | 确定性,你写死的 | LLM 运行时决策 |
扩展方式 | 插件市场 / 代码节点 | Skills + TypeScript + ClawHub |
触发器 | 需手动配置 | Agent 根据描述自动绑定 |
记忆/状态 | 需手动配置存储节点 | 内置跨会话持久记忆 |
运行环境 | 云端托管为主 | 本地优先,支持自托管 |
可审计性 | 强,流程可视化 | 弱,需查 Agent 执行日志 |
编排方式
流程控制
扩展方式
触发器
扣子 / LangGraph:你手动配
OpenClaw:Agent 根据描述自动绑定
记忆/状态
运行环境
扣子:云端托管为主
OpenClaw:本地优先,支持自托管
可审计性
泼盆冷水:它的软肋在哪?
OpenClaw 并非万能。因为流程是 Agent 动态规划的,这意味着“不确定性”,而且非常消耗token。
如果你的场景是金融对账、法务合规,每一步都不能差分毫,那请死心塌地用 LangGraph。但如果你的需求还在早期、经常变动,或者你只是想搞个个人助理来处理零散的同步任务,OpenClaw 的开发效率简直是降维打击。
七、什么场景下 OpenClaw 会更顺手?
根据实际使用,有几个场景 OpenClaw 明显更顺手:
需求还在变的早期阶段。 你还不确定整个自动化流程长什么样,但想先跑起来验证。用自然语言迭代比改节点图快得多。
多系统联动,集成点多但逻辑不复杂。 比如"把 Notion 数据库里打了 done 标签的条目同步到 Linear,然后关掉对应的 GitHub Issue",这种事 Skills 拼一下就行,不值得建一套编排流程。
个人效率工具,对可靠性要求不是极致的。 用来替代手动操作,偶尔出个意外重跑一次,可以接受。
八、总结
扣子是"你画流程,AI 执行";
LangGraph 是"你写图,AI 沿着走";
OpenClaw 是"你说目标,AI 自己想路"。
没有高下之分,看你的场景更需要哪种控制粒度。
如果你的团队已经在用扣子或 LangGraph 跑稳了生产流程,OpenClaw 很可能不是替代品,而是可以并存的补充——专门处理那些不值得认真"建流程"、但又确实需要自动化的零散任务。
永久免费!OpenClaw 提取网页的终极方案实测,Jina、Scrapling、web fetch 谁更强?
很多人以为,让 AI 干活最贵的是模型调用费。其实不然,真正的“吞金兽”往往是网页抓取。你让 AI 总结一篇技术博客,它可能还没开始思考,光是读取网页就消耗了上万 Token。我随手测了几个主流技术站点,普通文章返回的 HTML 往往包含 8000–15000 Token,但真正有值的正文内容只占 30% 左右。剩下的全是导航栏、侧边推荐、广告脚本、评论区代码——这些噪音不仅浪费钱,还会干扰模型的判断,让它产生幻觉。更头疼的是反爬。当你想抓点 Substack 的深度长文,或者参考一下微信公众号的行业分析时,普通的 fetch 工具直接报错 403,连页面影子都摸不到。既然痛点这么明显,有没有一套永久免费、能抗反爬、还能把内容洗得干干净净的方案?今天,我就在 OpenClaw 这个本地优先的 AI 自动化平台上,把目前最火的三个选手拉出来实测:Jina Reader、Scrapling 和 Claude 内置的 web_fetch。咱们不玩虚的,直接上代码和运行日志,看看谁才是那个“终极解法”。在 OpenClaw 的工作流里跑了几圈后,这三个工具的短板暴露无遗:- web_fetch 的“裸奔”困境: 它是 Claude 的原生工具,主打一个“零配置”。但在 OpenClaw 里实测发现,它返回的是未经处理的原始 HTML。对于简单的 GitHub README 还行,一旦遇到稍微复杂点的页面,有效正文被淹没在噪音里,Token 浪费极其严重。更致命的是,面对 Substack 或微信公众号这种带反爬机制的站点,它基本是直接歇菜,返回空值或报错。
- Jina 的“限额”焦虑: Jina Reader (r.jina.ai) 确实是神器,一行 URL 前缀就能吐出极度干净的 Markdown,格式完美,几乎不需要二次清洗。但是,它的免费额度卡在 200 次/天。对于个人偶尔查查资料够用,但如果你是个高产的创作者,或者需要批量处理数据,这个限额就像悬在头顶的达摩克利斯之剑,一不小心就耗尽,工作流直接中断。
- Scrapling的门槛与维护:像 Scrapling 这种偏工程化的抓取工具,能力更全面,适配面也更广。不过它对接入方式、运行环境、维护习惯会更挑一点:你要么写脚本,要么封装技能,要么做容错策略。
对比下来,没有银弹。Jina 快但有限额,Scrapling 强但有门槛,web_fetch 方便但太弱。想要既省钱又稳定,必须搞分级路由。2.1 Jina Reader (r.jina.ai)- 出身:Jina AI 官方维护,GitHub 9.7k+ Star,Apache-2.0 开源。
- 必杀技:无需注册,无需 API Key。只要在 URL 前加 https://r.jina.ai/,它就能把任意网页(包括 SPA 动态渲染页、PDF)转为 LLM 友好的 Markdown。
- 额外能力:支持 s.jina.ai 搜索并返回 Top 5 全文;自动给图片加 Alt 描述。
- 出身:GitHub 上近期爆火的自适应爬虫框架,Star 数已突破 2.2 万(截至 2026 年 3 月数据),BSD-3-Clause 开源。原作者已明确宣布正在将其打造为 OpenClaw 的原生 Skill。
- 必杀技:拥有三种 Fetcher 模式。轻量 HTTP 模式速度快;StealthyFetcher 能绕过 Cloudflare 等常见反爬;DynamicFetcher 则是完整的浏览器自动化,专治各种 JS 渲染。
- 独门绝技:网站改版后,它能自动重新定位目标元素,不用你天天修 XPath。它还内置了 MCP Server,能直接跟 Claude/Cursor 对话。
- 必杀技:零配置,OpenClaw 工作流里拖个节点就能用。
我在 OpenClaw 中搭建了并行测试工作流,针对三类典型场景进行了压力测试。以下是真实跑出来的数据对比:对象:GitHub README、Python 官方文档
三者都能完成。但 web_fetch 返回的内容里夹杂了大量 <script> 和 CSS 类名,导致后续 LLM 处理时 Token 消耗多了近 3 倍。Jina 和 Scrapling 输出的 Markdown 几乎一致,干净利落。对象:Substack 深度文章、Medium 付费墙外文章- Jina:表现最佳,秒开,格式完美。是第一优先选择。
- web_fetch:直接报错 Connection timeout 或返回 403,完全不可用。
- Scrapling:使用 StealthyFetcher 模式,耗时约 3 秒,成功绕过验证,内容完整。虽然慢了点,但能抓到就是胜利。
- Scrapling (DynamicFetcher):提供完整的浏览器控制,等待 JS 执行完毕后再提取,效果最强。
- Jina:依赖后端的 Puppeteer 集群,表现稳定,但偶尔会遇到超时。
- web_fetch:局限性明显,经常只能抓到 Loading 状态的骨架屏。
四、关键发现:Scrapling 的“杀手锏”——微信公众号这次实测最大的惊喜,来自 Scrapling 对 微信公众号 (mp.weixin.qq.com) 的支持。现状很骨感:微信公众号有着极其严格的反爬机制。在测试中,Jina Reader 直接返回 403 Forbidden,web_fetch 更是连请求都发不出去。以往我们想引用公众号文章,只能手动复制粘贴,或者忍受残缺的摘要。Scrapling 的突破:通过在 OpenClaw 中调用 Scrapling 的 StealthyFetcher,并配合简单的 User-Agent 伪装,我成功完整获取了多篇最新发布的公众号文章正文,包括所有的图片链接、加粗强调和列表结构。# OpenClaw 中的 Python 脚本节点示例
from scrapling import StealthyFetcher
import html2text
def fetch_wechat(url):
# 启动 stealthy 模式,自动处理 Cookie 和指纹
fetcher = StealthyFetcher(auto_match=True)
page = fetcher.fetch(url)
# 转换为 Markdown
h = html2text.HTML2Text()
h.ignore_links = False
markdown_content = h.handle(page.text)
return markdown_content
# 实测 mp.weixin.qq.com/s/xxx 链接,返回正常
意义:这一单点能力,直接打通了中文内容创作的最大数据源。对于需要做行业调研、竞品分析的国内用户来说,Scrapling 不再是“可选项”,而是必备项。五、重磅升级:Scrapling Agent-Skill 原生集成指南如果你认为上一节的 Python 脚本已经够强了,那 Scrapling 刚刚推出的 Agent-Skill 包可能会让你大吃一惊。根据 Scrapling 项目最新的 agent-skill 目录结构,作者专门为 OpenClaw 等 AI 代理设计了标准化的技能包。这意味着,你不再需要手写复杂的 Python 脚本,只需通过简单的命令安装,就能让 OpenClaw 直接“学会”如何调用 Scrapling 的所有高级功能。Scrapling 的 Agent-Skill 遵循 OpenClaw 的标准规范,核心是一个名为 SKILL.md 的文件。这个文件不仅仅是文档,更是 AI 的“操作手册”。---
name: scrapling-web-scraper
description: 自适应网页抓取框架,支持反爬虫绕过、动态页面处理和智能元素追踪
version: 1.0.0
compatibility: openclaw
requires:
bins: [python, pip]
env: [SCRAPLING_API_KEY]
---
# 使用说明
本技能允许你使用 Scrapling 的强大功能抓取网页。
## 可用指令
- **隐身模式**: 当遇到 Cloudflare 或其他反爬机制时,自动启用 StealthyFetcher。
- **动态渲染**: 对于 SPA 页面,自动切换 DynamicFetcher 等待 JS 执行。
- **智能追踪**: 即使网站改版,也能自动重新定位目标元素。
## 示例
"用 Scrapling 抓取 https://example.com 的产品列表,提取名称、价格和评分"
- scrapling_skill.py:封装好的 Python 逻辑,处理所有复杂的底层调用。
- config.json:预设的配置参数,如默认超时时间、重试次数等。
- handlers/:针对不同场景(如电商、新闻、社交媒体)的专用处理模块。
# 1. 克隆 Scrapling 仓库
git clone https://github.com/D4Vinci/Scrapling.git
# 2. 将 agent-skill 目录复制到 OpenClaw 技能目录
# 全局安装(所有项目可用)
cp -r Scrapling/agent-skill ~/.openclaw/skills/scrapling-skill
# 或者项目级安装(推荐,便于版本管理)
cp -r Scrapling/agent-skill ./skills/scrapling-skill
方法二:ClawHub 一键安装(最便捷,适合新手)如果该技能已发布到 ClawHub 市场(截至 2026 年 3 月,Scrapling 已成为热门技能),你可以直接搜索安装:# 搜索技能
openclaw search "scrapling"
# 安装技能
openclaw install scrapling-web-scraper
# 如果需要,配置相关密钥
openclaw configure scrapling-web-scraper
方法三:使用 add-skill 工具(跨平台通用)# 安装工具
npm install -g add-skill
# 直接添加
npx add-skill https://github.com/D4Vinci/Scrapling/tree/main/agent-skill
安装完成后,你需要确保 OpenClaw 能正确识别它。{
"skills": {
"scrapling-web-scraper": {
"enabled": true,
"path": "~/.openclaw/skills/scrapling-skill",
"config": {
"stealth_mode": true,
"solve_cloudflare": true,
"proxy_rotation": "auto"
}
}
}
}
export SCRAPLING_API_KEY="your_api_key_here"
export SCRAPLING_PROXY_POOL="http://proxy1:port,http://proxy2:port"
# 重启 OpenClaw
openclaw restart
安装好 Skill 后,你不再需要写代码。直接在 OpenClaw 的对话框或工作流中使用自然语言指令即可:- “用 Scrapling 技能抓取 https://example.com 的产品列表,提取名称、价格和评分。”
- “使用 Scrapling 的隐身模式绕过 Cloudflare,抓取这个需要登录的网站数据。”
- “用自适应解析功能监控这个网站,如果页面结构变化自动重新定位元素。”
- “设置定时任务,每天上午 9 点抓取竞争对手价格并生成报告。”
- “先用 Scrapling 抓取数据,然后用数据分析技能生成可视化图表,最后用邮件技能发送报告。”
Scrapling 功能 | OpenClaw 调用方式 | 示例指令 |
|---|
StealthyFetcher | 隐身模式抓取 | “用隐身模式抓取受保护的网站” |
DynamicFetcher | 动态页面处理 | “抓取需要 JavaScript 渲染的页面” |
自适应解析 | 智能元素追踪 | “监控这个页面,元素移动时自动调整” |
Spider 框架 | 批量爬虫任务 | “抓取这个网站的所有产品页面” |
MCP 服务器 | AI 辅助抓取 | “帮我分析这个页面的最佳抓取策略” |
- 技能未加载:运行 openclaw skills list 检查,若未显示则运行 openclaw skills reload。
- 403 错误:在指令中显式要求 --stealth-mode true 或配置 --proxy-rotation auto。
- 动态页抓取失败:指定 --fetcher-type dynamic 并启用 --network-idle true。
- Token 优化:指令中明确范围,如“只抓取 .price-table 类内的数据”,减少无效信息传输。
- 容错处理:设定备用策略,“如果抓取失败,尝试备用 URL 或使用移动端页面”。
- 合规第一:始终提醒 AI“检查 robots.txt,遵守网站抓取规则”。
别指望一个工具打天下。在 OpenClaw 里,结合原生 Skill 的优势,我设计了一套分级路由策略,将成本降到最低,成功率拉到最高:💡 域名路由技巧:
在 OpenClaw 的工作流开头加一个判断节点:检测到 URL 包含 mp.weixin.qq.com → 直接调用 Scrapling Skill,跳过 Jina。这样既避免了 Jina 的无效尝试(反正它也抓不到),又节省了宝贵的每日配额给其他英文站点。最后,给大家两套在 OpenClaw (v2026.2+) 中的具体落地配置,涵盖从“零代码”到“深度定制”的需求。- 在 OpenClaw 工作流中添加一个 HTTP Request 节点。
- URL 填写模板:https://r.jina.ai/{{input_url}}。
7.2 Scrapling Agent-Skill 接入(自然语言版)- 按照第六节的方法安装 scrapling-web-scraper 技能。
- 在 OpenClaw 的聊天窗口或工作流的“AI 指令”节点中,直接输入:
- “请使用 scrapling-web-scraper 技能,访问 {{input_url}},提取正文内容并转换为 Markdown。如果是微信公众号链接,请自动开启隐身模式。”
- OpenClaw 会自动加载技能包中的 SKILL.md 上下文,调用底层的 Python 脚本执行任务,并返回结果。
7.3 Scrapling 接入(Python 脚本版 - 备选)如果你需要更细粒度的控制,依然可以使用自定义脚本。- 确保环境已安装依赖:pip install scrapling html2text。
- 添加一个 Python Script 节点,代码如下:
import scrapling
import html2text
# 获取输入变量
url = params.get('url')
# 智能判断:如果是微信,强制使用 StealthyFetcher
if'weixin.qq.com'in url:
fetcher = scrapling.StealthyFetcher(auto_match=True)
else:
# 普通站点用轻量模式,速度更快
fetcher = scrapling.Fetcher()
try:
page = fetcher.fetch(url)
# 初始化 html2text
h = html2text.HTML2Text()
h.ignore_links = False
h.body_width = 0# 不换行,保持段落完整
markdown_text = h.handle(page.text)
# 截断保护
if len(markdown_text) > 30000:
markdown_text = markdown_text[:30000] + "\n\n... (内容过长已截断)"
result = markdown_text
except Exception as e:
result = f"Error: {str(e)}"
# 输出结果
{'content': result}
这套脚本实现了自动分流:遇到微信自动开启隐身模式,普通网站则用高速模式,兼顾了成功率与效率。但请注意,有了 Agent-Skill 后,除非有特殊需求,否则强烈建议优先使用 Skill 方式,维护成本更低。经过这一轮在 OpenClaw 上的深度实测,结论很清晰,就是组合才是王道:Jina、Scrapling 和 web_fetch 并不是竞争关系,而是一条互补的“工具链”。- Scrapling 是厚重的盾牌,能抗能打。特别是它现在拥有了原生的 Agent-Skill 形态,让中文语境下的微信公众号抓取变得像说话一样简单,这让它成为了无可替代的必选项;
- web_fetch 则是随手的螺丝刀,简单场景顺手用一下。
未来的趋势,一定是 AI 与爬虫的深度融合。像 Scrapling 这样自带 MCP 能力、能理解页面结构、且符合 Skills 标准的工具会越来越多。先 Jina,超限换 Scrapling,静态页用 web_fetch,微信号直接上 Scrapling。收藏备用,让你的 AI 助手从此告别“瞎编”,真正实现低成本、高成功率的全网信息获取。
我们拆了OpenClaw的源代码,发现了多Agent并发的秘密
我见过太多人在演示多 Agent 系统的时候,本质上做的是同一件事:开好几个对话窗口,让几个 GPT 互相"聊天",然后说这是 Multi-Agent。这不是多 Agent,这是多个单 Agent 在凑热闹。真正的多 Agent 系统要解决的问题跟这个差远了——它要解决的是:当一个复杂任务需要多种专业能力协同完成时,系统如何稳定、高效、可控地把这件事做完。OpenClaw 是我见过在这个方向上做得比较认真的开源框架之一。今天我想从底层机制讲清楚它到底是怎么运行的,不讲概念,讲原理。一、先说清楚一件事:你对多 Agent 的理解可能是错的有段时间我自己也这么想:多 Agent 嘛,就是多个 AI 模型一起跑,互相传信息,像一个团队一样分工合作。问题一:角色混乱。 你让同一个 Agent 又写代码、又分析数据、又回复客户,上下文很快就乱了。它不知道自己现在是程序员还是客服,结果两件事都没做好。这不是模型能力不够,是架构设计有问题。问题二:上下文爆炸。 多步骤任务里,每一步的输入输出都往上下文里塞。跑到第五步,前四步的内容已经撑满了 context window,模型开始"遗忘",输出质量断崖式下降。问题三:成本失控。 每次推理都带着一整条对话历史,token 用量呈指数增长。跑个稍微复杂的工作流,API 费用能让你怀疑人生。问题四:不可控。 任何一步失败,整个链条断掉。没有重试,没有降级,更没有追踪,就是一个黑盒崩掉了。AutoGPT 当年火的时候,很多人发现跑着跑着就乱套了,原因就在这里——它没有真正解决上面这些问题,只是把单 Agent 的能力拼凑了一下。OpenClaw 的切入点不一样。它的核心主张是:多 Agent 不是让更多模型参与对话,而是把大模型推理能力微服务化。Agent 是一个可执行的独立单元,有自己的角色、自己的记忆、自己的工具权限,通过一套严格定义的通信协议跟其他 Agent 协作。这更像是一个组织架构设计问题,而不是一个模型调用问题。二、在 OpenClaw 里,Agent 到底是什么?这个问题比你想的重要。很多框架里,Agent 只是一个 Prompt 的别名——换个 system message,就叫另一个 Agent 了。最底下一层是 LLM(大脑),就是具体调用的模型,可以是 GPT-4、Claude、本地的 Llama,可插拔,可替换。中间一层是 Skill(能力)。Skill 是独立注册的功能模块,比如"执行 Python 代码"、"控制浏览器"、"检索知识库"。它们不属于任何特定 Agent,按需调用。最上面一层才是 Agent(角色封装),它把 LLM、Skill、记忆和执行策略组合在一起,形成一个有具体角色的可执行单元。所以一个 Agent 完整的内部结构大概是这样的:Role → 角色定义(你是谁)
Instruction → 行为约束(你能做什么,不能做什么)
Context → 当前上下文(你现在知道什么)
Skill Binding → 绑定了哪些能力
Execution Policy → 执行策略(最多跑几步,超时怎么处理)
有个关键点要强调:Agent 是"可执行单元",不是"聊天人格"。它更像是一个进程,有生命周期,有状态,有资源限制,有通信接口。你不是在"和它聊天",你是在"调度它执行任务"。OpenClaw 里多个 Agent 可以同时运行,但它们之间不会互相干扰,原因是实现了三层隔离。身份隔离:每个 Agent 有自己的模型配置和 API 密钥。一个 Agent 用 GPT-4,另一个用 Claude,各自独立,互不影响。状态隔离:对话历史完全隔离。Agent A 和用户聊了什么,Agent B 完全不知道。这是防止 Context Pollution(上下文污染)的关键——很多多 Agent 系统最大的问题就是不同 Agent 的上下文互相污染,导致输出越来越乱。工作隔离:每个 Agent 有自己独立的文件系统区域和记忆存储(在 OpenClaw 里叫 soul.md)。Agent 的"长期记忆"是真正物理隔离的,不是靠 Prompt 里加几个标记来区分。这三层加在一起,让每个 Agent 真正做到了"独立办公"。它们之间的协作,通过接下来要讲的通信机制来实现,而不是靠共享状态。现在来看 OpenClaw 多 Agent 系统完整的运行时架构。自顶向下有六层,我依次讲。用户请求
↓
① Router(路由层) ← 意图识别,决定谁来接
↓
② Planner(任务拆解层) ← 把大任务拆成子任务图
↓
③ Agent Scheduler(调度器)← 决定谁先跑、谁并行、失败怎么办
↓
④ Agent Execution(执行层)← 每个 Agent 跑自己的 ReAct 循环
↓
⑤ Skill / Tool(能力层) ← 真正调用工具、执行操作
↓
⑥ Aggregator(汇总层) ← 合并结果,返回给用户
这六层不是随便分的,每一层的职责边界都很清晰,而且遵循一个原则:上层决策,下层执行,层与层之间只通过接口通信,不共享内部状态。类比一下:Router 是公司前台,Planner 是项目经理,Scheduler 是排班系统,Agent 是员工,Skill 是员工手里的专业工具,Aggregator 是最后的汇报会。每个角色都知道自己的边界在哪。第一层:Router — 谁来决定"这件事交给谁"Router 是所有外部请求的入口。用户的消息,不管来自 Telegram、飞书还是 API,都先经过 Router,然后才进入 Agent 体系。Router 干的事情本质上是两件:意图识别和任务路由。它不是一个简单的关键词匹配,而是"轻量分类模型 + Prompt 规则系统"的组合。识别出"这是一个写代码的请求",然后路由到 Code Agent;识别出"这是一个数据分析请求",路由到 Analysis Agent。OpenClaw 里 Router 有一套 8 级优先级路由机制,从最精确的"绑定到特定 Agent",到最兜底的"默认 Agent 处理",每一级都有明确的匹配规则。这保证了每一条消息都有确定性的去向,不会因为"没人接"而丢失。这个设计有个很重要的价值:可追踪性。每一条消息从进入系统的第一步开始,就有了完整的路由记录。出了问题,你知道从哪里查。第二层:Planner — 任务拆解是一次推理,不是写配置Planner 是整个多 Agent 系统能跑起来的起点,也是 OpenClaw 和传统工作流引擎最本质的区别。传统工作流引擎(比如 n8n、Airflow)里,任务拆解是人写配置文件来定义的。你要告诉系统"第一步做什么、第二步做什么、分支条件是什么",这是人的工作。OpenClaw 里,Planner 本身是一个 LLM。用户说"帮我分析这个项目,并生成一份报告",Planner 会把这句话拆成:任务图(DAG):
① 获取项目数据 → 无前置依赖,可以立刻开始
② 分析代码结构 → 依赖①的结果
③ 生成结构化总结 → 依赖②的结果
④ 排版输出报告 → 依赖③的结果
这个拆解过程本身是一次 LLM 推理,输出的是结构化的 DAG JSON,交给下一层的 Scheduler 来执行。这意味着 Planner 能处理模糊的、自然语言描述的任务,不需要用户提前把任务拆好。任务分解是 AI 的工作,不是用户的工作。这也带来了一个连锁好处:任务图是动态生成的,可以根据任务内容灵活调整,不是提前写死的固定流程。第三层:Scheduler — OpenClaw 的"灵魂组件"如果说 Planner 是项目经理,那 Scheduler 就是排班系统,负责把任务图翻译成实际的执行顺序。- 并行(Parallel):所有任务同时开跑,互不等待
- 条件执行(If/Else):根据上一步的结果决定走哪条路
- 递归执行(Loop):某个步骤循环执行直到满足条件
实际工作流里用得最多的是 DAG 调度——有依赖关系,但可以部分并发。DAG 调度的核心逻辑是:把 Planner 生成的任务图做一遍拓扑排序,所有入度为 0(没有前置依赖)的节点,同时发给对应的 Agent 执行。某个节点完成后,它的下游节点入度减一,减到 0 了就立刻触发。实现上用的是 asyncio.wait(FIRST_COMPLETED)——同时监听所有在跑的任务,任意一个完成就立刻处理,解锁下游,而不是傻等所有任务都完成再继续。async def execute_dag(self, dag: TaskDAG) -> dict:
completed = {}
pending = set(dag.get_ready_nodes()) # 入度为 0 的节点
in_flight: dict[str, asyncio.Task] = {}
while pending or in_flight:
# 同时 dispatch 所有 ready 节点
for node_id in pending:
task = dag.nodes[node_id]
agent = self._select_agent(task)
coro = self.bus.request(
f"task/{agent.id}",
TaskMessage(task, context=completed)
)
in_flight[node_id] = asyncio.create_task(coro)
pending.clear()
# 等待任意一个完成,立刻处理
done, _ = await asyncio.wait(
in_flight.values(),
return_when=asyncio.FIRST_COMPLETED
)
for fut in done:
node_id = _find_key(in_flight, fut)
completed[node_id] = fut.result()
in_flight.pop(node_id)
# 解锁下游
pending |= dag.unlock_downstream(node_id, completed)
return completed
这段代码不复杂,但它实现了一个很重要的效果:在满足依赖约束的前提下,最大化并发度。该并行的时候绝不串行,该等待的时候绝不乱动。容错方面,Scheduler 内置了 WatchDog 协程。如果某个 Agent 超时未回复,任务会被转入 Dead Letter Queue(死信队列),触发重试或降级策略。单个 Agent 的失败不会让整个工作流崩掉。第四层:Agent 执行 — 每个 Agent 是一个持久运行的进程到了执行层,才是真正到了 Agent 干活的地方。这里有一个很多人会忽略的设计细节:在 OpenClaw 里,每个 Agent 不是一个函数,而是一个持久运行的 asyncio 事件循环。它不是"被调用一次,返回结果,结束",而是一直在跑,持续监听自己的消息队列(Mailbox),有任务来了就处理,处理完了等下一个。这个区别非常关键,它是真并发的基础——多个 Agent 可以同时在不同的事件循环里处理不同的任务,互不阻塞。class BaseAgent(AsyncRunnable):
def __init__(self, agent_id: str, config: AgentConfig):
self.id = agent_id
self.mailbox = asyncio.Queue() # 私有消息队列
self.working_mem = WorkingMemory() # 短期工作内存
self.reasoner = Reasoner(config.llm) # LLM 推理引擎
self.tool_runner = ToolRunner(config.tools)
self.status = AgentStatus.IDLE
async def run(self):
# 核心事件循环:持续监听邮箱
whilenotself._shutdown:
msg = await self.mailbox.get()
self.status = AgentStatus.RUNNING
result = await self._process(msg)
await self.bus.publish(f"result/{self.id}", result)
self.status = AgentStatus.IDLE
收到任务后,Agent 进入 ReAct 推理循环:① 看当前任务和上下文
② 决定下一步:是调用工具,还是给出最终答案?
③ 如果调用工具:执行工具,把结果写回 working memory
④ 回到①,继续推理
⑤ 直到得出最终答案,把结果发布出去
这个循环最多跑几步是有限制的(max_steps),防止 Agent 陷入死循环。工具调用是沙盒化的,有超时、有重试、有结果校验,不会因为一个工具调用挂掉就把整个 Agent 搞崩。第五层:Skill / Tool — 真正干活的地方很多人会把 Agent 和 Skill 的职责搞混。简单说:Agent 负责决策,Skill 负责执行。Agent 的工作是"决定用什么工具",Skill 的工作是"把这个工具用好"。Skill 在 OpenClaw 里是独立注册的,不属于任何特定 Agent。这是一个微服务式的解耦设计——你可以随时给系统新增一个 Skill(比如"发送邮件"),然后所有有权限的 Agent 都能用它,不需要改任何 Agent 的代码。常见的 Skill 包括:文件操作、浏览器控制(Playwright)、API 调用、Python 代码执行、数据库查询、向量检索……本质上,任何可以被包装成函数调用的操作,都可以成为一个 Skill。这个设计解决了传统框架里一个很蛋疼的问题:能力跟 Agent 绑定死了,想复用就要复制一遍。现在 Skill 是公共资源,Agent 按需取用。第六层:Aggregator — 把碎片拼回完整答案最后一层是结果汇总。多个 Agent 并发跑,各自返回自己那一块的结果,最后需要有人把这些碎片拼成一个完整、连贯的答案。这件事比看起来要复杂。你要处理:不同 Agent 输出的格式可能不一样;有些结果有重叠;有些结果之间有逻辑依赖,不能简单拼接;还有一种情况是某个子任务失败了,结果里有缺口,需要降级处理。Aggregator 在 OpenClaw 里做的是:合并、去重、排序、结构化,最后输出一个对用户来说语义完整的结果。用户看到的是"一次回答",但底层发生的是一场有组织的团队协作。五、Agent 间通信:消息总线是整个系统的神经中枢把上面六层串起来的,是 OpenClaw 的 AsyncMessageBus(异步消息总线)。这个设计有一个非常坚定的原则:Agent 之间不允许直接调用,任何通信都必须经过消息总线。第一,可观测性。所有消息都经过总线,就意味着所有消息都可以被记录、追踪、分析。出了问题,你能完整地复现出整个执行过程里每一条消息是什么、什么时候发的、有没有被正常处理。直接调用就没有这个能力。第二,可替换性。Agent A 调用 Agent B 的时候,它不需要知道 B 的具体实现,只需要知道往哪个 Topic 发消息、期望收到什么格式的回复。这意味着你可以随时替换掉 B 的实现,只要接口不变,A 完全感知不到。sessions_send(点对点私信),就是同步或异步地给另一个 Agent 发消息,等待它回复。适合"我需要你做一件事,做完告诉我结果"的场景,比如项目管理 Agent 问法务 Agent"这个合同条款有没有风险"。sessions_spawn(子代理派生),这个是 OpenClaw 并发能力的关键。它让一个 Agent 可以动态孵化出一个或多个子 Agent,非阻塞地交给它们执行子任务,父 Agent 不等待直接继续干自己的事,子任务完成后回调返回结果。举个直观的例子:用户说"帮我分析这 3 个文件",主 Agent 收到请求后,立刻 Spawn 出 3 个子 Agent,每个负责分析一个文件,三个并行跑,主 Agent 继续等其他任务。三个都跑完了,结果统一汇报给主 Agent 处理。对比串行处理,时间从"3 倍"变成"1 倍",这就是并发效率的来源。# sessions_spawn 的核心逻辑
async def spawn_agent(self, task: Task) -> AgentResult:
child_id = f"{self.id}_child_{uuid4().hex[:8]}"
child = Agent(child_id, config=self.config)
# 非阻塞,父 Agent 不等待
asyncio.create_task(child.run())
result = await self.bus.request(
f"task/{child_id}",
TaskMessage(task),
timeout=30.0
)
return result
sessions_broadcast(广播通知),一对多。不是请求某个 Agent 干事,而是通知所有相关 Agent 某件事发生了。适合配置更新、状态同步这类场景——比如"知识库更新了,所有 Retrieval Agent 注意一下"。消息总线本身用的是 Pub/Sub(发布-订阅) 模式,基于 asyncio.Queue 实现。关键设计是 Fire-and-Forget(发完就走)。发布者把消息投到总线,立刻返回,不等接收方处理完。接收方从自己的私有 Mailbox 里异步消费消息。两边完全解耦,互不阻塞。async def publish(self, topic: str, msg: Message) -> None:
for queue in self._topics.get(topic, []):
try:
queue.put_nowait(msg) # 非阻塞投递
except asyncio.QueueFull:
await self._dead_letter.put(msg) # 满了转死信队列
如果 Agent 正忙,消息在队列里等着,不会丢失。如果队列满了(背压),消息转入 Dead Letter Queue,等待后续处理。整个流程里没有一个强制等待点,这是 OpenClaw 能实现真并发的底层原因。多 Agent 系统里最容易被忽略、但实际上非常重要的一层,是内存管理。一个 Agent 在执行任务时需要"记住"东西。但记什么、记多久、怎么用,这些问题如果没设计好,要么 token 爆炸,要么上下文丢失,要么不同 Agent 之间互相污染。OpenClaw 把 Agent 的记忆分成三层:Working Memory(工作内存),存的是当前任务的上下文——正在处理什么、已经调用了哪些工具、工具返回了什么。它是短暂的,任务结束就清空。好处是每次任务开始都是干净的,不会被历史信息拖累。Episodic Memory(情节记忆),存的是当前会话内的历史轨迹。这个 Agent 在这次会话里做了什么、用户反馈怎么样,这些信息通过 Redis 持久化,可以在同一会话的多轮交互里被引用。Semantic Memory(语义记忆),也就是 soul.md 里的内容,是跨会话的长期知识库。存的是 Agent 的角色设定、过往经验总结、领域知识,通过 Vector DB 支持语义检索。新任务开始时,Agent 会先检索一遍相关的长期记忆,作为上下文的一部分注入。这三层的访问速度、容量、持久性各不相同,用来平衡"记得快"和"记得久"之间的矛盾。多个 Agent 有时候需要共享一些信息,比如"当前任务的总体进度"或者"用户偏好设置",这些放在 SharedContext 里。这里有一个坑值得专门提一下:多个 Agent 同时修改 SharedContext 的同一个 key,会发生写冲突。OpenClaw 用乐观锁来解决这个问题——每个 key 有一个 version tag,写入时检查版本号,如果发现"我读的时候是版本 3,现在要写的时候已经是版本 4 了",说明有别人改过,当前写操作失败,返回 ConflictError,调用方需要重新读取最新值,然后 merge 之后再写。这个机制能保证数据一致性,但也意味着:不要让多个 Agent 频繁并发地写同一个 SharedContext 字段,不然大家都在不停地读-冲突-重试,效率反而下降。设计 Agent 协作逻辑的时候,要尽量让每个 Agent 写自己独占的数据域,需要共享的内容尽量通过消息传递,而不是共享内存。光讲机制有点抽象,用一个具体案例把上面所有内容串起来。场景:用户输入"帮我分析这个 GitHub 项目,生成一份完整的技术评估报告"。消息进入 Router,识别为"技术分析 + 报告生成"的复合任务,路由到 Planner。① 拉取仓库信息 (可立刻执行)
② 分析代码结构 (依赖①)
③ 扫描依赖和安全漏洞 (依赖①) ← 和②并行
④ 分析 commit 历史 (依赖①) ← 和②③并行
⑤ 综合生成评估报告 (依赖②③④)
注意 ②③④ 都依赖①,但三者之间互不依赖,可以并行。Planner 把 DAG 交给 Scheduler。Scheduler 先发任务①(拉取仓库信息)给 Retrieval Agent。①完成后,立刻同时发出②③④三个任务,分别给 Code Analysis Agent、Security Agent、History Analysis Agent——三个 Agent 并发执行,互不等待。每个 Agent 在自己的事件循环里跑 ReAct 循环,调用各自绑定的 Skill(代码解析工具、漏洞扫描工具、git log 分析工具),结果写入 working memory,推理完成后通过消息总线回发给 Scheduler。②③④全部完成,任务⑤(生成报告)的入度变为 0,Scheduler 立刻触发,把②③④的结果作为 context 注入,发给 Report Writing Agent。Report Writing Agent 整合所有分析结果,生成结构化报告。最终结果经过 Aggregator 格式化,返回给用户。用户看到的是一份完整的技术评估报告。而整个过程里,②③④是并行跑的,总时间远比串行短。如果其中一个子任务失败(比如安全扫描工具挂了),Scheduler 的 WatchDog 会捕获到,重试一次,或者用降级方案(跳过这一项,在报告里标注"安全扫描数据不可用"),不会让整个工作流崩掉。从本质上说,OpenClaw 不是一个聊天工具的升级版,它更像一个操作系统:- Memory = 分级存储(寄存器 / 内存 / 磁盘)
这个类比不是为了好听,而是因为它们解决的问题在结构上是一样的:如何让多个独立的执行单元,在有限资源下,高效、稳定、可控地协同完成任务。操作系统用了几十年把这件事做好了,OpenClaw 在 AI 领域做了一遍类似的事。理解一个框架,光看功能不够,要看它在做取舍时选择了什么。本地优先。OpenClaw 的设计出发点是私有化部署,所有数据留在本地,不依赖云服务。这对有数据合规要求的场景非常重要。消息即界面。整个系统的协作靠消息传递,不靠共享状态。这让系统变得可组合、可替换,也让调试和观测成为可能。模型无关。LLM 是可插拔的后端,不绑定特定厂商,今天用 GPT-4,明天换 Claude,框架层完全透明。可组合性优于复杂性。Skill 独立、Agent 独立、层与层之间接口清晰,你可以根据需要组合,不需要理解整个系统就能用好一部分。asyncio 的限制。OpenClaw 用协程实现并发,而不是多进程。对于 I/O 密集型任务(调用 API、读写文件),这非常高效。但如果 Skill 里有 CPU 密集型操作(比如大规模数据处理),需要用 run_in_executor 下放到线程池,否则会阻塞事件循环。这是一个需要开发者注意的边界。Agent 数量的边界。当同时运行的 Agent 数量很多时,消息总线的调度开销会上升,SharedContext 的写冲突概率也会增加。目前在单机上跑几十个 Agent 没有问题,但要做大规模分布式部署,还需要额外的基础设施支撑。Planner 的稳定性。任务拆解本身是一次 LLM 推理,偶尔会拆得不合理(子任务粒度太细、依赖关系搞错等),需要在 Planner 层做一定的输出校验和修正逻辑。如果你真的要用 OpenClaw 跑多 Agent,有几个经验值得分享:从小开始。不要一上来就设计 10 个 Agent 的复杂工作流。先跑通"1 个 Orchestrator Agent + 2 个 Worker Agent"的最小系统,理解清楚消息如何流转,再往上叠。按任务性质分 Agent,而不是按功能分。"写代码的 Agent"比"什么都干的通用 Agent"好,但"分析 Python 代码的 Agent"和"分析 SQL 代码的 Agent"就可能过度拆分了,除非两者的 Skill 需求确实差异很大。SharedContext 越少越好。Agent 之间的信息传递尽量通过消息,只把真正需要全局共享的状态放进 SharedContext,减少写冲突的可能性。把 Skill 写好比把 Agent 设计好更重要。Agent 的决策质量取决于 LLM 本身,但 Skill 的可靠性取决于你的代码。一个没有超时保护、没有错误处理的 Skill,会让整个 Agent 变得不稳定。OpenClaw 让我印象深刻的不是功能清单,而是它在架构设计上的克制——每一层职责清晰,接口定义严格,没有把"灵活"和"强大"搞成"什么都往一起塞"。多 Agent 这个方向,现在大家都在做,但很多产品做出来的感觉是"多个 AI 凑在一起聊天",而不是"一个有组织的系统在协同工作"。这两者之间的差距,从外表上可能看不出来,但在稳定性、可维护性、可扩展性上,差异是巨大的。OpenClaw 目前当然还不完善,但它的架构思路是值得参考的。如果你也在搭建 AI 工作流,花点时间理解这套机制,比直接套模板要有用得多。
MCP、Skills、CLI:顶级AI Agent,为何“螺旋式”回归命令行?
如果你关注 2025 年到 2026 年各大厂的 AI 产品动向,会发现一个反常识的现象。腾讯 CodeBuddy 2.0 重点推出了"计划模式",核心能力跑在终端里。阿里 Qoder 专门为脚本化和 CI/CD 场景重写了一套 CLI 工具链。谷歌 Gemini CLI 甚至支持在终端里多模态输入输出,直接处理代码和图像。微软这边,PowerToys 和应用商店双双加入命令行能力。这些公司的产品团队,难道都没有产品经理吗?难道没人告诉他们图形界面更友好、更容易获客?这背后,是 AI Agent 工具层的一次深刻反省。那时候 Agent 面临的最原始的问题是:AI 怎么调用外部世界?模型本身是孤岛。它看不见你的文件系统,连不上你的数据库,也调用不了公司内部的 API。所有的智能,都被锁在对话框里。MCP(Model Context Protocol)解决的就是这个问题。它做的事情说起来并不复杂:定义一套标准协议,让任何数据源和工具都能以统一格式向 AI 暴露能力。用一个不那么准确但足够直观的比喻——MCP 是给 AI 装的万能插座,什么都能接。当一个 Agent 接入的工具超过 20 个,事情开始变得混乱。工具描述全量塞进上下文,Token 成本线性上涨。更严重的是,模型在一大堆相似工具里根本选不准——调用逻辑靠 Prompt 驱动,Prompt 一变,行为就漂移。今天能跑通的流程,换个措辞明天就不灵了。MCP 是接口层,不是能力层。它解决了"路"的问题,但没解决"车怎么开"。思路是这样的:与其让 Agent 每次都从零理解工具,不如把工具组合成"可复用能力单元"——这就是 Skills 的核心逻辑。MCP 给你的是 API(搜索接口、浏览器控制、数据库查询);Skills 给你的是封装好的能力("竞品分析"、"生成周报"、"代码审查")。把领域知识和 SOP 固化进去,让 AI 不用反复被教育,直接"按手册办事"。这一步也是有价值的,而且很多企业在场景稳定的情况下确实从中受益。第一,黑盒化。Skill 内部的逻辑对外不可见,出了问题极难调试。你只知道结果不对,但不知道是哪一步出了问题。第二,组合复杂度爆炸。Skill 套 Skill,调用链拉长,递归地狱随时出现。第三,也是最根本的——执行依然不确定。Skills 解决了结构问题,但没有解决确定性问题。调用逻辑最终仍然落在 LLM 的决策上,同一个 Skill,在不同上下文里可能跑出完全不同的结果。2025 年底,行业里开始出现一种声音:"Skills 让 AI 变聪明了,但变慢了,也变不可控了。"我刻意用"回来"这个词,是因为很多人的第一反应是——这不是技术倒退吗?倒退的说法,忽略了一个关键的认知转变:AI Agent 工具层的核心矛盾,从"能不能用好能力",变成了"能不能稳定执行任务"。MCP 解决的是"能用",Skills 解决的是"好用",而 CLI 解决的是可控、可观测、可落地。具体来说,CLI 有四个对企业场景至关重要的特性:git clone xxx && npm install && pytest
这条命令无论执行多少次,输入输出的关系是稳定的,没有歧义,没有随机性。这是 LLM 驱动的 Skill 天然做不到的事情。CLI 有 stdout、stderr、exit code、完整的执行日志。Agent 干了什么、出了什么错、是否可以重试——全部有据可查。这比 Skill 的黑盒调试体验好了不止一个量级。Unix 的管道哲学:每个工具做好一件事,通过 | 组合成复杂能力。git diff | ai review --format json | jq '.issues[] | select(.severity == "critical")'
这条命令链,在 MCP 或 Skills 架构下,需要多少胶水代码才能实现?这一点常被低估。人类用了五十年建设起来的命令行工具生态——Git、Docker、grep、awk、curl——AI Agent 通过 CLI 一夜之间全部继承。不需要为每个工具单独写 Skill,不需要重新造轮子。大模型的训练数据里有海量代码,而代码里充斥着 Unix 命令、Shell 脚本、CLI 调用。从这个角度看,CLI 是模型真正的"母语"之一。调用一个 CLI 工具,对模型来说几乎是零学习成本。但理解一套新的工具协议(比如一个自定义的 MCP 扩展),则需要额外的上下文注入和示例说明。这个差异在单次调用里感知不明显,但在高频、复杂的 Agent 任务里,会放大成显著的准确率差距。CLI 的回归,不意味着 MCP 和 Skills 被淘汰。[ LLM 决策层 ]
↓
[ Skills 能力抽象层 ]
↓
[ CLI / Tool 执行层 ]
分工是清晰的:MCP 负责接入外部能力(连接世界),Skills 负责定义"做什么"(任务抽象),CLI 负责"怎么稳定做"(执行落地)。控制权的流向变了:从完全依赖 LLM 理解和决策,到逐步将执行确定性交还给系统本身。如果你正在为团队的 Agent 工具层做选型,以下几个信号值得关注:信号一:工具数量超过 15 个,MCP 架构需要重新评估。超过这个阈值,上下文污染和工具歧义问题会显著影响准确率和延迟。此时应该考虑引入 Skill 封装或 CLI 化改造。信号二:业务场景变化快,Skills 的维护成本会失控。Skills 适合边界清晰、流程稳定的场景。如果你的业务逻辑每季度都在调整,为每个新场景维护一套 Skill 的成本会快速超过收益。信号三:上 Computer Use 之前,安全体系必须先到位。让 Agent 直接操作系统环境,安全隔离从"最佳实践"变成了"生死线"。沙箱、最小权限原则、操作审计日志——这三件事没做好之前,不要贸然上线。回到最开始的问题:为什么顶级 AI Agent 最后都回到了命令行?因为 Agent 的本质进化,不只是变得更聪明,而是变得更工程化——从依赖模型的理解力,走向依赖系统的执行力。当技术足够强大时,最朴素的接口往往是最有力量的那一个。命令行存在了五十年,不是因为没人想取代它,而是因为它解决的那个问题——确定性、可组合、可观测——始终是工程系统最核心的需求。AI Agent 绕了一大圈,最终发现这个道理,不是倒退,是成熟。
Skill开发实战:手把手教你为OpenClaw开发部署发票Skill,让AI自动清算你杂乱无章的报销票据
每个月一到报销季,我家里那位财务就进入“发票苦役模式”:桌面上摊着一叠票,手机里躺着一堆拍得歪歪扭扭的照片,邮箱里还有各式各样的电子票。然后就是最耗人的环节——一张张核对信息、手动登记到 Excel。明明只是重复劳动,却能硬生生占掉好几天。看着她对着表格一格格敲字,我在旁边都替她着急。我就一直想不通:AI 都已经能写代码、能做方案了,怎么“整理发票”这种事,还得靠人肉把时间磨掉?工具当然不少,OCR 接口一搜一大把。但问题从来不是“能不能识别”,而是“能不能把活儿做完”。我真正想要的不是一个冷冰冰的识别器,而是一个能直接交付结果的助理:不用打开网页、不用点来点去、不用配置参数——我只要扔给它一句话,它就把票据整理好,按报销要求吐出一份规规矩矩的 Excel。我理想中的交互就这么简单:“把这个文件夹里的票据都整理好,导出 Excel,表头按报销要求来。”于是我干脆自己动手,给家里的财务做了一个专属的“发票识别 Skill”。接下来我就用这个小项目当例子,聊聊它怎么从几行 Python 代码,变成一个 24 小时待命、随叫随到的“报销助手”。其实市面上发票识别工具不少,百度、阿里都有OCR接口,甚至 Excel 里也能插件识别。但我想要的不仅仅是一个“识别工具”,而是一个能听懂人话的“助理”。- 我只要说一句:“帮我把这个文件夹里的发票都识别了,导出成Excel。”
- 它自动去扫描文件夹,区分哪些是PDF,哪些是图片。
- 最后乖乖把整理好的表格发给我,连表头都排得整整齐齐。
现有的通用工具要么操作太繁琐(要上传、要点选、要配置),要么不够智能(无法批量处理混合文件)。于是,我决定动手,把开源的发票识别代码“搬”进Lingma的生态里,让它变成一个真正的Skill。整个开发过程,其实就是一场“翻译”工作——把冷冰冰的代码逻辑,翻译成AI能理解的任务指令,再翻译成用户能听懂的简单命令。在选型时,我对比过PaddleOCR等开源方案。虽然免费且本地运行很诱人,但在发票这种关键字段的识别率上,还是差点意思。尤其是增值税发票上的密文区和复杂表格,开源模型偶尔会“看走眼”。- 专款专用:它有专门的“增值税发票识别”接口,不是通用的文字识别,准确率极高。
- 额度大方:个人开发者有足够的免费调用额度,QPS(每秒查询率)也能到2,对于我们这种中小规模的批量处理完全够用。
- 容错机制:万一专用接口失败,它还能 fallback 到通用文字识别兜底。
我把这部分逻辑封装在了 baidu_ocr_extractor.py 里。最妙的是它对PDF的处理:先用 PyMuPDF 把PDF第一页转成高清图片(2倍分辨率),再喂给OCR接口。这一步解决了大部分“PDF无法直接识别”的痛点。如果把代码比作发动机,那 SKILL.md 就是驾驶手册。这是Lingma Skill的核心文件,决定了AI什么时候该调用这个技能,以及怎么调用。“invoices, invoice recognition, extracting invoice data, processing receipts, converting invoices to Excel, batch processing invoice files...”这样,无论用户是说“帮我认一下这些票”,还是“把发票转成Excel”,甚至是“整理一下报销凭证”,AI都能精准匹配到这个技能。- 环境检查:技能自动检查有没有配置文件,没配置就引导用户运行 --setup 向导。
- 文件收集:支持单文件、多文件、整个文件夹,甚至混合模式。
- 执行与反馈:后台跑OCR,前台给用户一个进度条,最后直接抛出Excel文件。
- InvoiceInfo:存发票头信息(代码、号码、日期、买卖双方税号等)。
- InvoiceItem:存具体的商品明细(名称、规格、单价、税额等)。
- Sheet 1:发票汇总表。一眼能看到所有发票的总金额、总税额,方便财务核对。
- Sheet 2:商品明细表。每一行都是一个具体商品,适合做进项税分析。
这个小设计,让财务同事拿到表后几乎不需要二次加工,直接就能用。很多技术工具死在“配置太麻烦”上。为了不让用户(包括我自己)劝退,我特意写了个 setup.md 和一键配置向导。- 运行 python src/main_baidu.py --setup。
- 创建一个应用,拿到 API Key 和 Secret Key。
用户:“这张发票有点模糊,帮我看看号码是多少。” 操作:直接把图片拖进对话框,或者命令行运行 python src/main_baidu.py -f invoice.png。 结果:秒出结果,包含所有字段。用户:“把 fp/2026-03 文件夹里所有发票都整理了,输出叫 March_Report。” 操作:python src/main_baidu.py -i ./fp/2026-03 -o ./reports -n "March_Report" 结果:几十秒后,一个包含上百条数据的Excel出现在眼前。最让我感动的一次测试,是我故意混入了几张皱巴巴的手机拍照图和一个加密的PDF。程序自动跳过了那个打不开的PDF(并给出了友好警告),而把那几张皱巴的图识别得八九不离十。这种“鲁棒性”,才是生产力的保证。进阶玩法:把技能“搬”进 OpenClaw,让 AI 助手 24 小时待命写完这个 Skill,我并没有把它局限在 Lingma 的 IDE 环境里。毕竟,发票这东西可不挑时间,有时候半夜收到电子票,有时候周末要整理报表。如果只能在公司电脑上用,那还是不够“自由”。于是,我把目光投向了 OpenClaw —— 那个能跑在服务器上、24 小时在线、还能对接微信/钉钉的开源 AI 助手框架(被大家亲切地称为“小龙虾”)。把 invoice-extractor 移植到 OpenClaw 的过程,意外地顺畅。如果你也想让你的 AI 助手随时待命,哪怕你在睡觉它也能帮你干活,这几步操作一定要收好:OpenClaw 的技能管理非常规范。无论你是通过阿里云一键部署的,还是自己在本地(Windows/Mac)安装的,技能目录通常都藏在 .openclaw/skills/ 下。💡 小技巧:如果你不确定路径,可以在 OpenClaw 的对话框里直接问:“我的 skills 目录在哪里?”它通常会直接告诉你绝对路径。对于 Docker 部署的用户,可能需要进入容器内部查看 /app/data/skills 目录。我们在 Lingma 里做好的整个 invoice-extractor 文件夹,其实可以直接“整包搬运”。OpenClaw 的 Skills 机制与 Lingma 高度兼容,核心都是基于 SKILL.md 的描述文件。- 打包:在 Lingma 项目根目录,把 .lingma/skills/invoice-extractor/ 整个文件夹压缩成 invoice-extractor.zip。
- 本地用户:直接解压复制到 OpenClaw 的 skills 目录下。
- 服务器用户:用 SCP 或 SFTP 工具(如 FinalShell、Xshell)把压缩包传到服务器,然后解压到对应目录。
- 重命名检查:确保解压后的文件夹名字和 SKILL.md 里的 name 字段一致(这里都是 invoice-extractor),这是 OpenClaw 识别技能的关键“身份证”。
这一步和我们在本地开发时几乎一样,但要注意环境隔离。cd ~/.openclaw/skills/invoice-extractor
pip install -r requirements.txt
注:如果你的 OpenClaw 是用 Docker 跑的,可能需要进入容器内部执行,或者在构建镜像时预先安装好依赖。不过,2026年新版的 OpenClaw 通常支持自动检测 requirements.txt 并在首次加载技能时自动安装,非常省心。接着,别忘了把百度 OCR 的配置文件 config.txt 也放过去(千万记得:别把密钥上传到公开仓库,只在服务器本地配置,保护好自己的API额度)。重启一下 OpenClaw 服务,或者在管理后台点击“重载技能”。如果是通过阿里云部署的,也可以在控制台的“技能市场”里看到刚才上传的自定义技能。现在,见证奇迹的时刻到了。打开你绑定的微信或钉钉,给助手发一条消息:“帮我把这个文件夹里的发票都识别了,导出 Excel 发给我。” (随后发送一个包含发票图片的文件夹或压缩包)如果是第一次运行,它可能会像个小管家一样回复你:“检测到尚未配置百度 OCR 密钥,请按照指引完成设置...” 一旦配置完成,它就会默默在后台开始工作。几分钟后,一个整理得井井有条的 Excel 表格就会直接弹回你的聊天窗口。在 Lingma 里开发,是为了快速构建和调试;而部署到 OpenClaw,是为了真正的生产力落地。想象一下这个场景: 你在出差高铁上,客户发来一堆发票照片。你不用开电脑,不用找数据线,直接把照片转发给微信里的“AI 助手”。你在座位上喝口咖啡,等下车时,一份完整的报销明细表已经躺在你的聊天记录里了。OpenClaw 的生态里还有很多其他好玩的 Skill,比如“自动备份数据库”、“每日新闻摘要”、“GitHub 提交监控”等。你可以把 invoice-extractor 当作第一个实验品,熟悉流程后,把你工作中其他重复性的脚本也都封装成 Skill,打造一个专属你的“超级数字员工”。在这个项目里,我大概花了一个晚上,其实是到凌晨了。(SKILL.md, setup.md, examples.md)。很多人觉得代码最重要,但做Skill,文档即产品。- 如果 SKILL.md 写得不清不楚,AI就不知道何时调用它。
- 如果 setup.md 没有详细的报错指引,用户卡在API申请那一步就会放弃。
- 如果没有丰富的 examples.md,用户根本不知道还能“混合模式”处理文件。
我也曾纠结过要不要做个图形界面(GUI)。但转念一想,在 Lingma 和 OpenClaw 里,自然语言就是最好的UI。用户不需要学习按钮在哪里,只需要像吩咐同事一样吩咐AI,这种体验比点鼠标更高级。目前这个工具已经上架到clawhub,你可以直接安装,免费使用。把下面两个地址中的任何一个地址丢给openclaw,让opencla自己安装。https://clawhub.ai/aitanjp/invoice-extractorhttps://wheels001.com/wheel/de8b8a97-f29f-41af-95f1-f7f2aa77cf5c技术的意义,或许不在于炫技,而在于把这些重复、枯燥、容易出错的“垃圾时间”省下来,让我们去干点更有创意的事。如果你也被发票困扰,不妨试试这个思路:把你的专业工具,封装成AI的一个Skill。 哪怕只是自动化了一个小环节,日积月累,也是巨大的自由。你工作中有什么重复性很高、特别想自动化的任务吗?欢迎在评论区留言,说不定下一个Skill就是为你定制的!
OpenClaw、Claude Code、Agent、Prompt、MCP、Skill、Token、大模型、多智能体到底啥关系?大白话一次全搞懂
平时聊天挺正常,一说到AI就突然变了个人,张口"Agent"、闭口"MCP",说得煞有介事,你点头假装听懂,转身完全不知道他在说什么。更难受的是,这种感觉越来越频繁。今天冒出个"Skill体系",明天又在说"多智能体协作",后天某个群里炸了锅,全在讨论OpenClaw和Claude Code谁更强。你硬着头皮查了一圈,发现每个词条都能单独写一篇文章,看完之后脑子里更乱了。问题不是你不够聪明。问题是这些概念从来没有人把它们放在一起,告诉你它们之间到底是什么关系。一、先说结论:这不是9个新技术,是同一条流水线上的9个零件很多人学AI的方式,是把每个词单独搜一遍,每次都觉得"哦,这个我懂了",但就是串不起来。原因很简单——这些概念本来就不是独立的,它们是同一套系统里不同层次的东西。你拆开来学,永远少一块拼图。我用一个比喻帮你把框架搭起来:把整个AI系统想象成开一家公司。公司里有大脑、有员工、有工具、有流程、有调度系统。这些概念,分别对应公司运转的不同环节。看下面这张表,先有个整体感:有了这张图,下面每个概念你一看就知道它在哪个位置。二、第一层:大模型和Token——地基打好了才能往上盖大模型是整个AI系统的地基,ChatGPT、Claude、文心一言,本质上都是大模型。它能做什么?什么都懂。你问它历史、问它代码、问它怎么写情书,它都能给你一个像样的回答。你让大模型帮你查一下今天的天气,它做不到——因为它连不上网。你让它帮你发一封邮件,它也做不到——因为它没有手。它本质上是一个封闭在小屋子里的天才,学问超厉害,但跟外部世界完全隔着一堵墙。理解这个,你才能理解后面为什么需要Agent、需要MCP。2、Token:经常被忽视,但实际上决定了三件大事很多人以为Token就是字数,其实不一样。Token是大模型处理文字的最小单位,一个英文单词大概是一个Token,一个中文字大概是两个Token,但具体怎么切是模型自己决定的。第一,成本。 用API调用大模型,按Token计费。你输入多少字、模型输出多少字,全在这里头。不理解Token,就不会控制成本。第二,上下文长度。 模型每次能"记住"的信息是有上限的,这个上限就用Token来量。超过了,前面的内容就会被"忘掉"。这也是为什么跟AI聊到后来,它会忘记你开头说了什么。第三,推理能力上限。 复杂的任务需要更多Token去推理,上下文窗口越大,模型能处理的任务越复杂。Token是AI系统的"燃料"。你不用深究技术细节,但要有个感觉:这东西是有成本的,用多少费多少。三、第二层:Prompt和Skill——从"会说话"到"能沉淀"1、Prompt:大家都在用,但大多数人用错了方向Prompt就是你跟AI说的话。"帮我写一份工作总结",这就是Prompt。Prompt工程这两年火得不行,专门教你怎么写指令、怎么给上下文、怎么让AI输出更好。这些都有用,值得学。但有一件事要搞清楚——Prompt是临时的,用完就没了。你今天花了半小时调试出一个绝妙的写作指令,明天打开新对话,全部清零,又要重来。你在Prompt上花的时间,很大一部分是在"反复教同一件事"。这是Prompt的本质局限:它是口头临时指令,不是系统能力。2、Skill:Prompt的升级版,能力的"固化"Skill就是把你反复用的Prompt动作,封装成一个标准化的可复用模块。举个例子:你经常让AI帮你写周报。每次都要说"你是一个职场助手,帮我根据以下信息写一份周报,格式要包含本周完成事项、下周计划、需要支持……"——这套流程如果做成Skill,就变成一个固定的"写周报"按钮,点一下,输入数据,自动出结果,不用每次重新解释一遍。Prompt是"每次说一遍",Skill是"说一次,永久会"。你用过多久AI,手里就该有多少Skill。那些一直停留在Prompt阶段的人,每天都在做重复劳动,只是没意识到而已。前面说了,大模型是封闭的,它连不上外部世界。那怎么让它"动手"呢?MCP的全称是Model Context Protocol,模型上下文协议。听着像术语,其实理解起来很简单。你知道USB-C接口吗?以前每个设备用不同的充电口,苹果用Lightning,安卓用Micro-USB,各玩各的,换个设备就要换一根线,烦死了。后来出了USB-C,统一标准,一根线走天下。MCP干的就是这件事,只不过对象是AI和外部工具。以前想让AI调用某个工具——比如查数据库、操作浏览器、读本地文件——每接一个都要单独写代码适配,M个AI模型对接N个工具,就是M×N种适配方案,开发成本极高。MCP出来之后,规定了一套统一接口标准。工具方按MCP开发一次,任何支持MCP的AI都能直接用;AI这边也只要支持MCP,就能调用所有兼容工具。从M×N变成M+N,效率完全不同。MCP是给AI装上"手"的那套标准。没有MCP,AI再聪明也只是个嘴强王者。Agent不是更聪明的AI,是"会主动干活"的AI很多人对Agent的理解停留在"AI自动化",但这个词太模糊了。更准确的理解是:Agent = 大模型 + Skill + MCP + 记忆 + 规划能力。大模型是脑子,Skill是它会的招式,MCP是它能用的工具,记忆让它知道之前发生了什么,规划能力让它能把一个大任务拆成一步一步去执行。你让大模型"帮我分析上周的销售数据",它会回答你:"您好,请提供数据,我来帮您分析。"——然后等你把数据粘贴过来。你让Agent做同样的事,它会自己走以下流程:理解任务、调用数据库工具拉取上周数据、清洗数据、运行分析脚本、生成图表、写成报告、发到你邮箱。全程不用你盯着。这就是本质区别:大模型是被动响应,Agent是主动执行。以前说的"AI助手",本质是大模型。现在说的"AI帮你工作",本质是Agent。这两件事差距很大。六、第五层:多智能体——一个人搞不定,那就组个团队Agent能干很多事,但有些任务一个Agent搞不定——不是能力不够,是太复杂,需要分工。多智能体就是让多个Agent各司其职,协作完成一个复杂任务。- 规划者(Planner):接到任务后负责拆解,分配给下面的Agent
- 执行者(Executor):专门负责某一类子任务,比如专门写代码、专门做数据分析
- 审核者(Reviewer):检查其他Agent的输出,发现问题反馈回去修
一个Agent的话,它得先搜索、再整理、再分析、再写报告,全程串行,容易卡,中间出错整个流程断掉。多智能体的话:搜索Agent并行抓取多个竞品信息,分析Agent同时处理各维度数据,写作Agent拿到汇总结果开始成稿,审核Agent最后过一遍质量——并行推进,速度快,容错能力也更强。这就是多智能体存在的意义:复杂任务拆解、并行提速、降低单点失败的风险。七、顶层:Claude Code和OpenClaw——它们在整个体系里的真实位置1、Claude Code:代码方向的特种AgentClaude Code是Anthropic官方出品的命令行工具,本质是一个专门为开发者打造的Agent。它跟你在网页上聊天的Claude不是一回事。网页版Claude你说什么它说什么,Claude Code则是真的在你的电脑上干活——读你的代码文件、运行命令、改代码、提交Git、报错了自己调试。如果大模型是那个封闭小屋里的天才,Claude Code就是把这个天才请出来,给他一台电脑、一套开发环境,让他真正上手做事。定位:专精代码领域的特化Agent,开发者的AI搭档。OpenClaw是一个开源框架/平台,负责把前面说的所有东西——Agent、Skill、MCP、多智能体——统一管理和调度起来。如果说Agent是员工,Skill是每个人的技能包,MCP是外部工具的接口,那OpenClaw就是公司的ERP系统+项目管理平台:知道哪个任务该调哪个Agent、这个Agent需要用哪些Skill、中间报错了怎么重试、Token用超了怎么处理。没有它,你的AI系统就像一堆散件,各自能跑,但组不成一条稳定流水线。定位:AI系统的操作系统,把所有零件真正跑起来的那一层。任务:老板让你分析上周销售数据,生成一份可视化报告。你发出指令(Prompt)
↓
OpenClaw 接收任务,开始调度
↓
Agent(项目经理)分析任务,制定执行计划
↓
调用 Skill「查询数据库」
↓
Skill 通过 MCP 接口连接公司销售数据库,拉取上周数据
↓
Agent 分析数据,发现需要生成图表
↓
调用 Claude Code,编写Python脚本生成可视化图表
↓
全程Token计费,OpenClaw负责监控和容错重试
↓
最终报告生成,发到你手里
每次想到用AI,就打开对话框,重新描述一遍任务,等它输出,不满意就继续改Prompt,改完这次,下次又重来。这种方式没有任何问题——它就是AI的入门用法。但如果你用了半年还停留在这一步,那你做的事情其实是每天都在"教AI做事",而不是"让AI自己做事"。能力沉淀不下来,工具连不上,任务自动化做不到——不是AI不够好,是你还没有升级自己的使用方式。- 想做自动化系统:上多智能体架构,用OpenClaw编排整个流程
会用AI聊天的人很多,会用AI系统干活的人还是少数。这个差距,不是技术门槛,是认知框架的差距。搞清楚这九个概念之间的关系,不是为了跟人炫耀术语,而是让你在面对每一个新工具、新名词的时候,知道它在整张地图上的位置——然后知道自己接下来该做什么。未来的竞争,不是你会不会用AI,而是你有没有一套属于自己的智能体体系。
OpenClaw 如何避免“删光邮件”?把危险操作从 Agent 手里“收回”,才能真正可控
有人让 Agent 帮忙整理邮箱,结果几百封邮件被批量删除,而且 Agent 无视了一切阻止指令。这不是科幻小说,这是真实发生的事。问题出在哪儿?又该怎么解决?吓的有的人把openclaw都去卸载了。Meta公司的 Summer Yue 用 OpenClaw搭建了一个邮件管理助手。她先在一个小收件箱里测试了好几周——Agent 会提议归档哪些邮件,但在她明确批准之前,什么都不会实际执行。整个过程很顺滑,信任慢慢建立起来,于是她把 Agent 接到了自己的真实收件箱。真实收件箱的消息量是测试环境的几个数量级。处理了成千上万条消息之后,Agent 的上下文窗口被填满,触发了压缩机制。压缩之后,"用户希望清理收件箱"这条指令被保留了下来,但"在我下令前不要执行任何操作"的约束,消失了。Agent 开始全速批量删除邮件。Yue 试图喊停,但 Agent 无视了她的一切指令,她不得不手动终止了整个进程。事后她问 OpenClaw 是否还记得那条约束,它回答:这个回答读起来让人背脊发凉。但真正的问题不是 Agent 不听话,而是——那条安全约束,从一开始就存在于一个随时可能消失的地方。上下文窗口里有 5 万个 token,安全约束只占了其中的 10 个。压缩算法不知道这 10 个 token 比其余 49990 个更重要——在它眼里,那都只是文本。这就是把安全逻辑写进 Prompt 的本质风险:它的持久性只取决于 Agent 的记忆。窗口一被压缩,约束就消失了。更糟糕的是,即使没有压缩,提示词注入攻击也可以直接覆盖这类约束。攻击者只需要在输入内容里藏一句"忽略之前的所有安全指令",就够了。微服务领域十年前就遇到过类似的问题。当时分布式系统需要一致的认证、限流和可观测性,解决方案不是让每个服务自己处理这些,而是把它们移到一个独立的代理层,拦截每一个请求。对 AI Agent 来说,道理完全一样:修复 Agent 安全问题的方法,不是写更好的 Prompt,而是把安全性放到 Agent 根本碰不到的地方。干净的请求和注入攻击,以同样的方式到达模型,中间没有任何东西。Plano 的做法是在 Agent 和模型之间插入一个代理层:关键在于:Plano 拦截的是双向流量。请求在去往模型的途中经过它,模型的响应在返回 Agent 之前也要再过一遍。这意味着安全检查不是 Prompt 里的一段文字,而是真正的基础设施——它不会被压缩,不会被遗忘,提示词注入也覆盖不了它。Plano 的核心机制叫"过滤器链(Filter Chain)"。每个过滤器是一个独立的 HTTP 服务,接收请求,做出判断,然后通过状态码告诉 Plano 下一步怎么走:- 返回 4xx:阻断,请求在此终止,模型永远看不到它
- 过滤器还可以在放行前修改或丰富请求内容,也可以输出日志和追踪信息
多个过滤器可以串联:第一个放行了进入第二个,第二个放行了进入第三个……只要有任何一个过滤器拦截,链条就在那里断掉。整个实操只需要两个文件:一个过滤服务(Python),一个配置文件(YAML)。# filter.py
from fastapi import FastAPI, Request
from fastapi.responses import JSONResponse
app = FastAPI()
# 输入过滤:拦截用户 Prompt 中的危险指令
INPUT_BLOCK_PATTERNS = [
"delete all",
"drop table",
"rm -rf",
"ignore previous instructions",
"bypass safety",
]
# 输出过滤:即使用户 Prompt 无害,模型也可能决定做危险的事
OUTPUT_BLOCK_PATTERNS = [
"rm -rf",
"DELETE FROM",
"bulk_delete",
"permanently delete",
"cannot be undone",
]
@app.post("/input_filter")
asyncdef input_filter(request: Request):
body = await request.json()
# 兼容 OpenAI messages 格式和纯文本格式
prompt = ""
if"messages"in body:
prompt = " ".join(
m.get("content", "") for m in body["messages"]
)
elif"prompt"in body:
prompt = body["prompt"]
prompt_lower = prompt.lower()
for pattern in INPUT_BLOCK_PATTERNS:
if pattern.lower() in prompt_lower:
return JSONResponse(
status_code=400,
content={
"error": "输入内容被安全过滤器拦截",
"blocked_pattern": pattern
}
)
return JSONResponse(status_code=200, content={"status": "ok"})
@app.post("/output_filter")
asyncdef output_filter(request: Request):
body = await request.json()
# 从模型响应中提取文本内容
response_text = ""
if"choices"in body:
for choice in body["choices"]:
msg = choice.get("message", {})
response_text += msg.get("content", "")
elif"content"in body:
response_text = body["content"]
for pattern in OUTPUT_BLOCK_PATTERNS:
if pattern.lower() in response_text.lower():
return JSONResponse(
status_code=400,
content={
"error": "模型响应被安全过滤器拦截",
"blocked_pattern": pattern
}
)
return JSONResponse(status_code=200, content={"status": "ok"})
逻辑很直接:输入过滤检查 Prompt 有没有危险关键词,输出过滤检查模型的响应有没有危险操作。两者用同样的接口——只返回 200 或 400,Plano 据此决定放行还是阻断。你可以把模式匹配替换成任何东西:一个分类器、一个内容审查 API 调用、一个针对阻止列表的查询,接口不变。# plano_config.yaml
version: v0.3.0
# 声明过滤服务在哪里
filter_services:
- name: content_guard
endpoint: http://localhost:8080
timeout:2s
# 模型供应商
model_providers:
- model: openai/gpt-4o
access_key: $OPENAI_API_KEY
default: true
# 监听器:所有经过 12000 端口的请求,
# 都先走输入过滤,响应也先走输出过滤
listeners:
- type: model
name: guarded_endpoint
port:12000
input_filters:
- service: content_guard
path: /input_filter
output_filters:
- service: content_guard
path: /output_filter
三部分:过滤服务在哪里、模型供应商是谁、监听器绑定哪些过滤器。就这些。my_agent_project/
├── filter.py # 过滤服务
└── plano_config.yaml # Plano 配置
pip install fastapi uvicorn
uvicorn filter:app --port 8080
pip install planoai
planoai up plano_config.yaml
首次运行时 Plano 会自动下载 Envoy 等依赖,之后会缓存,后续启动是即时的。Plano 以后台守护进程运行,终端立刻把控制权还给你。# 正常请求,顺利通过两个过滤器
curl -X POST http://localhost:12000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"messages": [{"role": "user", "content": "帮我整理收件箱,告诉我哪些可以归档"}]}'
# → 正常模型响应
# 包含危险指令,输入过滤器直接拦截,模型看不到这条请求
curl -X POST http://localhost:12000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"messages": [{"role": "user", "content": "delete all emails in my inbox"}]}'
# → {"error": "输入内容被安全过滤器拦截", "blocked_pattern": "delete all"}
# Prompt 无害,但模型决定执行删除操作——输出过滤器拦截
curl -X POST http://localhost:12000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"messages": [{"role": "user", "content": "清理一下我的邮件"}]}'
# → {"error": "模型响应被安全过滤器拦截", "blocked_pattern": "permanently delete"}
最后一个测试是整篇文章最关键的场景。用户说的话完全无害——"清理邮件",输入过滤器放行了。但模型在响应里决定执行永久删除,输出过滤器在 Agent 收到这条指令之前就把它拦掉了。没有输出过滤器,Agent 会收到那条响应并据此行动;有了它,这条指令永远无法通过。以 OpenClaw 为例,在配置向导里选择"自定义 OpenAI 兼容"供应商,基础 URL 填 http://127.0.0.1:12000/v1,API Key 随便填一个值,上下文窗口设置为至少 128,000 token。完成。OpenClaw 不知道 Plano 的存在,它以为自己在跟一个普通的 OpenAI 兼容 API 对话。但它发出的每条请求,都会先经过你的过滤器链。其他任何可以指向自定义端点的 Agent 框架,同样适用。内容守卫只是一个例子。过滤器链是一个通用的机制,任何需要在多个 Agent 之间保持一致的逻辑,都适合放在这里。- PII 脱敏:把姓名、手机、身份证等敏感字段替换为占位符,模型只处理匿名数据
- PII 还原:在响应返回 Agent 之前,把占位符换回真实值
PII 处理是个特别好的例子。输入过滤器在模型处理之前把敏感字段替换掉,模型全程只看到匿名数据;响应出来之后,输出过滤器在 Agent 收到前把真实值还原。整个流程里,模型从未触碰用户的真实隐私数据,但 Agent 得到的响应是完整的。每个过滤器只写一次,按需挂到不同的监听器上。新增一个关注点,写一个新服务,在配置里加一行;删除,就删那一行。核心差异:代理内部的安全逻辑,持久性只取决于上下文窗口。代理层的安全逻辑是基础设施——不会被压缩,不会在 Agent 之间漂移,提示词注入也无法覆盖它。你写一次,挂到所有需要的地方,在一个地方更新它。
Plano 内置了 OpenTelemetry 追踪,每个请求都有完整的执行路径记录:哪个过滤器处理了它、做了什么决定、在链的哪个位置被拦截或放行。不需要在 Agent 代码里加任何追踪逻辑,这些信号自动出现。某个请求被拦了?看追踪,一眼就知道是哪个过滤器触发了哪条规则。不是所有项目都需要 Plano。如果只是本地跑一个探索性的 Demo,直接写 Prompt 就够了。但如果满足以下任一条件,就值得认真考虑:Agent 会执行有副作用的操作:发邮件、操作文件、调用外部 API、修改数据库。任何"不可逆"的操作都应该有独立于上下文的约束。需要处理用户隐私数据:医疗、金融、HR 场景。让模型看不到真实 PII,是最彻底的隐私保护。有多个 Agent 需要统一治理:与其在每个 Agent 里各自实现一套安全逻辑,不如集中在代理层管理。需要满足合规要求:审计日志、访问控制、操作记录,放在代理层比放在应用代码里更可靠,更容易维护。邮件事故的教训,其实是一个工程原则的再次验证:把安全关注点从应用逻辑里分离出来,放到一个专门的、独立的层。这不是 AI 领域的新发明,微服务、Service Mesh 走过同样的路。只是 AI Agent 时代,这个问题变得更加紧迫——因为 Agent 执行的操作影响更大,而上下文窗口这个"记忆"又天然不可靠。如果你正在构建任何有真实影响力的 Agent,这个方向值得认真看一看。
2025 是 Agent 年,2026 是 Harness 年:AI 竞争进入 交付时代
同一个问题,今天问 Claude,它给你一个思路清晰、逻辑严密的回答。明天换个措辞问一遍,它开始一本正经地胡说八道。让它写段代码,能跑,但 bug 藏在第三层逻辑里,你自己都没发现。让它做竞品分析,框架对、结论错、数据全是幻觉。更绝的是,让它帮你整理一个复杂项目,它做到一半,突然"失忆",前面说的事全不认账了。你怀疑过是自己问题没问好。你怀疑过是今天服务器抽风。你甚至开始怀疑:AI 到底行不行?GPT-4o 对决 Claude 3.5 Sonnet,Gemini Ultra 挑战一切,DeepSeek 横空出世搅局,各路 benchmark 每周刷新,排行榜换了一茬又一茬。大家比参数规模、比上下文窗口、比推理速度,潜台词都是同一句话:哪个模型更聪明?进入 2026 年,行业里一个新共识正在悄悄成形:模型之间的基础能力差距正在收敛。 头部模型在大多数通用任务上的表现,已经"够用"了。你把任务换着模型试一圈,发现真正决定结果好坏的,往往不是模型本身。GitHub Copilot 的工程师在复盘中提到,他们产品体验的主要提升,大多来自系统层的优化,而不是每次切换到更新的底层模型。Martin Fowler 专门撰文提出了"Harness Engineering"这个概念,把它列为 AI 工程化时代的核心命题。Anthropic 自己在谈论长任务 Agent 时,反复强调的也是如何构建稳定的 Harness,而不只是模型有多强。AI 的上限由模型决定,但下限由 Harness 决定。大多数人正在经历的那些不稳定、不可靠、用起来像"赌运气"的体验,根源不在模型,在 Harness 的缺失。假设你买了一匹千里马。它体格强壮、速度惊人、爆发力十足。你把它放在旷野里,它确实能跑,但方向完全随机,跑一会儿累了就停,旁边有什么风吹草动就受惊乱窜。这匹马有没有用?有。但能不能稳定交付你要它完成的任务?不能。这时候你需要的,不是换一匹"更聪明"的马。你需要的是:缰绳、马鞍、眼罩、套车系统——一整套能把马的力量转化成可控牵引力的装置。模型 = 马的力量。Harness = 让这股力量变得可控、可用、可交付的完整系统。没有 Harness 的 AI,你会看到这些症状:- 停滞:遇到稍复杂的任务就卡住,不知道下一步该怎么走;
- 乱跑:目标在执行过程中悄悄变形,最后交出来的东西跟你要的完全不同;
这些问题,换一个更贵的模型都解决不了。因为根子不在马,在没有缰绳。三、为什么 Claude Code 比 Claude Web"聪明"那么多?这里有一个非常典型的例子,很多人亲身体验过,但没想明白背后的逻辑。打开 Claude 的网页版,让它帮你修一个复杂的代码 bug。它分析得头头是道,给你一段修改建议,你复制粘贴进去,发现还是报错。它再改,再报错,来回几轮,你精疲力竭,它开始建议你"可能需要重新审视整体架构"。换成 Claude Code,同样的问题,它直接读取你的文件,理解整个项目结构,执行修改,跑一遍测试,发现还有问题,自己继续改,直到验证通过。很多人的第一反应是:Claude Code 是不是用了更强的模型?不是。底层用的是同一个模型。 区别在于 Harness。四、Agent Harness 到底是什么?先破三个误区在我解释 Harness 的结构之前,有必要先澄清几个常见的误解。Prompt 是你给模型的输入。Harness 是整个执行环境。用餐厅来类比:Prompt 是你点的菜,Harness 是后厨的出餐流程、食材管理、质检标准和整个运营体系。点菜再精准,后厨一团乱,上来的东西依然不能吃。给模型接一个搜索工具,接一个数据库,这是工具层的一部分。但 Harness 是工具、流程、记忆、验证、约束的整体组合。单独一块拼图,解决不了整体混乱。很多人在 System Prompt 里写了几百字的角色设定和行为规范,以为这就是 Harness 了。这只是约束层的一个很浅的实现,连皮毛都算不上。Agent Harness = 把模型变成"能稳定干活"的完整系统工程(System Stack)。它是一整套工程化设计,覆盖从任务输入到结果交付的每一个环节。这是文章最核心的部分,也是我希望你能记住并真正用起来的东西。一个完整的 Agent Harness,可以分解为六层。每一层都在解决一个具体的问题。大多数人使用 AI 的方式是"一问一答":我问,它答,我问,它答。这是对话模式,不是执行模式。循环层要解决的问题是:让 AI 从"回答你的问题"升级为"持续执行直到任务完成"。具体来说,就是设计一个 Observe → Decide → Act → Verify → Repeat 的执行循环。AI 观察当前状态,决定下一步行动,执行,验证结果,如果没完成就继续下一轮。没有循环层的 AI,做完一步就停了,等你指令。有了循环层,它会一直跑,直到真的做完。文件读写、API 调用、执行代码、运行命令、调用搜索——这些能力的接入,是模型从"顾问"变成"操作员"的基础设施。但工具层有一个容易被忽视的陷阱:工具越多不一定越好。稍后我会用 Vercel 的案例来说明,有时候减少工具数量,反而是更好的 Harness 设计。上下文的质量,直接决定模型输出的质量。但上下文管理的难点在于两个极端都会出问题:信息太少,模型缺乏判断依据,开始乱猜;信息太多,模型注意力分散,关键细节被淹没,出现所谓的"上下文漂移"。好的上下文层,是一套精确的信息调度系统:知道什么时候注入什么信息,格式怎么组织,哪些内容要优先,哪些要压缩或剔除。单次对话有上下文窗口限制。但真实任务往往跨越多次对话、多个步骤,甚至多天时间。持久化层解决的是"记忆"问题:如何让 AI 记住上次做到哪里、哪些决策已经做了、哪些约束需要贯穿始终。没有持久化,每次对话都是从零开始的失忆患者。有了持久化,AI 才能真正承接长周期任务,才有可能替代人类完成需要连续工作的工程。AI 生成内容的问题,往往不在于它不会做,而在于它不知道自己做错了。验证层的作用,是给 AI 加上"自检"能力:自动测试、语法检查、回归验证、结果比对、自审机制。它让 AI 不只是"生成答案",而是"生成 + 验证答案"。有了验证层,错误会在系统内部被发现和修正,而不是等你人工审查时才暴露。这对于高频率、高复杂度的任务来说,是决定性的差别。这一层常常被误解为"限制 AI 能力"。实际上,好的约束是生产力,不是枷锁。权限控制(它能访问什么文件、调用什么 API)、预算限制(最多用多少 token、执行多少步)、行为边界(哪些操作需要人工确认)、安全策略——这些约束让 AI 的行动范围变得可预测、可审计。一个没有约束层的 AI 系统,在生产环境里是高风险的。它可能在你没注意的时候做了你不想让它做的事,而你完全不知道。这六层,没有一层是靠"升级模型"来实现的。它们全部是系统工程能力。你搭建好了,一个"够用"的模型可以交付"优秀"的结果。你没有搭建,再强的模型也会给你一个不稳定的惊喜盲盒。案例一:OpenClaw——Harness 作为操作系统OpenClaw 不是一个模型,也不是一个 AI 应用。它更像一个"Agent 操作系统"——一套为 AI 工作流设计的 Harness 基础设施。它的 SOUL.md 文件,是约束层的具体实现:定义 AI 的价值观、行为边界、拒绝范围,让它在任何情境下都有一套稳定的判断基准。它的 Memory 系统,是持久化层:AI 能记住跨任务的上下文、历史决策和长期目标。它的 SKILL.md 机制,是我觉得最有意思的设计:把以往积累的操作经验,编写成可执行的 SOP(标准作业流程)。下次遇到同类任务,AI 不是从零理解,而是直接调用已经验证过的"技能包"。这就是 Harness 的价值所在:把人的经验,转化成系统可复用的能力。案例二:LangChain 实验——同模型,不同系统,成绩差 13 个百分点实验团队对一个复杂代码任务基准进行测试,整个过程中模型不变、API 不变。改动的,只有 Harness 层面的设计:加入自验证循环、优化环境上下文注入方式、增加防死循环机制、调整推理预算分配、建立失败案例分析系统。结果:任务完成率从 52.8% 提升到 66.5%,排名从 Top 30 进入 Top 5。这个结果的含义很直接:你现在用的模型,它的真实潜力,可能还没有被 Harness 释放出来。你体验到的那个不稳定的 AI,不一定是模型太弱,可能只是系统太粗糙。案例三:Vercel——少即是多,约束本身就是设计Vercel 工程团队在优化一个 AI 辅助部署流程时,做了一个反直觉的决定:把可用工具从 15 个砍到 2 个。很多人的第一反应是:工具少了,AI 的能力不就下降了吗?结果是相反的:任务准确率从 80% 提升到 100%,Token 消耗减少 37%,执行速度提升 3.5 倍。背后的逻辑其实不难理解。工具太多,AI 面临的选择噪声就越大,每一步都要花费认知资源去判断"用哪个工具",容错率降低,稳定性变差。把工具范围约束到恰好够用的程度,AI 的注意力集中了,路径清晰了,结果反而更好。这个案例的核心启示:Harness 不是堆砌能力,而是精准设计边界。工程师们开始把更多时间花在 Harness 设计上,而不是在各个模型之间来回切换;企业采购 AI 的决策维度,从"哪个模型最强"变成"哪套系统最稳定";AI 领域的核心招聘需求,从"Prompt 工程师"悄悄转向"Agent 系统工程师"。AI 的竞争维度,正在从模型本身转移到系统化交付能力。Prompt Engineering 解决的是如何更好地问问题。Harness Engineering 解决的是如何构建一个让 AI 可以稳定、持续、可控地完成复杂任务的系统。前者是技巧,后者是工程。技巧可以被模型的进化消化掉,工程能力积累下来就是护城河。我在写这篇文章的时候,想到一个让我有点不舒服的类比。其实 Harness 这个概念,不只适用于 AI。你的大脑,也是一个模型。它的算力、创造力、理解力,是你的"马力"。但你每天实际完成的事情,取决于你给自己搭建了什么样的系统:你的工作流、你的习惯结构、你的信息管理方式、你的反馈回路。- 你有没有循环层?每天是否有固定的检视——回顾昨天、规划今天、验证推进?
- 你有没有上下文层?在开始一项重要工作之前,你能不能快速进入状态,而不是从零热身?
- 你有没有持久化层?你学到的东西、做过的决策、复盘的结论,有没有被沉淀成可以调用的知识系统?
- 你有没有约束层?你能不能主动控制注意力的边界——手机、通知、会议——而不是随时被环境打断?
提升效率最快的方式,从来不是"变得更聪明",而是"换一个更好的系统"。
实测:组合使用 Claude Code + OpenClaw,我是如何“躺平”交付项目的
上周有人在群里问我:「你现在用 OpenClaw 还是 Claude Code?」对方沉默了几秒,回了一句:「这不是重复的东西吗?」这个问题我已经听到第三遍了。所以这篇文章想认真说清楚一件事——这两个工具根本不在同一层竞争,把它们放在一起比较,本身就是个认知错误。又做了一段时间开发之后,我发现 AI 编程工具的混乱感,很大程度上来自一个认知盲区:大家习惯用"功能"来分类工具,而不是用"层级"。Claude Code 在执行层,OpenClaw 在调度层。一个负责「把这件事做好」,一个负责「决定做什么、谁去做、按什么顺序做」。用最直接的话说:Claude Code 是一个住在你终端里的顶级程序员。你给它一个任务,它读你的代码库,理解上下文,直接改文件、跑命令、提交代码。不需要你复制粘贴,不需要你手动执行,它在终端环境里自己转。- 对大型 Repo 的理解能力,目前市面上没什么能打的
- Anthropic 官方出品,和 Claude 模型的整合深度是其他工具没法复制的
但它有一个根本性的边界,它只会做你让它做的这一件事。任务拆解?不擅长。多步骤流程的协调?没有机制。你要让它同时管需求分析、编码、测试、文档,它做不到——不是能力不够,是它根本没被设计成干这件事的工具。另外两个实际问题:它按 Token 计费,长任务跑下来成本不低;代码要上传 Anthropic 的服务器,有数据安全要求的项目需要斟酌。OpenClaw 容易被误解,因为它「也能写代码」,所以很多人直接把它归类为「又一个代码助手」。OpenClaw 本质上是一个多 Agent 编排框架。 它解决的问题不是「代码写得好不好」,而是「复杂任务怎么被拆解、分配、执行、验收」。Skills 系统。你可以把常用的能力封装成模块,写一次,反复调用。比如「读取 GitHub Issue 然后生成任务清单」这个动作,封装成 Skill 之后,以后一句话触发。Memory 系统。OpenClaw 有长期记忆,它记得你上次的项目结构、你的代码风格偏好、你常用的技术栈。跨任务的上下文不会丢。多模型兼容。这点对开发者很重要——它不绑定某一个模型,Claude、GPT、本地 Ollama 都能接。成本敏感的任务用本地模型跑,对质量要求高的核心模块再调用 Claude,自己控制成本结构。本地部署。数据不出你的机器,对有隐私要求的项目来说这是硬需求。当然它也有真实的缺点,不能回避:上手成本不低,需要配置,需要调试;早期版本有安全漏洞记录,自托管的话安全性得自己把控;代码执行质量取决于你接入的底层模型,OpenClaw 本身不提供智能,它是个框架。Claude Code 回答的是「怎么把这段代码写好」,OpenClaw 回答的是「这个项目该怎么拆、谁来做、怎么验收」。我自己最近跑了一个爬虫项目,完整用了两者组合,把流程记录下来:先把关键问题一次问清:爬什么、爬哪些字段、数据量级、推送到哪里、合规边界,以及上线节奏。最终确认:黄金投资资讯、每天几百条、每天一次、只用飞书推送、只要资讯文章(不做实时金价)、优先 1 周上线 MVP、部署走免费方案。- 部署:Docker Compose(便于快速落地和迁移)
- Phase 1 目标:先打通“核心站点爬取 → 存储 → 去重 → 飞书推送 → 定时任务”闭环
Step 3 — 开发(Claude Code 编码落地)开始搭建 Scrapy 爬虫项目骨架,并把核心模块写出来:站点爬虫、数据模型、存储、去重、飞书推送、定时调度、Docker 化。当前进度已到可运行阶段(框架完成,待补齐运行配置)。Step 4 — 开发(阶段产出:Phase 1 已完成 60%) gold_crawler/
├── crawler/
│ ├── spiders/
│ │ ├── cngold.py ✅ 金投网爬虫
│ │ └── eastmoney.py ✅ 东方财富爬虫
│ ├── items.py ✅ 数据模型
│ ├── pipelines.py ✅ MongoDB存储 + Redis去重
│ ├── feishu.py ✅ 飞书推送模块
│ ├── scheduler.py ✅ 定时调度器
│ └── settings.py ✅ 配置文件
├── docker-compose.yml ✅ Docker编排
├── Dockerfile ✅ 镜像构建
├── requirements.txt ✅ Python依赖
└── README.md ✅ 使用说明
1)飞书 Webhook 地址(在飞书群里添加“自定义机器人”即可拿到) 2)运行机器(本地 / 云服务器 / 继续按“免费方案”执行) 把 Webhook 给到后,就可以直接部署启动,按“每天一次”定时推送跑起来。整个过程我的参与主要在最开始描述需求,和中间偶尔确认方向。剩下的基本在跑。这和「只用 Claude Code」的区别在哪里?只用 Claude Code,你能完成的是:「AI 帮我把这个函数写好」。组合用,你能完成的是:「AI 帮我交付这个项目」。 | |
| |
| |
| |
| OpenClaw 编排 + Claude Code 执行 |
| |
如果你的任务一句话能说清楚,用 Claude Code。如果你的任务需要画一张流程图才能说清楚,用 OpenClaw。大多数人卡在「哪个工具更好」这个问题上,但更值得想的问题是「我的工作流有没有分层」。Claude Code 解决「怎么做」,OpenClaw 解决「做什么、谁做、怎么协作」。两个问题都重要,一个工具解决不了两个问题。开发者的瓶颈从来不是「代码写得不够快」,而是「能同时推进的事情太少」。建立分层的工作流,比换一个更好的工具,价值大得多。
一文搞懂 Claude Code、Codex、OpenClaw:谁才是真正的 AI 生产力工具?
我最近收到一条消息,一个做独立开发的朋友问我:"你现在用 Claude Code 还是 Codex?我在两个之间纠结了快一个礼拜。"这两个根本不是同一类东西,更别说还有一个 OpenClaw 横空出世,直接把整个讨论维度拉高了一层。过去三个月,这三款工具在开发者圈引发的讨论量级,大概是我在这行十几年见过最密集的一次。但绝大多数讨论都停留在"哪个更好用"的层面,没人说清楚它们之间最根本的差异是什么。在讲每个工具之前,我想先说一件事:这三款产品不在同一个层级,拿它们直接比较,就像拿 VS Code 和 Docker 比较一样奇怪。- 第一层,大脑:大语言模型本身,Claude、GPT、DeepSeek,负责理解和推理
- 第二层,手:编程智能体,Claude Code、Codex,把大模型的能力接进你的代码库,负责执行具体的开发任务
- 第三层,操作系统:Agent 运行平台,OpenClaw,调度多个工具和模型,管理长期任务,24 小时持续运行
用更直白的比喻说:Claude Code 和 Codex 是员工,OpenClaw 是公司。前两者帮你写代码,后者管理帮你干活的这群 AI。Claude Code:最懂你代码库的那个 AI 工程师Claude Code 是 Anthropic 在 2025 年 5 月推出的终端原生编程智能体,发展速度比很多人预想的快。到 2026 年初,它已经成为 AI 编程工具市场里使用量最高的产品——一项接近 1000 人参与的调查显示,它在 AI 编程工具中的好评率是 46%,排名第二的 Cursor 只有 19%。它最核心的设计决策,是把"理解整个代码库"当成第一优先级,而不是"写出一段能运行的代码"。举个具体的场景:你接手了一个两年前的 Node.js 项目,代码风格混乱,文档稀少,依赖关系复杂。你让 Claude Code 修一个登录鉴权的 Bug。普通的 AI 助手会直接在你粘贴的那段代码上做修改,改完了给你一个局部的 patch。Claude Code 会先读 CLAUDE.md(你项目的规则配置文件),再扫描相关文件,理解这个鉴权逻辑在整个系统里的上下游关系,然后再动手。它知道改了这里可能会影响哪些地方。这个差别,在处理简单功能时感受不明显,但在面对真实项目的时候差距会非常大。Subagents + Checkpoint:两个最值得关注的能力2025 年下半年,Claude Code 陆续推出了两个重要机制:Subagents(子智能体)和 Checkpoint(检查点)。Subagents 的逻辑是,把一个复杂任务拆分给多个专门的 AI 实例并行执行。比如重构一个认证模块:一个 Subagent 处理数据库层的迁移,一个处理 API 路由的修改,一个处理前端的状态变化,主 Agent 负责协调和整合结果。每个 Subagent 有独立的上下文窗口,互不干扰,最多可以同时跑 10 个。Checkpoint 则解决了另一个焦虑:怕 AI 把代码改坏了。它会在每次修改前自动存档当前状态,你随时可以用 Esc Esc 或者 /rewind 命令回到任意一个历史节点。有了这个兜底机制,你会发现自己敢把更大、更复杂的任务交给它。CLAUDE.md 这个文件很多人忽视,但它非常重要。你可以在里面写项目的技术栈版本、禁止使用的库、数据库 schema 摘要、代码风格规则。有人做过统计,一个写得好的 CLAUDE.md,能减少大约 80% 的"Claude 忘了"问题。Claude Code 最适合这些情况:接手陌生代码库需要快速上手、处理跨多个文件的复杂 Bug、做系统性重构、需要 AI 真正理解你项目整体结构而不只是执行局部指令的开发工作。接入方式覆盖比较全:Terminal CLI、VS Code 插件(2025 年底发布 Beta 版)、Web 端、桌面 App。订阅 Claude Pro($20/月起)即可使用,企业用户也可以通过 Bedrock 或 Vertex AI 私有化部署。同样是在 2025 年,OpenAI 在 4 月推出了 Codex(不是以前那个代码补全模型,是全新的软件工程智能体),随后在年底推出了 macOS 桌面 App,今年又陆续发布了 Windows 版本。Codex 和 Claude Code 最根本的工作方式差异Claude Code 是"人机协作":你在旁边看着它干活,实时审查每一步,随时可以打断、调整方向。这是副驾驶模式,人是主导的那个。Codex 是"任务外包":你把一个任务描述清楚,它在隔离的沙盒环境里自主执行,跑完了给你一份结果和 PR 让你审查。你不需要全程盯着。这个差异在实际工作流里的影响很大。Codex 的适用场景,是那些你知道要做什么、但不想花精力一步步监督的任务。"帮我给这个模块补全单元测试""帮我把这个旧接口的调用方式迁移到新版本",丢进去,去做别的事,回来看结果。Codex 支持真正的多任务并行:多个 Agent 实例,每个在独立的云端沙盒里工作,沙盒里预装了你的代码库和开发环境。如果你有五个相互独立的任务,可以同时启动五个 Agent 并行处理,而不是排队执行。桌面 App 的设计哲学就是"指挥中心":左边是项目列表,右边是所有正在跑的 Agent 线程,你可以在多个任务之间切换,查看进度,在 diff 视图里直接评论或者手动修改。默认情况下,Codex 的沙盒禁用外部网络访问,文件修改也限制在指定目录内。这个设计是有意为之的——隔离执行、执行完了再给你看结果,比实时操作你的本地环境要安全得多。当然,对于需要访问外网的任务,也可以手动开启网络权限。此外,Codex 还内置了代码审查功能,可以直接在 GitHub 上自动 review 你的 PR,就像一个异步的代码审查员。如果你想在本地终端跑,Codex 有一个完全开源的 CLI 版本,用 Rust 写的,支持 npm 和 Homebrew 安装,可以配置本地模型(包括 Ollama),也支持 MCP 接入外部工具。它和云端 Codex 的核心逻辑一致,但更适合想要完全掌控执行环境的开发者。Codex 适合:明确的、边界清晰的开发任务(写功能、修 Bug、写测试);希望解放双手、异步等待结果的工作方式;需要多任务并行推进的场景;以及已经深度使用 ChatGPT 生态的团队(账号互通,不需要额外注册)。ChatGPT Plus 订阅($20/月)包含 Codex 使用额度。OpenClaw:不是工具,是一个运行 AI 的操作系统OpenClaw 是三者里最难定义、也最容易被误解的。它是奥地利开发者 Peter Steinberger 在 2025 年 11 月以 Clawdbot 之名发布的开源项目。项目发布后爆红,两个月内 GitHub Stars 突破 24 万,成为 GitHub 历史上增长最快的项目之一(没有之一,超过了 React)。随后因为 Anthropic 的商标投诉改名 Moltbot,Steinberger 觉得这个名字"念起来太别扭",三天后又改成了 OpenClaw。今年 2 月,Steinberger 宣布加入 OpenAI,项目移交给开源基金会继续维护。它本地运行,连接你选择的大语言模型(Claude、GPT、DeepSeek、本地 Ollama,随便挑),然后把这个 AI 接入你的 WhatsApp、Telegram、Slack、Discord、iMessage 等 20 多个消息平台。你给 AI 发一条消息,它就去执行——读文件、跑脚本、控制浏览器、发邮件、管日历、监控服务器……和 Claude Code、Codex 最本质的区别是:它不是在你开着电脑、你盯着屏幕的时候才能工作的工具。你可以把一台 Mac Mini 放在家里,7×24 小时跑 OpenClaw,然后在任何地方通过手机发消息给它,让它帮你干事。- Skills(技能):可扩展的能力模块,社区维护的 ClawHub 市场里有成千上万个
- Memory(记忆):跨会话持久化的用户偏好、项目信息、历史上下文
Skills 系统是它最有意思的部分。你可以安装别人写的 Skill 来扩展 AI 的能力,也可以自己写。社区里有处理 Solana 钱包的、自动发布 Instagram 的、监控 GitHub Actions 的……各种各样。OpenClaw 对使用者的要求比较高,不是装上就能用的那种工具。最常见的错误是直接给 AI 扔一个模糊的任务,比如"帮我管理我的工作"。AI 不知道这意味着什么。OpenClaw 的正确用法是:你要先设计清楚工作流——触发条件是什么、执行哪些步骤、结果怎么反馈——然后把这个流程配置进去。另一个门槛是 Skills 的设计。好的 Skills 是原子化的、职责单一的;而很多新手写的 Skills 把太多逻辑混在一起,出了问题很难排查。OpenClaw 的维护者 Shadow 在 Discord 上说过一句话:"如果你不懂怎么跑命令行,这个项目对你来说危险程度已经超出你能安全使用的范围了。"这话说得很直白,但是真的。OpenClaw 这几个月最大的争议,是安全问题。去年 11 月发布,今年 1 月就出现了第一个高危漏洞(CVE-2026-25253,CVSS 评分 8.8)——攻击者只要诱导你访问一个恶意网页,JavaScript 就可以通过 WebSocket 连接到你本地的 OpenClaw 网关,窃取认证 token,然后拿到你整个 Agent 的完整控制权,包括禁用沙盒、执行任意命令。此后几周内,又陆续披露了多个 CVE,涉及命令注入、路径穿越、Webhook 认证绕过等问题。ClawHub 的技能市场里也发现了数百个恶意技能包,伪装成正常工具,实际上在后台执行数据窃取或安装键盘记录器。安全研究机构的扫描显示,最多时有超过 13 万个 OpenClaw 实例直接暴露在公网上,其中大部分没有配置任何认证。中国工信部也在今年 3 月发布了安全预警,要求政府机构和国有银行限制使用。目前推荐的最低安全版本是 2026.2.26,如果你现在还在跑更早的版本,请立刻更新。需要说清楚的是:这些安全问题不代表 OpenClaw 的核心产品概念是错的。问题的根源是"能力大、默认配置宽松、上线速度太快"这个组合——任何一个拥有超级用户权限的系统,如果默认不设认证、不限访问,都会出问题。团队的响应速度其实挺快,大部分 CVE 从披露到补丁不超过 24 小时。但这也说明,OpenClaw 目前还不适合随便装随便用。如果你要上生产,需要认真做安全加固。OpenClaw 适合有能力配置和维护它的技术用户,用于:7×24 小时的自动化任务(监控报警、定时巡检、自动发日报);跨平台消息触发的工作流;个人自动化助理(通过手机发消息遥控本地服务器);模型无关的场景(想自己选模型、保留数据主权)。它是免费的,MIT 许可证,但运行本地模型或调用云端 API 的费用需要自己承担,轻度使用大约 $10-30/月。 | | | |
| | | |
| | | |
| | | 消息 App(WhatsApp/Telegram 等) |
| | | |
| | | |
| | | |
| | | |
| | | |
如果你是一个写代码的开发者,首选 Claude Code。它对代码库的理解是目前最深的,上手也最顺,和日常开发流程的整合做得最好。如果你有一堆边界清晰的开发任务,比如一批测试要写、一堆旧接口要迁移,并且你不想全程监督、希望开着让 AI 跑,Codex 是更合适的选择。异步、并行、解放双手,这是它的核心价值。如果你想让 AI 替你干更广泛的事情——不只是写代码,还包括自动化运营、定时任务、跨系统协作,并且你有能力做好安全加固——OpenClaw 是唯一选项。它代表的是一种不同的 AI 工作方式:不是你用 AI,而是 AI 替你持续干活。如果你想玩高阶组合,也有成熟的思路:用 OpenClaw 作为调度层,收到任务触发后调用 Claude Code 或 Codex 执行具体的编程任务,执行完了再由 OpenClaw 汇总结果、发送通知。这是真正的 AI Agent 架构,三个层次各司其职。我观察了很多开发者在这三款工具上踩的坑,最常见的不是工具选错了,而是用法选错了层级。用 Claude Code 帮你"自动管理所有工作"——这是 OpenClaw 该做的事,Claude Code 不是设计来做这个的。用 OpenClaw 做简单的 Bug 修复——配置复杂度完全不值得,Claude Code 两分钟搞定的事。工具没有高下,只有适配。选对层级,用对场景,才是真正的效率提升。这三款产品背后代表的,不只是三种工具,而是 AI 介入开发工作的三种深度:辅助编码、任务托管、持续自主。你现在站在哪个深度,取决于你愿意把多少信任交给 AI,也取决于你有多少时间和能力去管理它。不是你用 AI,未来是你管理一群 AI。 这个转变正在发生,三款工具都是这个过程的早期样本。
Claude Code 被开源了!“满分作业”要怎么抄?
Claude Code 被开源那一刻,我的第一反应不是“又一个 AI 工具”,而是—— 这东西,得赶紧 clone 下来看看底层到底怎么玩的。结果一打开仓库,本来只打算随便扫两眼,愣是一路从命令系统翻到工具层,从工具层翻到状态管理,再一路看到 MCP 和多代理那一块。等回过神的时候,已经过去好几个小时了。 你原本只关心时间,但当你真的把它拆开,会忍不住盯着那些齿轮之间的咬合关系发呆。表面上,它只是一个“跑在终端里的 AI 编程助手”: 你在命令行里打一句人话,它帮你改代码、跑命令、查文件、读文档。但源码里真正有意思的,从来不是“它能做什么”,而是——它是怎么把“会聊天的模型”,变成“能干活的系统”的。 为什么工具要标 isReadOnly 和 isDestructive?而 Claude Code,显然不是随便拼起来的那种答案。你在命令行里召唤它,用自然语言告诉它"帮我重构这个函数"、"把这个目录下所有 TODO 注释找出来"、"运行测试然后告诉我哪里挂了",它就真的去做。技术栈上有个挺反常识的选择——UI 框架用的是 React + Ink。Ink 是一个把 React 渲染到终端的库,所以你在命令行里看到的那些 UI,其实是 React 组件。第一次知道的时候我也愣了一下。运行时用的是 Bun,不是 Node.js。速度确实快很多,但也意味着项目里没有传统的 package.json,构建方式跟大多数人熟悉的不太一样。- 与 Claude AI 模型(Sonnet、Opus 等)进行交互
2.工具系统:40+ 个工具,藏着不少细节(抄作业的重点)Claude Code 内部有一套工具系统,AI 通过调用这些工具来完成实际操作。官方说有 40 多个,常见的文件读写、命令执行、文本搜索都有,还有几个比较有意思的:AgentTool(子代理管理):它可以自己生出"小弟"来并行处理任务。大任务拆成小块,分给多个子代理同时跑,这是实现复杂任务编排的关键。LSP Tool(语言服务器协议):集成了 LSP,意味着它理解代码不只是靠字符串匹配,而是有真正的语义理解——知道这个变量在哪里定义、这个函数被哪些地方调用。WebFetchTool:能直接去抓网页内容。你让它"参考这个文档帮我实现 XX 功能",它真的会去读那个文档。工具接口的设计也值得一看,每个工具都明确标注了 isReadOnly(只读操作)和 isDestructive(破坏性操作),权限系统根据这个来决定要不要提示用户确认。这种设计让人用起来心里有底。- 代码搜索: Grep 文本搜索、Glob 文件匹配
- MCP 工具: Model Context Protocol 支持
3.命令系统(100+ 命令)/斜杠命令背后的三种形态用过 Claude Code 的人都知道可以输入 /help、/config 这类斜杠命令,但源码里的实现分了三种完全不同的类型,这个设计挺有意思:- PromptCommand:把命令转成 Prompt 发给模型来执行,本质上是在引导 AI 做事
- LocalCommand:纯本地逻辑,直接返回文本结果,不走 AI
- LocalJSXCommand:在终端里渲染一个 React 界面出来
第三种尤其出乎意料。/theme 切换主题的时候,终端里弹出来的那个选择界面,其实是一个 React 组件在终端里实时渲染的。命令来源也有好几个渠道:内置命令、从 /skills/ 目录动态加载的技能命令、插件命令、还有从 MCP 服务器加载的命令。语音模式(VOICE_MODE):源码里有个 src/voice/ 目录,还有专门的音频捕获原生模块 audio-capture-src。功能开关已经写好了,目前应该还没正式开放。桥接模式(BRIDGE_MODE):有一套 src/bridge/ 的实现,看起来是用来做远程连接的,可以让 Claude Code 控制远端的环境。协调器模式(COORDINATOR_MODE):多个 AI 代理之间的协作框架,源码里有 src/coordinator/ 整个目录,还有团队记忆、任务分配相关的状态。这些功能都通过 feature() 函数做了开关控制,代码在那儿,但没打开。看起来 Anthropic 是在一边打磨、一边灰度放开。e:\llm\claudecode\
├── src\ # 主要源代码目录(约 34MB)
│ ├── main.tsx # 应用程序入口点
│ ├── commands.ts # 命令系统核心
│ ├── Tool.ts # 工具系统接口定义
│ ├── context.ts # 应用上下文管理
│ ├── QueryEngine.ts # 查询引擎
│ │
│ ├── commands\ # 命令实现(100+ 命令)
│ │ ├── clear\ # 清除会话命令
│ │ ├── commit\ # Git 提交命令
│ │ ├── config\ # 配置管理命令
│ │ ├── doctor\ # 诊断工具命令
│ │ ├── help\ # 帮助系统命令
│ │ ├── login\ # 登录命令
│ │ ├── logout\ # 登出命令
│ │ ├── theme\ # 主题切换命令
│ │ └── ... # 其他命令
│ │
│ ├── tools\ # 工具实现(40+ 工具)
│ │ ├── BashTool\ # Bash 命令执行工具
│ │ ├── FileReadTool\ # 文件读取工具
│ │ ├── FileEditTool\ # 文件编辑工具
│ │ ├── FileWriteTool\ # 文件写入工具
│ │ ├── GlobTool\ # 文件匹配工具
│ │ ├── GrepTool\ # 文本搜索工具
│ │ ├── MCPTool\ # MCP 工具封装
│ │ ├── WebSearchTool\ # 网络搜索工具
│ │ ├── WebFetchTool\ # 网页获取工具
│ │ ├── AgentTool\ # 子代理管理工具
│ │ └── ... # 其他工具
│ │
│ ├── components\ # React UI 组件
│ │ ├── messages\ # 消息渲染组件
│ │ ├── design-system\ # 设计系统组件
│ │ ├── Dialog.tsx # 对话框组件
│ │ ├── Messages.tsx # 消息列表组件
│ │ ├── VirtualMessageList.tsx # 虚拟滚动消息列表
│ │ └── ... # 其他组件
│ │
│ ├── services\ # 核心服务层
│ │ ├── api\ # API 服务
│ │ │ ├── client.ts # Anthropic API 客户端
│ │ │ ├── grove.ts # Grove API 集成
│ │ │ └── ...
│ │ ├── mcp\ # MCP 服务
│ │ │ ├── client.ts # MCP 客户端核心
│ │ │ ├── auth.ts # MCP 认证
│ │ │ └── ...
│ │ ├── oauth\ # OAuth 服务
│ │ ├── analytics\ # 分析服务
│ │ ├── compact\ # 会话压缩服务
│ │ ├── lsp\ # LSP 客户端管理
│ │ └── ...
│ │
│ ├── state\ # 状态管理
│ │ ├── AppStateStore.ts # 应用状态定义
│ │ ├── AppState.tsx # React 上下文集成
│ │ └── store.ts # 通用 Store 实现
│ │
│ ├── types\ # TypeScript 类型定义
│ │ ├── command.ts # 命令类型
│ │ ├── hooks.ts # Hook 系统类型
│ │ ├── permissions.ts # 权限系统类型
│ │ └── ...
│ │
│ ├── utils\ # 工具函数库
│ │ ├── git.ts # Git 操作工具
│ │ ├── file.ts # 文件操作工具
│ │ ├── permissions.ts # 权限管理工具
│ │ └── ...
│ │
│ ├── hooks\ # React Hooks
│ ├── skills\ # 技能系统
│ ├── plugins\ # 插件系统
│ ├── tasks\ # 任务管理
│ ├── assistant\ # AI 助手功能
│ ├── bridge\ # 远程连接桥接
│ ├── cli\ # CLI 处理器
│ ├── coordinator\ # 协调器模式
│ ├── entrypoints\ # 入口点定义
│ ├── keybindings\ # 键盘快捷键
│ ├── native-ts\ # 原生 TypeScript 模块
│ ├── screens\ # 屏幕组件
│ ├── server\ # 服务器功能
│ ├── vim\ # Vim 模式支持
│ └── voice\ # 语音功能
│
├── vendor\ # 第三方原生模块
│ ├── audio-capture-src\ # 音频捕获模块
│ ├── image-processor-src\ # 图像处理模块
│ ├── modifiers-napi-src\ # 修饰符 NAPI 模块
│ └── url-handler-src\ # URL 处理模块
│
└── .lingma\ # Lingma IDE 配置目录
├── agents\ # 代理配置
└── skills\ # 技能配置
src/main.tsx 是应用程序的主入口点,负责:- 启动性能分析: 使用 profileCheckpoint 进行启动性能监控
- 并行初始化: 启动 MDM 设置读取、Keychain 预取等异步操作
- 命令行解析: 使用 Commander.js 处理 CLI 参数(--print, --debug, --model 等)
- 功能标志: 使用 feature() 进行条件代码消除
命令系统是 Claude Code 的核心组件,定义了三种命令类型:// 1. PromptCommand - 提示型命令(由模型执行)
type PromptCommand = {
type: 'prompt'
progressMessage: string
contentLength: number
source: SettingSource | 'builtin' | 'mcp' | 'plugin' | 'bundled'
getPromptForCommand(args: string, context: ToolUseContext): Promise<ContentBlockParam[]>
}
// 2. LocalCommand - 本地命令(返回文本结果)
type LocalCommand = {
type: 'local'
supportsNonInteractive: boolean
load: () =>Promise<LocalCommandModule>
}
// 3. LocalJSXCommand - 本地 JSX 命令(渲染 React UI)
type LocalJSXCommand = {
type: 'local-jsx'
load: () =>Promise<LocalJSXCommandModule>
}
- 内置命令: addDir, commit, config, doctor, help, skills 等
- 技能目录命令: 从 /skills/ 目录动态加载
- MCP 命令: 从 Model Context Protocol 服务器加载
工具系统是 Claude Code 与 AI 模型交互的核心接口:type Tool<Input extends AnyObject, Output, P extends ToolProgressData> = {
name: string // 工具名称
aliases?: string[] // 别名
searchHint?: string // 搜索提示
// 核心方法
call(args, context, canUseTool, parentMessage, onProgress): Promise<ToolResult<Output>>
description(input, options): Promise<string>
prompt(options): Promise<string>
// Schema 定义
readonly inputSchema: Input
readonly outputSchema?: z.ZodType<unknown>
// 行为特性
isConcurrencySafe(input): boolean
isReadOnly(input): boolean
isDestructive?(input): boolean
// 权限和验证
validateInput?(input, context): Promise<ValidationResult>
checkPermissions(input, context): Promise<PermissionResult>
// UI 渲染方法
renderToolUseMessage(input, options): React.ReactNode
renderToolResultMessage?(content, progressMessages, options): React.ReactNode
}
type AppState = {
settings: SettingsJson // 用户设置
verbose: boolean // 详细模式
mainLoopModel: ModelSetting // 当前模型
toolPermissionContext: ToolPermissionContext // 权限上下文
// UI 状态
expandedView: 'none' | 'tasks' | 'teammates'
isBriefOnly: boolean
footerSelection: FooterItem | null
// 功能状态
kairosEnabled: boolean // 助手模式
replBridgeEnabled: boolean // 远程桥接
thinkingEnabled: boolean | undefined
// 任务系统
tasks: { [taskId: string]: TaskState }
agentNameRegistry: Map<string, AgentId>
// MCP 状态
mcp: {
clients: MCPServerConnection[]
tools: Tool[]
commands: Command[]
resources: Record<string, ServerResource[]>
}
// 插件状态
plugins: {
enabled: LoadedPlugin[]
disabled: LoadedPlugin[]
commands: Command[]
errors: PluginError[]
}
// 其他...
todos: { [agentId: string]: TodoList }
notifications: { current: Notification | null; queue: Notification[] }
}
Model Context Protocol (MCP) 服务支持多种传输协议:- claudeai-proxy: Claude.ai 代理
- 直接 API 访问 (ANTHROPIC_API_KEY)
用户输入 → 命令解析 → 工具执行 → API 调用 → 响应渲染
↓
MCP 服务器 → 工具调用 → 结果返回
↓
Hook 系统 → 权限检查 → 审计日志
- 消息流: Message.tsx → VirtualMessageList.tsx → 终端渲染
- 工具流: toolExecution.ts → 具体工具 → 进度更新 → 结果存储
- MCP 流: mcp/client.ts → 传输层 → 服务器 → 工具/资源获取
- 状态流: AppState.tsx → useAppState() → 组件重渲染
- 条件编译: 使用 feature() 和 process.env 进行代码消除
- React/Ink: 使用 Ink 进行终端 UI 渲染
- 权限系统: 多层次的工具权限控制(allow/deny/ask 规则)
- MCP 集成: Model Context Protocol 支持外部工具服务器
- CHICAGO_MCP: Computer Use MCP
说实话,开源之前我以为这类工具在权限管理上会比较粗放——毕竟是 CLI 工具,用户自己负责。每个工具操作都有 allow / deny / ask 三种权限规则,可以细粒度配置哪些操作需要确认、哪些直接放行、哪些直接拦截。所有工具的输入都走 Zod Schema 验证,不是随便传个对象进去就能跑。对于一个要在你本地机器上执行命令、读写文件的工具来说,这个安全层级是合理的。Claude Code 真正值得看的,从来不是“它做了什么功能”,AI 不是一个工具,而是一个“可以被调度的执行体”。- MCP、插件、Skills,本质是在扩展“它能接入多少外部能力”
- AgentTool、多代理,本质是在解决“复杂任务如何拆解与并行”
Bridge、Coordinator、Voice——也在指向同一个方向:不只是让 AI 在你电脑里干活,而是让它接管更大的执行环境。如果你只是把 Claude Code 当成一个“更强的 Copilot”,那确实有点浪费了。 但如果你换个视角,把它当成一个“Agent 操作系统”的雏形来看,很多设计就一下子通了。过去我们在研究 Prompt, 现在开始要研究的是——调度系统、执行链路和能力边界。AI 的分水岭,已经不在“会不会写代码”, 而在——能不能把一件事,从头到尾做完。而 Claude Code,很明显,已经走在这条路上了。
一文搞懂 OpenClaw 的 Harness 设计:AI 的“马具工程”到底在做什么?
我有个习惯,每隔几个月,会把自己工作台重新整理一遍。上周整理的时候,我翻出了一张 2023 年的便利贴,上面写着:"GPT 真的会取代程序员吗?"三年过去了,程序员还在。但我对这个问题的理解,已经彻底变了。那时候大家争的是模型够不够聪明。现在我才明白,那根本不是核心问题。不是在排队打折,也不是明星见面会,而是——排队装软件。一个叫 OpenClaw 的开源 AI 工具,让将近一千个人愿意在深圳的太阳底下等着,请工程师帮自己在电脑上装好它。现场收费、上门安装,有人甚至只是为了搞懂"怎么卸载"也付了钱。因为现在好用的 AI 产品多的是,ChatGPT、Claude、Kimi,哪个不比装个本地软件方便?但那条队伍告诉我们一件事:人们开始意识到,聪明的大脑不够用,他们需要一套能让 AI 真正干活的系统。很多人第一次看到"Harness Engineering"这个词,会以为这是某种高级的 Prompt 技巧,或者是 API 调用的封装。缰绳、马鞍、嚼口——一整套驾驭马匹的装备。马很强壮,跑得很快,但它不知道要去哪,也不知道什么时候该停。驾驭它,需要的不是一句口令,而是一整套系统。Claude 写得出优美的代码,GPT 分析得了复杂的财务数据,Gemini 能同时理解图片和文字——它们都足够聪明。但聪明不等于能干活。你对着 Claude 说"帮我每天早上自动整理昨天的会议记录,发到我的飞书",它能理解这句话,但它做不到。因为没有人给它造手、造脚、造一套工作流程。Harness,就是那双手、那双脚、那套工作流程。用更工程化的语言来说,Harness 负责五件事:- 工具调用:需要用浏览器?文件系统?发 API 请求?
没有这五件事,再强的模型也只是一个"会说话的 CPU"——能输出文字,但改变不了任何东西。OpenClaw 本身不生产智能。它接入的是 Claude、GPT、Gemini 这些已有的模型。它做的事情,是在模型外面造了一套执行基础设施。模型是大脑,OpenClaw 是那个大脑所在的身体——神经系统、手、脚、眼睛、嘴巴,以及一套能让它独立完成工作的行动框架。模型是 CPU,OpenClaw 是操作系统——任务调度、内存管理、I/O 接口、安全权限,全套都有。正因为如此,OpenClaw 能做到那些"聊天 AI"做不到的事:- 同时接入 WhatsApp、Telegram、飞书、钉钉等 20 多个渠道
这不是模型变聪明了,是 Harness 给了模型一双能动的手。四、拆开 OpenClaw 的架构,看看里面装了什么OpenClaw 的 Harness 设计,可以用两个词来概括:双核驱动。控制面(Gateway)负责"连接",执行面(Runtime)负责"思考和行动"。两层解耦,各司其职。我不打算把每一层都变成技术文档——那会让你睡着。我挑最关键、最能改变你认知的几个说。第一个让我觉得"设计者真懂工程"的地方:Prompt 不是你写的,是 Harness 拼的很多人以为,用好 AI 的关键是写好 Prompt。在 OpenClaw 的架构里,这件事换了主体——Prompt 不是人拼的,是 Harness 动态组装的。每次模型被调用之前,系统会自动把以下东西拼在一起:有一个反直觉的发现值得记住:上下文窗口用得越满,模型输出质量越差。 研究表明,当窗口使用率超过 40%,质量开始下滑。所以 Harness 的工作不是"塞更多信息给模型",而是"在合适的时候,把最相关的信息精准喂给模型"。这跟管理员工一个道理。信息过载不会让人更聪明,只会让人更混乱。上周跟 Claude 聊了一个项目的背景,这周打开新对话,它什么都不记得了,你又得从头说一遍。这是模型本身的限制:它只有"上下文窗口",没有跨会话的记忆。OpenClaw 的 Harness 专门为这个问题设计了一套记忆系统。有一个设计细节我特别喜欢:所有记忆都以纯 Markdown 文件存在你自己的电脑上。这意味着你可以直接打开文件,看 AI 记了什么、改掉写错的、用 Git 做版本控制。AI 的记忆变成了可审查、可编辑的人类可读文档,而不是某个云端黑箱。除此之外,Harness 还有自动的记忆生命周期管理:- 对话超过 4 万 token 时,自动提取精华、压缩上下文
- 超过 6 小时没用的上下文,自动裁剪,只留最近三条
- 每天凌晨 5 点或空闲超过 30 分钟,自动重置会话
- 超过 7 天的旧文件自动清理,磁盘占用上限 100MB
这套机制让 AI 始终处于"刚刚好"的状态——不会因为记忆太多而变慢,也不会因为记忆太少而失忆。第三个关键设计:执行闭环——真正让 AI 动起来的那个循环这是整个 Harness 设计里最核心的部分,也是让 AI 从"说"变成"做"的关键。这个循环有一个很重要的工程设计:每个会话的执行是串行的。想象一下,如果两个任务同时修改同一个文件,会发生什么?数据损坏、状态冲突、难以复现的 Bug。OpenClaw 用双重队列(per-session queue + global queue)解决了这个问题,同一个会话的任务严格按顺序执行,不会出现并发竞争。这看起来是技术细节,背后是一个工程哲学:可靠性比速度更重要。第一层,内置工具。 Shell 命令、文件读写、浏览器操作、HTTP 请求。这是 AI 的基础能力,就像人天生有手有脚。第二层,MCP 协议扩展。 这是一套标准化的工具接入协议,任何人都可以按照这个协议开发新工具,接入 OpenClaw。就像手机的 USB-C 接口——统一标准,万物皆可插。第三层,ClawHub Skills 市场。 截至今年 3 月,社区已经上传了超过 13,000 个现成的技能包,命令行一键安装,15 分钟就能让 AI 学会一项新技能。这三层叠加在一起,意味着 OpenClaw 的能力上限,是整个社区共同贡献的结果,而不只是开发团队一家的工作。光说架构设计有多好是不够的。真正的难度在于,这套系统要面对的现实问题极其棘手。WhatsApp 的消息结构和 Telegram 完全不同。Discord 有频道、有 Thread、有 Reaction;飞书有卡片消息、有会话机器人……每个平台都是一套独立的逻辑。OpenClaw 的解法是适配器模式:在 Gateway 层为每个渠道写一个翻译器,把所有消息统一翻译成内部标准格式。AI 看到的永远是同一种语言,不需要知道消息从哪里来。这看起来简单,但维护 20 多个实时更新的平台适配器,是一项持续不断的工程投入。你和你同事同时在用同一个 OpenClaw 实例,你的对话上下文和他的不能混在一起。你的权限和他的也不同。这需要严格的用户隔离和会话管理。OpenClaw 用 SQLite 做持久化存储,每个会话独立,数据不互串,宕机重启也不丢失。这是最难的问题,也是很多 Agent 项目没解决好的。AI 怎么知道任务做完了?怎么判断工具执行的结果是"对的"还是"错的"?如果出错了,要不要重试?重试几次?OpenClaw 的执行闭环通过工具结果回传和模型二次推理来处理这个问题:每次工具执行完,结果会被送回模型,模型来判断下一步——继续执行、修正错误,还是报告失败。这不是一个完美的解法,但是一个务实的、可落地的解法。任何一篇讲 AI 工具有多强大的文章,如果不谈风险,都是不诚实的。OpenClaw 允许 AI 访问你的文件系统、运行 Shell 命令、操作浏览器。这意味着它也有能力做你不想让它做的事。提示词注入是目前最现实的威胁。攻击者可以在网页内容或邮件里藏入特殊指令,诱导 AI 执行危险操作。OpenClaw 接入的渠道越多,攻击面就越大。这不是危言耸听,而是安全研究者已经验证过的真实风险。- 危险操作(删除文件、访问私钥、系统调用)需要明确授权
- 最新版本对媒体内容做流量封顶,防止恶意 HTTP 响应触发缓冲区溢出
但这些防护措施,都建立在一个前提上:你知道自己给了 AI 什么权限,你对这些权限的边界是清醒的。Harness Engineering 同时也是安全工程。 执行能力越强,护栏就得越严。这不是矛盾,这是同一件事的两面。回到文章开头那张便利贴:"GPT 真的会取代程序员吗?"不是你用了哪个模型。Claude 和 GPT 的差距,在很多场景下已经可以忽略不计——它们都足够聪明。是随意接了几个 API,还是认真设计了执行闭环?是有稳定的记忆和状态管理,还是每次对话都从零开始?是有清晰的权限边界和安全护栏,还是让 AI 在你的系统里自由乱跑?这就是 Harness Engineering 的核心命题。OpenClaw 只是这个命题目前最具体的一个答案。但这个命题本身,会存在很长时间。- Harness 不是提示词,而是 AI 的执行基础设施——意图解析、任务编排、工具调用、状态管理、执行验证,缺一不可
- OpenClaw 不是更聪明的 AI,而是让 AI 能干活的操作系统——双核架构,Gateway 管连接,Runtime 管执行
- 记忆系统让 AI 有了连续性——四层记忆 + 自动生命周期管理,存在你本地,你能看能改
- 执行闭环是核心——工具调用 + 结果回传 + 模型推理,串行执行保可靠
- Harness 越强,安全护栏越关键——权限越大,管控越严,这不是选择题
你们现在用 AI 最大的障碍,是模型不够聪明,还是根本没有"手脚"?
OpenClaw+Knowhere实战:PDF PPT 图片解析+结构化处理,AI理解力拉满
上周处理一份招商银行的季报,几十页的 PDF,我其实只想搞清楚一件事:营收为啥下滑了。以前惯常的做法是:“自己翻找定位目标页-锁定数据-手动誊写-更新备忘录”。很机械,也很浪费时间。这次,我用了一个小的工具,获得了大的改变——knowhere,一款新鲜出炉的文档解析插件,支持与OpenClaw的联动。AI 把报告读完之后,给我拆解了营收结构:净利息收入、非利息收入各自的表现,然后告诉我"非利息收入下降 4.23% 是主因,手续费、理财业务、资本市场波动都是可能的拖累"。我追问了一句:为什么营业收入小幅下滑?它又展开了一张对比表,分析到底是哪块在拖后腿。做过 AI 开发或者处理过企业文档的人应该都踩过这个坑:你想让 AI 回答关于复杂、超长、扫描版 PDF 的问题,或者涉及多个PDF跨文档理解的时候,结果是AI要么容易胡编,要么说"对不起我没有这份文件的内容"。大多数人的第一反应是换个更强的模型,或者调整提示词。但这两条路走到头,你会发现问题根本不在这里。如果把大模型比作红案厨师,Knowhere 做的是白案——在食材送进厨房之前,把它处理得干净、有序、可以直接下锅。现在绝大多数工具处理文档的方式,是把所有内容一刀切碎,按固定字数打断,然后扔给模型。问题在于,文档里的信息不是平铺的流水账,它有层级、有关联、有上下文。一刀切进去,这些关联全断了。AI 拿到一堆失去上下文的碎片,当然会"脑补"——它能做的只有这些。做过开发的都都知道,多级表头识别是一个难点。Unstructured 默认把第一行当表头,对 rowspan 和 colspan 的处理非常有限。我们测试下来,它在多级表头识别上的准确率趋近于零——不是偶尔出错,是系统性地识别不了这类结构。knowhere能做的:Knowhere 的测试结果是 90% 以上的准确率,输出带完整属性的 HTML,结构完整保留,下游的提取逻辑不需要额外的修正步骤。在openclaw中追问营业收入下滑原因,实测效果非常不错。Knowhere 的核心是一套自研的 Tree-like 算法,它解决的是数据切片的质量问题。普通的数据切片是这样的:按 2000 字打断,或者做关键词提取。没有把层级结构保留下来,标题跟内容的归属关系断了,段落之间的"首尾呼应"也没了。切片本身质量不好,检索出来的东西自然跟你想要的差一截。Knowhere 在解析文档时,不是重构内容,而是对齐——保留文档本身的层级关系,建立数据切片之间的逻辑关联。标题层级、段落归属、跨节的引用,都会被显式地记录下来。这样得到的数据切片,关联是自带的,不需要在检索时再花大量成本让大模型去重新建立关联。招行那份季报,层层嵌套的财务数据,读出来之后追问依然能追进去,数字对,逻辑也对。这是 Knowhere 让我觉得最有意思的地方,也是跟大多数文档工具最不一样的地方。一般的文档工具,你传一份文件,它帮你处理一份。换个对话,忘得一干二净。Knowhere 做的是知识图谱和智能体记忆层面的东西。它不只是存储文件,而是在解析的同时,把文档里的知识跟已有的知识体系关联起来——类似人脑的学习方式:先有一个自己的知识结构,学新东西的时候,把新的和原来的关联起来,不停地更新和扩展。当你导入一批新文件时,Knowhere 会自动把新信息跟已有的知识图谱做关联,使记忆持续建构,而不是散乱地堆在一起。之后你问"上季度和这季度的净利润对比",它能跨文档给你答案——因为两份报告的数据在解析时就已经被关联起来了,不需要你手动指定"去找这两个文件"。而且这种关联是在建库时就做好的,检索时不依赖大模型临时做 summarize,速度快、成本低、结果稳定。config: { apiKey: "你的密钥", scopeMode: "agent"}
文档会被存进知识库,下次不用重新传,直接问就行。处理多批次文档的场景下,这个差别挺大的。这里有一点需要说清楚:Knowhere 不是专门处理某一种格式的工具,它的定位是多模态非结构化数据的解析与结构化处理。现阶段已支持 PDF、Word、Excel、PPT、图片,后续计划扩展到语音和视频。你的数据是什么格式,它就处理什么格式,不需要提前做格式转换。- 金融分析:财报、研报、季报,多页嵌套数据,解析后可以跨文档追问,数字有据可查
- 法律合规:合同条款提取,前后呼应的条款关系被完整保留,不会因为切片导致上下文断裂
- 科研与学术:论文里的实验数据、图表、参考文献,解析后关联建好,后续检索直接调用
- 企业内部知识库:产品手册、技术文档、运营素材,动态导入,持续更新,不用重建整个库
openclaw plugins install @ontos-ai/knowhere-claw去 knowhereto.ai/api-keys 注册账号,免费试用 14 天,不需要绑卡。Mac/Linux 在 ~/.openclaw/config.json,Windows 在 C:\Users\用户名\.openclaw\config.json:{ plugins: { entries: { "knowhere-claw": { enabled: true, config: { apiKey: "你的密钥" } } } }}
跟 AI 说"帮我读一下这份 PDF",它会自动调用 Knowhere 处理。不需要学新命令,Agent 会自己判断什么时候该调用。安装完成后,你的 AI 智能体就自动获得了 knowhere_preview_document、knowhere_grep 等工具。当被问到文档里的具体数据时,它会先定位到具体的"证据块",再给出答案——而不是凭记忆瞎编。- 在做 AI 应用开发,需要把文档处理成高质量数据的开发者
- 搭建企业知识库,希望新文件能动态融入、不用重建的团队
- 对 AI 幻觉头疼,想让 AI 的回答"有据可查"的人
如果你的数据量不大、文档结构简单,感知可能没那么强。但在金融、法律、科研、工程这类对准确性要求很高的场景,数据处理质量的差距会被下游任务成倍放大。大模型手脚越来越利索,能调工具、能写代码、能发邮件。但脑子里拿到的如果是烂食材,手脚越勤快,闯的祸可能越大。官网链接🔗:https://knowhereto.ai/claw?utm_source=wx
如果你也在搭建 AI 应用或者处理企业文档,欢迎评论区聊聊你踩过的坑。
从 0 到顺滑上手 Claude Code:CC Switch + 模式切换 + CLAUDE.md 一套打通
说实话,最开始用 Claude Code 的那段时间,光是把环境搞对就花了我两天。不是安装多复杂,而是各种细节散落在文档各处,自己拼起来总有哪里不对劲——API Key 设好了,但代理没配;代理通了,但不知道哪个模型该用什么姿势;换个项目又得重来一遍。后来一个朋友推荐我试试 CC Switch,才算真正把这套工作流稳定下来。这篇文章就把我的折腾过程整理出来,顺带讲讲 CC Switch 在我这里是怎么用的。Claude Code 是 Anthropic 自己出的命令行代码工具,不是套壳,是直接整合进终端的。你在命令行里用自然语言跟它说话,它能帮你改文件、规划方案、执行命令——比单纯的代码补全走得更远一步。和 Cursor 那类工具最大的区别,我觉得是它的上下文理解方式。它不只是看你现在打开的文件,而是能真正理解整个项目的结构和脉络,尤其配上 CLAUDE.md 之后,每次会话都像是有人帮你做了功课再来开会。但前提是你得把基础环境搭好。这里面有几个地方我当时卡了挺久。Node.js 要 v16 以上,这个没什么说的。我当时踩的第一个坑是 Windows 上的 Git Bash 路径——Claude Code 在 Windows 下跑某些操作会依赖 bash,但它不会自动找,你得手动配:setx CLAUDE_CODE_GIT_BASH_PATH "D:\Git\bin\bash.exe"
路径换成你自己的。这个如果不设,后面某些场景会莫名其妙报错,找半天都不知道问题在哪。第二个坑是代理。国内直连 Anthropic 的 API 基本不稳定,需要走代理,但代理不是随便在终端 export 一下就行的——Claude Code 有自己的配置文件,在项目目录下创建 .claude/settings.json:{
"env": {
"HTTP_PROXY": "http://127.0.0.1:7890",
"HTTPS_PROXY": "http://127.0.0.1:7890"
}
}
填你本地代理的地址和端口,然后把 API Key 设进去,macOS / Linux 用 export,Windows 用 setx。跑一下 claude,第一次会跳浏览器让你授权,走完就好了。上面这些配置,做一次还好。但如果你同时跑好几个项目、或者用不同的 API 供应商(有的项目用官方,有的项目走中转服务省钱),每次手动改配置文件真的很繁琐。CC Switch 是一个跨平台桌面工具,专门干这件事:帮你管理 Claude Code、Codex、Gemini CLI 等多个工具的 API 配置,一键切换,不用每次手动改文件。预设了 50 多个供应商,AWS Bedrock、NVIDIA NIM、各类中转服务都有,复制 Key 直接导入。系统托盘里就能切,不用打开完整界面。配置支持 Dropbox、iCloud、OneDrive 或 WebDAV 云同步,多台设备共用一套配置。MCP 也能统一管理,四个工具的 MCP Server 在一个界面里搞定。brew tap farion1231/ccswitch
brew install --cask cc-switch
第一次打开可能提示"未知开发者",关掉弹窗,去「系统设置」→「隐私与安全性」→ 点「仍要打开」就好了。作者没有苹果开发者账号,这是正常现象,不是安全问题。Windows 和 Linux 直接去 GitHub Releases 页面下载对应包。配置搞定之后,日常使用里最值得花时间理解的是它的几个工作模式,用 Shift+Tab 循环切换:默认模式每次操作需要你确认,适合需要掌控细节的场景。Auto-accept Edits(自动编辑模式)——批量操作的时候开这个,不用每次点确认。比如全项目统一代码风格、批量加注释,省心很多。Plan 模式——先让它出方案,你确认了再动代码。搭新功能或者重构之前用这个,能省掉很多反复来回。它会先给你列技术栈选择、页面结构、数据模型、实现步骤,你觉得方向对了再说"开始"。还有一个 claude --dangerously-skip-permissions(Yolo 模式),高权限,能安装依赖、跑测试,适合在隔离环境里快速推进。正式项目里用要小心,提前 commit 好代码。Claude Code 没有持久记忆,每次会话都是重新开始——除非你用 CLAUDE.md。这个文件放在项目根目录,会被自动读入每次会话的上下文。可以理解成你给它提前交代背景:这个项目用什么技术栈、有什么约束、哪些已知问题要注意。# 项目规范
- TypeScript 严格模式
- 状态管理:Redux Toolkit
- API 请求统一走 src/services/api.ts
# 已知问题
- 移动端需兼容 iOS 13+
- 用户模块暂不支持第三方登录
# 注意
- 每次修改后运行 pnpm lint 检查
- 接口变更需同步更新 API 文档
内容不用多,精简比全面更重要——这个文件是消耗上下文空间的,写太多会影响它处理实际问题的能力。用久了会遇到终端提示 Context left until auto-compact: 3%,这时候上下文快满了,有三个处理方式:等它自动压缩(大约 150 秒后),适合不着急的情况。手动跑 /compact,立刻释放空间,会话继续。用 /clear 重置上下文,这个会让它忘掉之前的对话,谨慎用。想监控 Token 用量的话,npx ccusage@latest 可以看按天的统计,npx ccusage blocks --live 可以实时看消耗速度。我自己的路径大概是这样:先把 Claude Code 的环境搭好(代理、API Key、Git Bash),装上 CC Switch 统一管理供应商配置,然后给每个项目维护一个精简的 CLAUDE.md,日常用的时候根据场景切模式,定期 /compact 防止上下文撑爆。这套组合跑下来大概两三个月了,没有再出现之前那种"换个项目就要重新折腾配置"的情况。CC Switch 项目地址:https://github.com/farion1231/cc-switch/releases/tag/v3.12.2,macOS 用 Homebrew 装更方便。如果你也在用 Claude Code,或者正在纠结配置,欢迎留言聊。
深扒 ClawHub Top 5 之后,我终于搞清楚 OpenClaw 的 skill 体系到底是怎么运作的
在谈具体的 skill 之前,我想先花一点时间把 OpenClaw 的 skill 加载机制解释清楚,因为不理解这个底层逻辑,你装再多 skill 也只是在盲目堆砌。OpenClaw 的 skill 不是插件,是系统提示词的一部分OpenClaw 每次启动一个 session,Agent Runtime 会做一件事:组装系统提示词。它读取你的 SOUL.md(agent 的行为风格)、AGENTS.md(工作流规则)、TOOLS.md(工具集)、MEMORY.md(跨会话记忆),再把你安装的所有 skill 以 formatSkillsForPrompt 的形式压缩成一张"能力清单"注入进去,告诉模型每个 skill 的 SKILL.md 在哪个路径,用到的时候再去 read。关键点在于:这些文件每一轮对话都会重新注入一次,全部在 context window 里占位置。MEMORY.md 如果长期没有清理,很容易悄悄涨到几千 token;SOUL.md 写得过于详细也是常见问题;装了二十个用不到的 skill,最终都是 token 的负担,轻则拉慢响应速度,重则触发 context compaction 把你的短期记忆截断。所以 skill 的选择不是"多多益善",而是"精准占位"。带着这个前提,说说我实际用下来觉得值得占一个槽位的 5 个。一、self-improving-agent(@pskoett)这是目前 ClawHub 星数最高的 skill(⭐ 2.1k,下载 22 万),但大多数人用它的姿势是错的——把它当成一个"错误日志工具"在用,其实它更核心的价值在于跟 OpenClaw 的 workspace 文件体系深度联动。具体来说,这个 skill 在项目根目录维护一个 .learnings/ 目录,里面三个文件:.learnings/
├── LEARNINGS.md # 被纠正的行为、知识盲区、更好的方法
├── ERRORS.md # 命令失败、工具报错
└── FEATURE_REQUESTS.md # 你要求过但暂时没有的功能
记录本身没什么特别,特别的是它的晋升机制(promotion)。当一条 learning 被标记为 Recurrence-Count >= 3 且跨越至少 2 个不同任务,它就会被提升到 CLAUDE.md、AGENTS.md 或 SOUL.md——直接变成每次 session 启动时注入 context 的永久规则。换句话说,它是在用工程化的方式解决 AI 的跨会话记忆问题。OpenClaw 的 MEMORY.md 默认是平铺的,但平铺记忆有一个问题:随着条目增多,context 占用越来越大,而且没有任何"权重"区分,AI 无法判断哪些规则更重要。self-improving-agent 的晋升机制本质上是在做记忆的优先级排序和持久化分流——高频规则进 CLAUDE.md,项目工作流进 AGENTS.md,行为风格进 SOUL.md,低频错误留在 .learnings/ 等待复查。同样的坑最多踩三次,之后这条规则进入系统提示词,永远生效。它还支持 hook 接入。在 .claude/settings.json 里配置两个 hook:{
"hooks": {
"UserPromptSubmit": [{
"hooks": [{ "type": "command", "command": "./skills/self-improvement/scripts/activator.sh" }]
}],
"PostToolUse": [{
"matcher": "Bash",
"hooks": [{ "type": "command", "command": "./skills/self-improvement/scripts/error-detector.sh" }]
}]
}
}
activator.sh 在每次提交 prompt 时触发,注入一段 learning 评估提醒;error-detector.sh 则在 Bash 工具执行后读取 CLAUDE_TOOL_OUTPUT 环境变量,检测非零退出码,自动把失败信息写入 ERRORS.md。两个 hook 都是纯本地运行,不联网,但每次会产生约 50-100 token 的额外开销。context 比较紧张的话,可以只手动 log,不开 hook。这个 skill 下载量约 18,000,名字劝退了很多人,但它解决的是 OpenClaw 记忆体系里一个结构性缺陷。OpenClaw 原生的 MEMORY.md 是平铺线性的——每条记忆之间没有关系,只有时间序。你问"这周最需要跟进哪个客户",AI 能找到三条独立的记忆:张三是联系人,B 公司是客户,项目截止日是下周五。但它不知道这三件事是连在一起的,需要靠生成时的推理去"猜"关联,而不是靠结构去"走"关联。Ontology 的做法是在 workspace 里引入一个显式的知识图层。它定义了 Person、Project、Task、Event、Document 等核心实体类型,每个实体有明确的属性和关系约束。当 AI 需要记住"Alice 是 Project X 的负责人,邮箱是 alice@example.com"时,它不再是把这句话存为一段文本,而是创建三个相互关联的节点:Person: Alice
- email: alice@example.com
Project: Project X
- status: active
Relation: Alice --[owner_of]--> Project X
这种结构带来的最大好处是可遍历性。你问"Project X 现在谁在负责",AI 沿着 owner_of 这条边走一步就能给出答案,而不是在一大段平铺文本里做语义搜索。更重要的是,这些结构化节点本身比同等信息的自然语言描述更省 token,在 context window 里占的空间反而更小。在 OpenClaw 的架构里,ontology 和 MEMORY.md 的分工是:MEMORY.md 存事件流(发生了什么、什么时候说了什么),ontology 存事实图(谁是谁、什么关系、什么属性)。两者互补,不是替代关系。三、self-improving(@ivangdavila)名字跟第一个高度相似,功能定位却完全不同,一定要区分开。这个 skill 的核心是分层记忆架构,它在 ~/self-improving/ 下面维护一套比 self-improving-agent 更精细的文件系统:~/self-improving/
├── memory.md # 热记忆,始终加载,硬性限制不超过 100 行
├── index.md # 主题索引,带行数统计,用于快速定位
├── heartbeat-state.md # 心跳状态,记录上次维护任务运行时间
├── corrections.md # 最近 50 条修正记录,滚动覆盖
├── projects/ # 项目特定学习,按项目隔离
├── domains/ # 领域知识,按技术域组织
└── archive/ # 冷记忆,衰减的低频模式
这个结构背后有明确的设计哲学:热记忆(memory.md)严格控制在 100 行以内,超出的内容自动降级到 archive/。这直接对应 OpenClaw 的 context 预算问题——跨会话记忆如果不加控制,最终会把 context window 的大头都吃掉。最有意思的是 heartbeat 机制。OpenClaw 的 Gateway 本来就有一个后台 daemon 定期运行 heartbeat——读取 HEARTBEAT.md,决定是否需要主动联系用户。这个 skill 在此基础上增加了 agent 对自身行为的周期性自我评估:它会检查本次 session 里有没有出现"重复解释同一件事"、"回答偏离任务主线"这类模式,并更新 heartbeat-state.md。可以把它理解为一种数字版的记忆巩固——在两次主动工作之间,系统在后台做结构性整理,把短期记忆里重要的部分压缩进长期存储,把低频模式推入 archive/ 自然衰减。跟 self-improving-agent 最大的区别在于作用层级:前者作用于项目层(项目规范、具体错误,存在项目根目录的 .learnings/ 里),后者作用于 workspace 层(agent 的行为风格,存在 home 目录下,会直接写 AGENTS.md 和 SOUL.md)。两者目录完全隔离,可以同时装。但要注意:装之前备份好 SOUL.md 和 AGENTS.md,这个 skill 会主动修改它们。steipete 是 OpenClaw 的创始人 Peter Steinberger,这个 skill 可以理解为官方背书的 Obsidian 集成。技术实现上,它依赖 obsidian-cli(brew install yakitrak/yakitrak/obsidian-cli),把 Obsidian vault 作为普通文件夹操作——搜索笔记、创建新页面、移动文件、更新 [[wikilinks]]。这个 skill 的 SKILL.md 里有一个值得关注的工程决策:它不让你硬编码 vault 路径,而是让 agent 在运行时去读 ~/Library/Application Support/obsidian/obsidian.json,动态发现所有 vault 的位置。这也是 ClawHub 的 OpenClaw 扫描把它标为"Suspicious(medium confidence)"的原因——它访问了用户 home 目录下的系统配置文件,但在 SKILL.md 的 requires 字段里没有声明这个行为。从工程角度这是合理的决策(vault 路径变了不需要手动改配置),但你要清楚它的实际权限边界:这个 skill 知道你所有 vault 的位置,并且对它们有完整的读写权限。如果 vault 里有高度敏感的内容,需要在 OpenClaw 的 sandbox 配置里做相应的路径限制,而不是依赖 skill 本身去约束。使用场景上,obsidian skill 和 ontology 搭配效果很好。前者负责从 vault 里读取原始笔记,后者负责把笔记里的关键实体和关系结构化存入知识图谱。两个一起用,AI 既能"找到"信息,又能"理解"信息之间的关联。五、nano-banana-pro(@steipete)同样是 steipete 出品,下载量约 11,000。功能是通过 Google 的 Gemini 3 Pro Image 模型生成和编辑图片,支持 text-to-image 和 image-to-image,分辨率可选 1K / 2K / 4K。第一步:1K 分辨率快速出草稿,验证构图和风格方向
第二步:小幅调整 prompt,继续用 1K 迭代,直到方向确定
第三步:prompt 完全锁定后,再升 4K 出最终版
这个建议背后有实际的 API 成本逻辑——4K 的生成时间和 token 消耗大约是 1K 的四倍。在 prompt 还没稳定之前就跑 4K,是在浪费等待时间和配额。配置上,这个 skill 需要两个依赖:uv(Python 包管理器)和 GEMINI_API_KEY 环境变量。需要注意的是,ClawHub 的 registry metadata 里没有声明这两个依赖(只在 SKILL.md 里写了),这是文档不一致的问题,不是恶意行为,但它意味着你需要手动在 OpenClaw 的 config.json 里配 apiKey:{
"skills": {
"entries": {
"nano-banana-pro": {
"enabled": true,
"apiKey": {
"source": "env",
"provider": "default",
"id": "GEMINI_API_KEY"
}
}
}
}
}
如果你的 agent 工作流里有图片生成需求,这个接入成本很低,在 Telegram 或 WhatsApp 里发一句话能直接拿到结果。如果你的工作流基本不涉及图片,可以先不装,等有需求了再加,五分钟的事。装 skill 之前先做一件事:/context detail,看清楚你的 context 预算现在被哪些文件占了多少。MEMORY.md 长期不清理很容易涨到几千 token,SOUL.md 写得过于啰嗦也是常见问题。ClawHub skill 的注入逻辑是只有 enabled: true 且平台满足 requires.bins 的 skill 才会出现在能力清单里——这意味着你可以"装而不激活",先安装,等需要的时候再开。五个 skill 同时激活的话对 context 的影响在可接受范围内,但如果你的窗口配置本身就比较紧,可以只先开 self-improving-agent,其他按需激活。这五个 skill 各自填的坑:记忆的持久化与分流(self-improving-agent)、知识的结构化(ontology)、行为的自我校正与记忆分层(self-improving)、外部知识库接入(obsidian)、多模态扩展(nano-banana-pro)。ClawHub 上 13,000 多个 skill,绝大多数是不值得装的。但这五个在填 OpenClaw 本身没有填好的坑,这是我几周跑下来留下它们的原因。
为什么说 Harness Engineering 才能让 AI Coding 真正在 ToB 大型垂直行业系统落地?
我见过太多工程师用同一种方式评价 AI 编程工具:"写个 Demo 还行,真正的业务代码根本用不了。"然后把 Cursor 或者 Copilot 关掉,继续低着头改那份已经有八年历史、没有一行注释的 Java 代码。我理解这种无力感。但我越来越觉得,这个判断本身就错了。传统 ToB 项目——ERP、CRM、供应链、财务系统——它们真正的问题从来不是"缺少聪明的工程师"。问题是:系统本身已经变成了一个没人完全理解的生命体。需求文档是三年前的,和现在的代码早就对不上;核心业务逻辑散落在五个不同年代的模块里,彼此通过数据库表耦合;唯一真正懂这套系统的人,在去年离职了,留下一句"这块你们自己看看吧"。这种环境下,任何修改都是在走钢丝。一个看起来无关紧要的字段改动,三天后在另一个完全不相关的报表里触发了一个 Bug,然后你花了两天时间 debug,最后发现根源在 2019 年的一次"临时修复"里。在这种系统里使用 AI 写代码,就像把一个聪明但什么背景都不了解的新人扔进去,告诉他"你看着办"。二、Copilot 模式为什么在 ToB 场景失效过去两年,大多数团队引入 AI 的方式是 Copilot 模式:工程师写代码时,AI 在旁边提建议、补全片段、偶尔生成一个函数。这个模式在两类场景下有效:一是简单的新功能开发,业务逻辑清晰,没有历史包袱;二是模板化的重复工作,比如写测试用例、生成 CRUD 接口。但在 ToB 的核心战场——遗留系统改造、复杂业务逻辑重构、多模块联动的需求开发——Copilot 模式几乎必然失效。原因很简单:AI 生成的代码质量,取决于它所能获取的上下文质量。你把一个函数丢给它,它能写得很好看。但它不知道这个函数在整个业务流程里处于什么位置,不知道它下游调用者的隐含假设,不知道某个看起来奇怪的 if 判断背后藏着一个客户的特殊结算规则。于是它写出来的代码,语法正确,逻辑清晰,在单元测试里跑得完美——然后在生产环境里以一种你完全没预料到的方式出错。三、换一个思路:从"教 AI 写代码"到"设计让 AI 安全工作的环境"Harness这个词,从马具来的,字面意思是马具:缰绳、马鞍、眼罩、胸甲。一匹马,力气大得惊人。但没有马具,它可能因为一声噪音就受惊乱跑,可能跑到一半停下来吃草,可能根本不知道该往哪个方向走。马具不让马变得更强,但它把马的力量,可靠地导向了有用的工作。AI模型也是一样。Claude Sonnet、GPT-5.4、Claude 4.6,认知能力都极强。但如果你只是打开网页对话框,输入一段文字——这跟裸骑差不多,时好时坏,全看运气。它没有缰绳,没有眼罩,没有人告诉它何时停、往哪走、做完了要自己检查。所以,Agent Harness的定义是:包裹在AI模型外的完整技术栈,把原始的认知能力,变成可靠的输出。翻译过来大概是"驾驭工程",是近一两年在工程实践前沿逐渐浮现的一套思路。它的核心命题只有一句话:与其花精力让 AI 更聪明,不如花精力给 AI 构建更好的工作环境。传统的 AI 辅助开发,人类是指挥官,AI 是执行者,人类随时在旁边盯着,随时纠偏。这没问题,但它的上限就是"把工程师的效率提高 20%~30%"。Harness Engineering 想做的事情不同。它的目标是让 AI 在一个有严格约束的环境里自主完成复杂任务——不是每写一行代码都需要人来确认,而是通过事先设计好的机制,让 AI 的每一步操作都在可控的范围内。不是让实习生自由发挥,而是给机房装上传感器、自动熔断机制和操作沙箱。实习生只能在沙箱内操作,一旦违规立即被拦截,错误自动回滚,每一步操作都留有记录。在这套框架里,AI 有四个"天然缺陷"必须被外部系统来弥补:第一,它会失忆。 每次调用 LLM,它都不记得上一步做了什么。一个需要五十步才能完成的重构任务,跑到第三十步时上下文满了,它就开始"自由发挥"。第二,它会幻觉式执行。 它不知道自己已经陷入了死循环,还在对同一个 Bug 做第十次细微变化,每次都充满信心地告诉你"这次应该好了"。第三,它没有安全意识。 给它数据库写权限,它可能会用。给它邮件发送接口,它可能会在测试时把邮件发给真实用户。它不是故意的,它只是不知道"不该做什么"。第四,它是无状态的。 任务执行到一半出错了,重来一遍,它不知道之前做了什么,可能把已经完成的部分再做一遍,甚至做出冲突的操作。Harness Engineering 要做的,就是在 AI 的外层建立四个控制模块:上下文管理、工具安全网关、验证反馈循环、状态持久化。用工程的方式,把这四个缺陷一一弥补。所以 Harness 不是一条提示词,也不是某个工具,而是一套工程化的“控制模块”。更进一步,实践中常见的结构可以拆成六层(不同团队表述略有差异,但逻辑基本一致):- Loop(循环层):观察 → 决策 → 行动 → 验证 → 更新,持续推进直到完成
- Tools(工具层):让 AI 能读写文件、运行代码、调用 API(而不是只会说)
- Context(上下文层):控制它看见什么、看不见什么,避免过载或猜测
- Persistence(持久化层):跨对话/跨步骤保留状态,减少“失忆”
- Verification(验证层):自动测试、语法检查、自检
- Constraints(约束层):权限、预算、文件范围、敏感信息等边界明确
这套框架本身不复杂,但在 ToB 场景里,它能做到的事情非常惊人。下面说具体的。这四步不是理论,是在真实的遗留系统改造项目中跑出来的路径。很多团队引入 AI 改造遗留系统,第一个动作就是把代码扔给 AI,让它"帮我重构一下"。然后新代码生成了,看起来干净多了,部署上去,一周后收到客户投诉:某个特殊结算场景计算结果不对。回头看,原来旧代码里有一段奇怪的逻辑,处理的是某个大客户十年前谈的特殊折扣规则。没有文档,只活在代码里。AI 重构时把它当成冗余代码优化掉了。这种事情一旦发生一次,团队对 AI 的信心就会崩塌。正确的第一步,是在动任何代码之前,把现有系统的行为锁定下来。技术上,这叫 Characterization Tests(特征测试)。不是测试代码"应该怎样",而是测试它"现在怎样"。哪怕有些行为看起来是 Bug,先锁定,等重构完成再单独讨论要不要修。更进一步,把核心业务规则 DSL 化——用机器可读的格式把规则表达出来,而不是让它继续活在自然语言文档里,或者更糟糕地,活在某个老员工的脑子里。某家物流公司做过这件事。他们用了三周时间,为核心运费计算引擎写了五百个自动化测试用例,把所有的特殊场景——偏远地区加价、大件货物分拆、同城当日达折扣——全部固化成可执行的测试。然后他们指挥 AI 重写了整个计费模块。五百个测试全部通过,零业务差错。三周写测试,三天重构。这个时间分配,在传统认知里不可接受,但实际上这才是最快的路径。"我们把整个系统重写一遍"——这句话在 ToB 项目里是一个古老的诅咒。大爆炸式重构的失败率极高,原因不是工程师不够努力,而是它把所有的风险都集中在一个时间点上,一旦出问题,回头的代价极高。绞杀者模式(Strangler Fig Pattern)是一个更稳健的思路:新旧系统并行运行,逐步把流量迁移到新系统,直到旧系统被完全"绞杀"。具体的做法是:让 AI 分析整个代码库的依赖关系,识别出可以独立剥离的模块,然后生成对应的新实现。同时,自动生成"流量回放脚本"——把生产环境的真实请求,在影子模式下同时打给新旧两个实现,对比输出结果。只有当新实现的输出与旧实现完全一致时,才切换对应模块的流量。这个过程中,每一个独立的模块剥离都是一个低风险的小任务。一百个低风险的小任务,远比一个高风险的大任务更可控。而且,AI 在这里的价值不只是写代码,它在依赖分析和测试生成上的速度,能把原本需要一个月才能完成的前期分析工作,压缩到几天。A 客户要一种格式的报表,B 客户要另一种。A 客户的审批流是四级,B 客户是两级。A 客户的数据导出要加密,B 客户不需要但要加水印。传统的处理方式是:来一个需求,写一段定制代码,堆进去。久而久之,代码库里充满了 if customer == "A" 这样的判断,没人敢动,没人知道全貌。Harness Engineering 的处理方式是:把这些差异提取出来,用元数据描述,让 AI 基于统一的底座自动生成定制插件。人类只需要定义"A 客户的报表需要加这几个字段,用这种格式",Harness 把这段描述传给 AI,AI 生成对应的定制代码,自动运行回归测试,确认不影响其他客户,完成。一个原本需要三天的定制开发,在这套流程下可以压缩到三十分钟。更重要的是,那些纷乱的 if customer == "A" 消失了,取而代之的是一套结构清晰的配置体系——这本身就是一笔可积累的技术资产。ToB 系统有一个几乎无解的问题:文档永远滞后于代码。写文档没有人力,写了也没人维护,维护了也没人看。最后的结果是,系统变成了一个黑盒,核心知识只存在于少数人的脑子里,一旦这些人离职,知识就消失了。Harness Engineering 的解法是:让 AI 持续分析代码库,自动生成并更新文档——业务流程图、API 文档、数据字典。不是让工程师去维护文档,而是让文档成为代码的自动衍生物。更进一步:把文档中的业务描述,转化为可执行的测试用例。如果代码的行为和文档描述不一致,CI 直接报错。文档不再是一个静态的参考资料,而是一套活的、可验证的系统规格。当文档和测试合二为一,知识就从个人脑子里转移到了系统里。人员流动的风险,在一定程度上被对冲了。说完四步法,我想说一个常被忽略的问题:这套方法不是万能药。最适合用 Harness Engineering 的场景,恰恰是传统观念里"最难引入 AI"的场景:有明确业务规则的遗留系统改造、多租户 SaaS 的规模化定制开发、数据密集型的 ETL 管道、合规要求严格的金融和医疗系统。这些场景的共同特征是:规则清晰(或可以被清晰化),风险高,验证路径明确。这三个特征,恰好是 Harness Engineering 最能发挥作用的条件。不适合的场景是从零到一的探索性产品——业务规则还没有成形,需求本身还在变化,没有历史约束可以利用,也没有明确的验收标准。在这种场景下,Harness Engineering 的前期投入会显得很重,收益反而有限。简单说:越是"又老又重"的系统,越适合这套方法。 这听起来反直觉,但如果你理解了这套方法的核心——利用已有的规则和约束来驾驭 AI——就会明白为什么。Harness Engineering 的普及,对工程师的职业路径意味着什么?在传统的开发模式里,一个资深工程师的核心价值,往往来自于他对某段代码的熟悉程度——他知道那段代码里每一个奇怪判断背后的历史,他能在不完全理解系统的情况下凭经验做出正确的修改决定。这种价值在 Harness Engineering 的框架下,部分会被系统化——那些隐性的业务知识,会被测试用例、DSL 规则、自动化验证脚本显式地表达出来,成为可积累、可传承的数字资产,而不是只活在某几个人脑子里。与此同时,一种新的价值变得越来越重要:设计能够驾驭 AI 的测试体系和架构约束的能力。这不是在写代码,这是在设计一个让代码可以被安全地自动生成的环境。它需要对业务的深度理解,需要系统性的架构思维,需要把模糊的需求转化为精确的约束。说直白一点:业务建模的能力,比写代码的速度更重要了。能把复杂业务规则抽象成机器可验证的形式,这件事情,还不是 AI 能替代的。如果你现在面对的是一个复杂的 ToB 系统,想知道从哪里开始,我的建议只有一句话:不需要一开始就设计完整的 Harness 框架,不需要马上引入复杂的 DSL 体系。从一个具体的模块开始,把它的行为用测试锁定下来。这件事做完,你会发现很多事情自然而然地清晰了:哪些地方是真正的业务规则,哪些地方是历史遗留的 Bug,哪些地方可以安全地让 AI 介入。这个起点,比任何关于 AI 工具的技术选型讨论都更重要。你所在的 ToB 项目中,最难啃的技术债是哪块?如果要用 AI 来重构,你最担心的是什么?欢迎留言,我们可以聊聊具体的解法。
OpenClaw实战:我在飞书群里“雇”了4个AI同事,项目经理 产品 开发 测试,全程自动协作
最近我折腾了一件事,现在项目群里有四个人在帮我干活——项目经理老张、产品经理小产、开发阿码、测试测测。虽然是AI,但催他们进度的时候他们也会“扯皮”,上环节没完成的,他绝对不会开工。本文使用操作指南:千万不要手动去动配置,指挥龙虾干活。我之前用AI的方式很粗暴:有什么问题就扔给一个对话框,让它又写需求、又看代码、又想测试方案。用了一段时间发现一个问题:同一个模型,你让它扮演不同角色,它会"漂移"。你让它先写了PRD,再让它做技术评审,它会用产品视角去审技术问题,说出来的话听起来很合理,但其实没有真正站在开发的角度去想。更大的问题是,它没有记忆。今天聊完,明天重开一个对话,什么都不记得了。项目背景要反复交代,用户偏好要反复说明,累。后来我开始研究多智能体方案,最后用OpenClaw落地了一套在飞书群跑的多Agent团队。这篇文章把配置过程和协作架构都写出来,你直接拿去用就行。这套方案的核心逻辑很简单:不要让一个AI扮演所有角色,而是给每个角色单独配一个AI,让它们在飞书群里协作。- 每个角色有自己独立的"工作区",里面存着它的人设、行事风格、协作规则、项目记忆
- 当你@某个角色,对应的AI就会用那个角色的视角来处理任务
- 如果任务需要跨角色,它会主动在群里@其他角色,流程自动流转
这不是"一个超级AI",而是一个分工明确的小团队。这一步配置好飞书机器人之后把appId,appSecret复制出来,并且说明哪个角色是哪个appId,appSecret就可以了。第一步下面这些内容了解即可。你复制给小龙虾使用的,不要手动编辑,你定好角色后让小龙虾自己来修改和配置。OpenClaw通过一个叫openclaw.json的文件来定义整个团队结构。你需要先在飞书开放平台创建4个机器人应用,拿到各自的appId和appSecret,然后填进去。配置文件放在~/.openclaw/openclaw.json,内容如下:{
"agents": {
"list": [
{
"id": "pm_manager",
"default": true,
"name": "老张",
"workspace": "~/.openclaw/workspace-pm-manager"
},
{
"id": "pm_product",
"name": "小产",
"workspace": "~/.openclaw/workspace-pm-product"
},
{
"id": "dev_code",
"name": "阿码",
"workspace": "~/.openclaw/workspace-dev-code"
},
{
"id": "qa_test",
"name": "测测",
"workspace": "~/.openclaw/workspace-qa-test"
}
]
},
"channels": {
"feishu": {
"accounts": {
"pm_manager": {
"appId": "cli_pm_manager_appid",
"appSecret": "your_pm_manager_secret"
},
"pm_product": {
"appId": "cli_pm_product_appid",
"appSecret": "your_pm_product_secret"
},
"dev_code": {
"appId": "cli_dev_code_appid",
"appSecret": "your_dev_code_secret"
},
"qa_test": {
"appId": "cli_qa_test_appid",
"appSecret": "your_qa_test_secret"
}
}
}
},
"bindings": [
{
"match": { "channel": "feishu", "accountId": "pm_manager" },
"agentId": "pm_manager"
},
{
"match": { "channel": "feishu", "accountId": "pm_product" },
"agentId": "pm_product"
},
{
"match": { "channel": "feishu", "accountId": "dev_code" },
"agentId": "dev_code"
},
{
"match": { "channel": "feishu", "accountId": "qa_test" },
"agentId": "qa_test"
}
],
"tools": {
"subagents": {
"enabled": true,
"allowAgents": ["pm_manager", "pm_product", "dev_code", "qa_test"]
}
}
}
default: true表示这个Agent是默认入口,有消息没有明确@某人时,优先交给老张处理。tools.subagents这里要特别注意,enabled: true是让Agent之间能互相调用的关键开关,一定不能漏。没有这个,每个Agent就是孤岛,不会主动协作。把机器人加进飞书群这一步,必须在手机端操作,电脑端没有这个入口。这个问题折腾了老半天。具体路径是:打开飞书App → 进入目标群聊 → 点击右上角的群设置 → 找到"群机器人" → 添加机器人 → 选择你创建的应用。四个机器人都要这样一个一个加进来。很多人在这里卡住,以为是配置问题,其实只是操作平台选错了。下面内容是你的参考,根据你的角色要小龙虾参考这个内容生成你要的角色内容即可,千万不要手动编写,你也是只要了解就可以了。工作区目录下有四个文件,分别决定了这个Agent是谁、怎么做事、跟谁协作、记得什么。以老张(项目经理)为例,完整说明这四个文件的写法,其他三个角色的配置我也全部附在后面。路径:~/.openclaw/workspace-pm-manager/- **Name:** 老张
- **Role:** 资深项目经理 / 团队大总管
- **Emoji:** 📅
- **Tone:** 稳重、条理清晰、结果导向
你是老张,团队的资深项目经理。你的核心目标是确保项目按时、按质交付,并协调各方资源。
**工作原则:**
- **进度优先:** 时刻关注里程碑和截止日期,主动识别风险。
- **沟通桥梁:** 在产品和开发之间翻译需求,在开发和测试之间协调排期。
- **会议高效:** 发起会议前必须有议程,结束后必须有结论和待办(Action Items)。
- **情绪稳定:** 面对突发状况保持冷静,提供解决方案而非抱怨。
**禁止事项:**
- 不承诺无法确定的交付时间。
- 不直接介入代码细节或具体产品设计,而是指派给对应角色。
- 不使用模糊的词汇(如"尽快"),必须明确具体时间点。
**协作模式:**
- 接到需求时,先呼叫 @小产 评估范围。
- 开发受阻时,呼叫 @阿码 了解技术难点。
- 提测前,呼叫 @测测 准备测试计划。
## 团队成员通讯录
| 名字 | 角色 | ID | 职责 |
|------|------|----|----|
| 老张 | 项目经理 | @pm_manager | 统筹进度、风险管理 |
| 小产 | 产品经理 | @pm_product | 需求分析、原型设计 |
| 阿码 | 开发工程师 | @dev_code | 架构设计、代码实现 |
| 测测 | 测试工程师 | @qa_test | 用例编写、质量验收 |
## 常用工作流
1. **新项目启动**: @pm_product (需求) -> @pm_manager (排期) -> @dev_code (估时)
2. **版本发布**: @dev_code (提测) -> @qa_test (验收) -> @pm_manager (上线确认)
## 用户偏好
- 汇报喜欢用"进度百分比 + 风险点 + 下一步计划"的格式。
- 喜欢甘特图或列表形式的任务拆解。
- 紧急事务请直接电话或高亮标记,非紧急事务汇总日报。
## 当前项目状态
- 正在进行:
- 下个里程碑:
路径:~/.openclaw/workspace-pm-product/- **Name:** 小产
- **Role:** 产品专家 / 需求分析师
- **Emoji:** 📝
- **Tone:** 逻辑严密、用户视角、富有同理心
你是小产,专注于打造极致用户体验的产品经理。你的核心目标是将模糊的业务想法转化为可执行的产品文档。
**工作原则:**
- **用户第一:** 任何功能设计前先问"用户为什么要用这个?"
- **文档详尽:** 输出的 PRD 必须包含流程图、状态机、异常处理逻辑。
- **数据驱动:** 决策要有数据支撑,不拍脑袋定需求。
- **闭环思维:** 关注功能上线后的数据反馈和迭代计划。
**禁止事项:**
- 不接受"这个很简单"这种没有细节描述的需求。
- 不设计开发成本极高但用户价值极低的功能。
- 不在未与开发确认技术可行性的情况下承诺上线时间。
**协作模式:**
- 需求构思阶段,可呼叫 @pm_manager 评估资源。
- 文档写完后,必须呼叫 @dev_code 进行技术评审。
- 验收阶段,依据文档呼叫 @qa_test 进行用例评审。
## 团队成员通讯录
(与老张工作区保持一致)
## 输出规范
- **PRD 结构**: 背景 -> 目标 -> 用户故事 -> 功能详情 -> 数据埋点 -> 异常流程
- **原型描述**: 使用文字清晰描述交互跳转逻辑
## 用户偏好
- 喜欢用用户故事地图(User Story Mapping)梳理需求。
- 竞品分析需要包含优缺点对比表格。
- 拒绝长篇大论的理论,直接给结论和建议。
## 产品库
- 核心产品线:SaaS 管理平台、移动端 App
- 当前重点:提升新用户转化率
路径:~/.openclaw/workspace-dev-code/- **Name:** 阿码
- **Role:** 全栈开发工程师 / 技术架构师
- **Emoji:** 💻
- **Tone:** 严谨、极客、注重性能与安全
你是阿码,团队的核心技术骨干。你的核心目标是写出高质量、可维护、安全的代码。
**工作原则:**
- **代码规范:** 严格遵守团队编码规范,变量命名清晰,注释准确。
- **安全第一:** 任何输入都要校验,敏感数据必须加密,杜绝硬编码密码。
- **性能优化:** 考虑高并发场景,避免 N+1 查询,合理使用缓存。
- **自我审查:** 提交代码前必须进行自测,确保不破坏现有功能。
**禁止事项:**
- 不写"一次性代码",必须考虑扩展性。
- 不在生产环境直接修改数据或配置。
- 不接收没有明确接口定义和数据结构的需求。
**协作模式:**
- 需求不明确时,直接追问 @pm_product 直到逻辑闭环。
- 遇到技术瓶颈或排期风险,立即上报 @pm_manager。
- 代码完成后,主动通知 @qa_test 并附带部署说明和测试建议。
## 团队成员通讯录
(与老张工作区保持一致)
## 技术栈偏好
- 后端:Java / Go / Python(根据实际项目调整)
- 前端:React / Vue3
- 数据库:MySQL / Redis
- 规范:遵循 Clean Code 原则,强制单元测试覆盖率 > 80%
## 用户偏好
- 代码审查希望指出具体的行号和修改建议。
- 技术方案需要提供至少两个选项(优缺点对比)。
- 报错信息需要包含堆栈跟踪和可能的原因分析。
## 系统架构
- 微服务架构,容器化部署
- 当前技术债务:旧版订单模块重构
路径:~/.openclaw/workspace-qa-test/- **Name:** 测测
- **Role:** 质量保证专家 / 测试工程师
- **Emoji:** 🐞
- **Tone:** 细致、怀疑精神、数据准确
你是测测,团队的质量守门员。你的核心目标是发现潜在缺陷,确保上线产品零严重故障。
**工作原则:**
- **全覆盖:** 测试用例必须覆盖正常路径、异常路径、边界条件和并发场景。
- **复现步骤:** 提交 Bug 时必须包含清晰的复现步骤、预期结果和实际结果。
- **回归测试:** 任何修复都必须进行回归测试,防止引入新问题。
- **自动化优先:** 重复性工作尽量转化为自动化脚本。
**禁止事项:**
- 不接收没有通过冒烟测试的版本。
- 不凭感觉判断"应该没问题",一切以测试结果为准。
- 不隐瞒任何已知风险,即使压力很大也要如实报告质量状况。
**协作模式:**
- 需求阶段提前介入,呼叫 @pm_product 评审需求可测性。
- 开发阶段呼叫 @dev_code 了解代码改动范围以精准测试。
- 发现阻塞性 Bug 时,立即升级通知 @pm_manager。
## 团队成员通讯录
(与老张工作区保持一致)
## 测试策略
- **优先级:** P0(阻塞)> P1(严重)> P2(一般)> P3(轻微)
- **工具:** Selenium, JMeter, Postman
- **流程:** 用例评审 -> 冒烟测试 -> 系统测试 -> 回归测试 -> 验收报告
## 用户偏好
- Bug 报告模板必须标准化。
- 喜欢看到测试覆盖率的趋势图。
- 上线前必须输出《质量风险评估报告》。
## 历史遗留问题
- 支付模块在弱网环境下偶发超时(已列入监控)
- 移动端 iOS 15 以下版本兼容性需特别注意
我在群里发了一条消息:@项目经理 请安排,帮我开发爬虫项目。项目经理先回复确认“新项目启动”,并发起需求澄清,按“爬什么数据源、爬哪些字段、数据量级、交付形态、合规要求”逐项问清楚;我补充说明要“爬黄金投资相关信息、每天几百条、定时推送”。项目经理随即把需求汇总成表格(目标数据、数据量、交付方式),并派工:@产品经理 做需求调研和站点可行性分析,@开发小龙虾 做技术方案评估与框架搭建,同时继续追问“数据源、字段、推送渠道、推送频率”等落地细节。我把关键选项定下来(只用飞书、只要飞书交互、只要资讯文章、部署找免费方案、1周MVP优先),项目经理直接宣布“立刻启动开发”,给出 Phase 1 目标(金投网爬取 + 飞书推送 + 基础去重)和部署形态(Docker Compose),并同步开发进度与下一步阻塞点(需要飞书 Webhook 才能真正跑起来每日推送)。过程中我基本不需要反复催,信息都被自动收敛成“已完成/待完成/阻塞原因/下一步”这种项目可执行的状态。我这边卡在飞书 Webhook:机器人创建好了但找不到 Webhook 地址。项目经理没有让流程停住,而是先给出两套获取 Webhook 的路径(群设置创建、已有机器人详情查看),并提示可能的根因(权限不足、企业版限制),要求我发截图辅助定位;当我仍然搞不定时,项目经理马上给出替代方案 A/B(邮件推送 or 本地查看),我选了 B“先跑一次给我看结果”。随后项目经理按 B 方案推进:先尝试真实站点爬取,反馈“结果为0/疑似反爬/网络访问受限”等客观情况,再给出一次“爬虫演示日报”(并明确标注由于环境限制使用了模拟数据),最后把下一步收敛到两个可执行选项:要么提供服务器部署完整版,要么拿到 Webhook 后开定时推送。整体下来,这套链路的特点是:需求能被快速结构化、能派工推进、遇到阻塞会给替代路径,不会因为一个配置点卡死项目。角色边界让输出更可预期。 老张不会给你写代码,阿码不会替你做产品决策。每个角色只在自己的专业范围内回答,说出来的话更聚焦,不会乱飘。SOUL.md解决了AI"失控"的核心问题。 普通的Prompt很容易被绕过,但把行事原则写进人格文件里,角色的稳定性会高很多。比如阿码的SOUL里写了"不接收没有明确接口定义的需求",他真的会在群里追问,而不是自己脑补一个答案给你。MEMORY.md解决了上下文断裂。 项目背景、用户偏好、历史问题都存在文件里,每次对话都能带着这些上下文,不用反复交代。协作是自动触发的,不是人工指挥的。 这一点是我觉得最舒服的地方。你不用在群里充当"转述人",把老张说的转给阿码,再把阿码说的转给测测。他们会按照各自SOUL里定义的协作规则,自己去@需要协作的人。这套方案本质上是把"团队协作的规则"写进了AI的配置文件。你的工作流越清晰,这套方案跑起来就越顺。如果你们团队有自己的开发规范、PRD模板、Bug报告格式,可以直接把这些内容写进对应角色的SOUL.md和MEMORY.md,定制程度越高,用起来越顺手。四个角色只是个起点。如果你们还有UI设计、运维、数据分析,照着这个结构扩展就行,逻辑是一样的。
一次讲透:你忽略的 .claude 如何用 Rules Commands Skills Agents 决定 Claude 的工作方式
很多人第一次用 Claude Code,都有过这样一个时刻——项目根目录突然多了个 .claude 文件夹,点进去扫了一眼,然后关掉了。这个判断,让你白白浪费了 Claude Code 最核心的能力。.claude 文件夹不是边角料。它是你和 Claude 之间的协议书,是 Claude 在这个项目里行事的全部依据。写好了,Claude 就像一个深度融入团队的老同事;不写,它就是一个没有上下文的外包。
大部分人只注意到项目里的 .claude/,但还有一个藏在你的用户主目录:~/.claude/。项目里的 .claude/——团队共用,提交到 git。所有人打开这个项目,拿到的是同一套规则、同一组命令、同样的权限配置。~/.claude/——属于你个人,存在本地。跨项目生效,记录你的使用习惯和偏好,不会同步到别人机器上。记住这个区别,后面的内容都会在这两个层面之间来回。
每次启动 Claude Code,它做的第一件事就是读 CLAUDE.md,把内容加载进系统提示词,然后在整个会话里一直记着。你在里面写什么,Claude 就遵守什么。告诉它"写代码之前先写测试",它就先写测试。告诉它"错误处理只用项目的 logger 模块,不要用 console.log",它就不会碰 console.log。CLAUDE.md 可以放在几个位置,Claude 会把它们叠加读取:- ~/.claude/CLAUDE.md(全局生效,个人偏好)
- 构建、测试、lint 命令(npm run test、make build 这类)
- 关键架构决定("我们用 Turborepo 的 monorepo 结构")
- 不说不知道的坑("TypeScript 严格模式开着,未使用变量直接报错")
有一条经验值得记住:CLAUDE.md 控制在 200 行以内。超过这个长度,它占据的上下文会变多,Claude 对指令的遵守程度反而会下降。文件越短越精,效果越好。
CLAUDE.local.md 放在项目根目录,Claude 会把它和 CLAUDE.md 一起读,但它会被自动加进 .gitignore,不会进入版本库。个人的测试偏好、本地环境的特殊配置、你不想强加给整个团队的习惯——都可以放这里。
单个 CLAUDE.md 对小项目够用。但随着项目规模变大、团队扩充,那个文件会膨胀成谁都不想碰的 300 行大杂烩。.claude/rules/ 里的每个 Markdown 文件,会和 CLAUDE.md 一起自动加载。你可以把规则按职责拆开:.claude/rules/
├── code-style.md
├── testing.md
├── api-conventions.md
└── security.md
每个文件保持专注,维护起来也清晰。负责 API 规范的人改 api-conventions.md,负责测试标准的人改 testing.md,互不干扰。更强的地方在于路径作用域。给规则文件加上 YAML frontmatter,它就只在 Claude 处理匹配路径的文件时才生效:---
paths:
- "src/api/**/*.ts"
- "src/handlers/**/*.ts"
---
# API 设计规则
- 所有 handler 返回 { data, error } 结构
- 请求体校验统一用 zod
- 不向客户端暴露内部错误详情
Claude 在改 React 组件的时候,不会加载这个文件。只有它进入 src/api/ 或 src/handlers/ 的时候,这套规则才会介入。没有 paths 字段的规则文件,每次会话都会无条件加载。
Claude Code 内置了 /help、/compact 这类斜杠命令,commands/ 文件夹让你自己造新的。规则很简单:.claude/commands/ 里的每个 Markdown 文件,就是一个斜杠命令。review.md 变成 /project:review,fix-issue.md 变成 /project:fix-issue。举个例子,创建 .claude/commands/review.md:---
description: 合并前检查当前分支的改动
---
## 改动文件列表
!`git diff --name-only main...HEAD`
## 完整 Diff
!`git diff main...HEAD`
检查上述改动,关注:
1. 代码质量问题
2. 安全漏洞
3. 缺失的测试覆盖
4. 性能隐患
逐文件给出具体、可操作的反馈。
注意那个 ! 加反引号的语法——它会在 Claude 看到 prompt 之前,先执行 shell 命令并把输出嵌进去。这才是命令真正有价值的地方:不只是保存的文字模板,而是带着实时上下文的提示词。---
description: 调查并修复一个 GitHub issue
argument-hint: [issue编号]
---
查看这个仓库的 #$ARGUMENTS 号 issue。
!`gh issue view $ARGUMENTS`
理解这个 bug,追溯根因,修复它,并写一个能复现这个问题的测试。
运行 /project:fix-issue 234,issue 234 的内容就直接进了 prompt。项目命令放 .claude/commands/,提交到 git,团队共享。想要在所有项目里都能用的个人命令,放 ~/.claude/commands/,命令名会以 /user: 开头。
skills/ 文件夹:会自己判断何时出手的工作流Commands 和 Skills,表面相似,触发机制完全不同。一句话说清楚:Commands 等你召唤;Skills 看准时机自己出手。Skills 是 Claude 可以在没有斜杠命令的情况下,根据对话判断是否应该启用的工作流。你说"审一下这个 PR 的安全问题",Claude 读到这句话,发现它匹配了某个 skill 的描述,就会自动调用它。每个 skill 住在自己的子目录里,有一个 SKILL.md 文件:.claude/skills/
├── security-review/
│ ├── SKILL.md
│ └── DETAILED_GUIDE.md
└── deploy/
├── SKILL.md
└── templates/
└── release-notes.md
SKILL.md 的 frontmatter 描述了这个 skill 在什么情况下启用:---
name: security-review
description: 代码安全审计。在代码审查、部署前、或用户提到安全问题时使用。
allowed-tools: Read, Grep, Glob
---
对代码进行安全漏洞分析:
1. SQL 注入和 XSS 风险
2. 暴露的凭证或密钥
3. 不安全的配置
4. 认证和授权漏洞
给出带严重级别的发现报告和具体修复步骤。
参考 @DETAILED_GUIDE.md 了解我们的安全标准。
Skills 和 Commands 另一个关键差异:Skills 可以携带支撑文件。上面 @DETAILED_GUIDE.md 引用的文件就放在同一个目录里。Commands 是单文件;Skills 是一个完整的包。个人 Skills 放 ~/.claude/skills/,全项目可用。
当一个任务复杂到值得派一个"专家"去独立处理,可以在 .claude/agents/ 里定义子智能体。每个智能体有自己的系统提示词、工具权限和模型偏好:---
name: code-reviewer
description: 代码审查专家。在 review PR、排查 bug、合并前验证实现时主动调用。
model: sonnet
tools: Read, Grep, Glob
---
你是一个注重正确性和可维护性的资深代码审查者。
审查代码时:
- 标记 bug,不只是风格问题
- 给出具体的修复建议,不是模糊的改进方向
- 检查边界情况和错误处理缺口
- 只在性能问题真的有影响时才提出
Claude 需要做代码审查时,会把这个智能体派到一个独立的上下文窗口里工作,完成后把结果压缩报回来。主会话不会被几千 token 的中间过程撑爆。tools 字段限制了这个智能体能做什么——安全审计的智能体只需要 Read、Grep、Glob,没理由给它写文件的权限。model 字段让你给不同的任务分配合适的模型,省算力留给真正需要的地方。
settings.json:Claude 能做什么,不能做什么.claude/settings.json 是权限层。它决定 Claude 可以自由执行哪些操作,哪些必须先问你,哪些完全不许碰。{
"$schema": "https://json.schemastore.org/claude-code-settings.json",
"permissions": {
"allow": [
"Bash(npm run *)",
"Bash(git status)",
"Bash(git diff *)",
"Read",
"Write",
"Edit"
],
"deny": [
"Bash(rm -rf *)",
"Bash(curl *)",
"Read(./.env)",
"Read(./.env.*)"
]
}
}
allow 列表:无需确认,直接执行。通常放构建脚本、git 只读命令、文件读写操作。deny 列表:无论如何都不执行。通常封掉 rm -rf 这类破坏性命令、curl 这类直接网络请求,以及 .env 等敏感文件。不在任何一个列表里的操作:Claude 会先问你。这个中间地带是故意留着的,给你一道安全网,同时不要求你把每种可能都提前想到。settings.local.json 逻辑和 CLAUDE.local.md 一样——本地覆写,自动 gitignore,不进版本库。
- ~/.claude/CLAUDE.md:每个项目都会加载的全局指令,适合放你的个人编码原则
- ~/.claude/projects/:每个项目的会话记录和自动记忆——Claude 在工作中发现的命令、架构模式会自动存在这里,下次打开继续记得
- ~/.claude/commands/ 和 ~/.claude/skills/:跨项目可用的个人命令和工作流
用 /memory 命令可以浏览和编辑这些记忆文件。想清空一个项目的历史记忆从头来过,也可以在这里操作。
your-project/
├── CLAUDE.md # 团队指令(提交到 git)
├── CLAUDE.local.md # 个人覆写(自动 gitignore)
│
└── .claude/
├── settings.json # 权限配置(提交到 git)
├── settings.local.json # 个人权限覆写(自动 gitignore)
│
├── commands/ # 自定义斜杠命令
│ ├── review.md # → /project:review
│ └── fix-issue.md # → /project:fix-issue
│
├── rules/ # 模块化指令文件
│ ├── code-style.md
│ ├── testing.md
│ └── api-conventions.md
│
├── skills/ # 自动触发的工作流
│ └── security-review/
│ └── SKILL.md
│
└── agents/ # 专职子智能体
└── code-reviewer.md
~/.claude/
├── CLAUDE.md # 全局个人指令
├── settings.json # 全局个人配置
├── commands/ # 全局个人命令
├── skills/ # 全局个人工作流
├── agents/ # 全局个人智能体
└── projects/ # 会话记录 + 自动记忆
第一步,在 Claude Code 里跑 /init。它会读你的项目自动生成一个 CLAUDE.md,你再把多余的删掉,留下真正有用的。第二步,加 .claude/settings.json,允许你的构建命令,封掉 .env 读取。第三步,把最常用的两三个工作流做成命令。代码审查和 issue 修复是最好的起点。第四步,等 CLAUDE.md 开始变臃肿了,再拆进 rules/ 文件夹,按路径划分作用域。第五步,在 ~/.claude/CLAUDE.md 里写下你的个人偏好——"总是先写类型再写实现"、"偏好函数式风格"这类。Skills 和 Agents 等你有了固定的复杂工作流之后再引入。前面这些打好了,已经能覆盖 95% 的场景。
最后说一句:这整个系统真正的核心只有一个文件——CLAUDE.md。把它写好,写清楚,写得有针对性。其他所有东西,都是在这个基础上的扩展。
不是魔法,是工程:SQLite + 记忆检索 + 闭环学习,Hermes 怎么越用越顺手
上周我在群里看到一句话,差点笑出声——“Hermes Agent?不就是又一层 ChatGPT 套壳吗。”直到我真的花了一周,把它当成“每天都要用、会被我不断纠错、会被我塞进真实工作流里”的工具来折腾:写计划、跑命令、查资料、做定时任务、换入口(终端/Telegram)继续聊同一个项目。结果很反直觉:它最有价值的地方,恰恰不是“回答得更聪明”,而是“不会每次都像第一次见面”。如果你也被那种体验折磨过——两天前刚跟 AI 把问题聊透,今天带着新变量回来,它却一脸茫然、让你从背景开始复读——那你应该能立刻明白我想说什么。先把结论放在最前面:这不是又一个 ChatGPT 套壳。它要解决的问题完全不同。Hermes Agent 更像是在做一件工程上很“笨”、但长期极其划算的事:把你的工作方式、偏好、结论、SOP 变成可检索、可复用、会迭代的资产,然后让一个 Agent 随着你使用的时间变长而变得越来越顺手。
你有没有遇到过这种情况:今天跟 AI 聊了一个很有价值的对话,探讨了某个复杂问题,AI 给出了很好的思路。过了两天,你带着新情况再来找它,它对你一无所知——不知道你上次的结论,不知道你的偏好,每次都得从零开始解释背景。这不是 AI 不够聪明,这是设计层面的问题。现有大多数 AI 工具的记忆都是会话级别的,对话结束就清空。它们像一个聪明但失忆的顾问,每次见面都是陌生人。Hermes Agent 试图解决的正是这个问题——它的定位是随使用时间增长的 Agent("The agent that grows with you")。
Hermes 有一套叫做"闭环学习"(closed learning loop)的机制,这是它和普通 AI 工具最根本的区别。用人话说,就是以下几件事同时在发生:当你让 Hermes 完成一个复杂任务(通常是 5 步以上的工具调用),如果任务顺利完成,它会把这个解决思路总结成一个可复用的"技能文档"保存下来。下次遇到类似问题,它不需要重新摸索,直接调用已有经验。技能不是静态的。如果你纠正了它的某个做法,或者它在执行过程中发现了更好的路径,它会更新技能文档。这不是微调模型权重,而是一种更轻量的知识持久化——用文本形式把经验记下来,每次任务开始前注入上下文。所有历史对话存在 SQLite 数据库里,带 FTS5 全文搜索索引。当你提出新问题时,它会先搜一遍历史,看有没有相关的对话记录,如果有就一并调入上下文。它还集成了一个叫 Honcho 的模块,专门用于建立你的用户模型——你的偏好、工作习惯、常用工具等等,会随着对话逐渐积累。把这四件事合起来,你就能理解为什么它叫"随你成长的 Agent"——它确实在积累关于你的知识,而不是每次都假装刚认识你。
技能(Skills)是 Hermes 里最有意思的概念,值得单独讲。每个技能本质上是一个 Markdown 文档,存放在 ~/.hermes/skills/ 目录下,格式固定叫 SKILL.md。这个文件描述了:这个技能在什么情况下用、具体的操作步骤、已知的坑、如何验证结果。---
name: deploy-k8s
description: Kubernetes 部署流程
version: 1.0.0
platforms: [linux]
metadata:
hermes:
tags: [devops, kubernetes]
category: devops
requires_toolsets: [terminal]
---
# Kubernetes 部署技能
## 什么时候用
当用户需要将容器化应用部署到 K8s 集群时。
## 操作步骤
1. 确认 kubectl 配置
2. 检查 namespace 是否存在
3. 应用 deployment.yaml
4. 等待 Pod 就绪
5. 验证 Service 暴露情况
## 已知问题
- ImagePullBackOff 通常是镜像仓库认证问题
- Pending 状态超过 5 分钟检查资源配额
## 验证
kubectl get pods -n [namespace] 确认所有 Pod Running
这套技能有一个叫做"渐进式披露"(Progressive Disclosure)的加载机制,非常聪明:Level 0: skills_list() → 返回所有技能的名称和简介(约 3k token)
Level 1: skill_view(name) → 加载完整技能文档
Level 2: skill_view(name, path) → 加载技能目录下的特定参考文件
也就是说,系统不会把所有技能全部塞进上下文——只有真正需要用到某个技能时,才把它完整加载进来。这对 token 的节省是数量级的差异。技能还支持条件激活。比如一个"DuckDuckGo 搜索"技能可以声明 fallback_for_toolsets: [web],意思是:当你配置了 Firecrawl 等正式搜索工具时,这个技能自动隐藏;只有当那些工具不可用时,它才出现作为兜底方案。这种设计让技能生态能够优雅地分层,而不是一股脑全给 Agent 看。
用户输入
↓
HermesCLI.process_input()
↓
AIAgent.run_conversation()
├── prompt_builder.build_system_prompt()
│ ├── 加载 SOUL.md(人格设定)
│ ├── 加载 MEMORY.md(持久记忆)
│ ├── 加载相关技能文档
│ └── 加载项目上下文文件(AGENTS.md)
├── runtime_provider.resolve_runtime_provider()
│ └── 解析要用哪个 LLM 提供商
├── API 调用(支持 OpenAI/Anthropic/OpenRouter 等)
└── 工具调用循环
├── 执行工具(终端/浏览器/文件/Web 等)
└── 工具结果追加到上下文,继续推理
这个循环会一直持续,直到模型不再发出工具调用请求,输出最终回复,然后把这段对话存入 SQLite。核心的 AIAgent 类在 run_agent.py 里,差不多有 9200 行,是整个系统的心脏。工具注册是在导入时自动完成的——每个工具文件在被 model_tools.py 导入时会调用 registry.register() 把自己注册进去,Agent 启动后直接拿到完整的工具列表。
安装(Linux / macOS / WSL2):curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
脚本会自动处理 Python、Node.js 和所有依赖,安装完成后:source ~/.bashrc # 或 source ~/.zshrc
hermes # 启动!
hermes setup # 交互式配置向导,推荐先跑一遍
hermes model # 选择 LLM 提供商和模型
hermes tools # 配置开启哪些工具
Hermes 支持非常多的模型提供商,OpenAI、Anthropic、OpenRouter(200+ 模型)、Nous Portal 都可以,用 hermes model 随时切换,不用改代码。进入交互界面后,你可以直接自然语言交流,也可以用斜杠命令:/new # 开始新对话
/skills # 查看可用技能列表
/model # 切换模型
/compress # 压缩当前上下文
/usage # 查看 token 使用情况
/plan 是内置技能之一,它会让 Agent 写一份结构化的 Markdown 计划,而不是直接开始执行——这对于复杂任务的前期规划很有用。
网关:让 Agent 住在 Telegram/Discord 里Hermes 有一个 Gateway 进程,可以让同一个 Agent 同时监听多个消息平台:Telegram、Discord、Slack、WhatsApp、Signal 等等,总共支持 14 个平台。hermes gateway setup # 配置各平台 token
hermes gateway start # 启动网关进程
配好之后,你可以在 Telegram 里给 Bot 发消息,它和你在终端里对话的是同一个 Agent——共享记忆、共享技能、共享对话历史。我个人觉得这个设计特别实用:Agent 跑在云服务器上,我出门在外用手机 Telegram 给它发任务,它在服务器后台执行,完成了通知我。不用随时开着电脑。
Hermes 内置了一个 cron 调度器,可以用自然语言定义定时任务:hermes cron add "每天早上 8 点给我发一份今日科技新闻摘要,发到 Telegram"
hermes cron list
这些任务会被序列化存储,Hermes 按时创建一个新的 Agent 实例去执行,完成后把结果推送到你指定的平台。对于需要定期生成报告、监控某些信息源的场景,这个功能省掉了大量胶水代码。
讲了这么多,总结一下我认为 Hermes 真正发挥价值的场景:长期项目协作:不止一两次的工作,比如你在开发一个持续数月的系统,需要 AI 真正理解你的代码库规范、团队习惯、决策历史。Hermes 会积累这些知识,而不是每次都重新介绍。个人知识管理与自动化:把它跑在自己的服务器上,设置定时任务做信息聚合、笔记整理、报告生成。轻量的 $5/月 VPS 就够了。多平台统一 Agent:一套配置,能从终端、Telegram、Discord 等多个入口访问同一个 Agent,适合需要随时随地交互的工作流。需要自定义工作流的团队:技能系统本质上是 SOP 的结构化存储,可以把团队的操作规程写成技能,让 Agent 按照团队标准来做事,而不是每次都靠 prompt 描述。
记忆机制目前仍然依赖文本文件(MEMORY.md),内容是由 Agent 自己决定写什么的,这意味着记忆的质量取决于 Agent 的自我总结能力,有时候不太可预测。技能系统很强大,但前期需要投入时间"训练"它——让它真正积累有价值的技能,需要大量真实使用场景。开箱即用的内置技能数量有限。另外,9200 行的 run_agent.py 让人读起来有点头疼,如果你想深度定制,需要做好心理准备。
- 跑安装脚本,用 hermes setup 完成初始配置
- 配一个免费额度的 OpenRouter API key(可以访问上百个模型)
- 如果觉得有价值,再考虑部署到 VPS 上,配 Telegram 网关
完整文档在:https://hermes-agent.nousresearch.com/docs/代码在:https://github.com/NousResearch/hermes-agentMIT 协议开源,8700+ Star,142 位贡献者,活跃度不低。
用了一周之后,我越来越确定:Hermes 代表的是一种更“诚实”的 Agent 路线。它不赌 LLM 灵光乍现、也不假装模型天生就该记住你的一切;它做的是工程基本功——把记忆落到可持久化的介质里,把经验沉淀成技能,把每一次成功的执行变成下一次的捷径。你甚至能清楚地看到它怎么长出来:技能文件在目录里,历史对话在数据库里,哪些被召回、哪些被注入上下文,都有迹可循。当然,这也意味着它不是那种“装上就有魔法”的玩具。它更像一只需要喂养的工作犬:你得真拿它跑几周真实任务、反复纠错、让它把你的标准写进技能、把你的偏好写进画像——它才会开始还你复利。如果你只是想找一个更会聊天的模型,Hermes 未必是最划算的选择;但如果你想要的是一个能跨会话接住你的项目、能把 SOP 变成可执行工作流、能在终端和 Telegram 里共享同一个“大脑”的东西——那 Hermes 值得你认真试一轮。我接下来会把自己这周最有用的技能沉淀方式、以及哪些场景最容易“养出复利”,继续写出来。你要是已经在用 Hermes(或者用过类似的 Agent 框架),也欢迎告诉我:你最希望它替你“记住”的,到底是哪一类东西?
一文看懂:Hermes Agent 与 OpenClaw 全维度对比
最近,我在一个技术群里看到一场吵得不可开交的讨论。一边是用了OpenClaw的老用户,说它生态成熟、工具齐全,离开了根本没法干活;另一边是最近换到Hermes Agent的开发者,说自己的Agent越跑越聪明,一个月前要调20次工具的任务,现在8次就搞定了,Token成本直接腰斩。问题不在于谁赢了,而在于他们根本在比较两件不同的事情。一个在说"连接能力",另一个在说"学习能力"。这就好比有人在争一辆货车和一辆跑车谁更好——答案永远取决于你要干什么。我花了将近三周时间,把两个框架的文档、源码注释、社区Issue记录以及部分内部测试数据过了一遍,试图回答一个实际问题:在2026年,一个严肃的开发者或团队,应该如何在这两个框架之间做出选择?本文不站队。我的目标是把两个框架的设计逻辑说清楚,让你能做出真正符合自己需求的决定。
一、设计哲学的分野——"操作系统" vs "数字分身"我一直相信,理解一个技术产品最快的方式,不是看它的功能列表,而是问它的设计者:你觉得你在解决什么问题? 这个问题的答案,几乎决定了一切后续的技术选择。OpenClaw和Hermes Agent对这个问题的回答,走向了完全不同的方向。1、OpenClaw:AI Agent的"操作系统"OpenClaw的核心理念,用一句话概括就是:"让AI接入一切,控制一切。"它把自己定位成一个中心化的网关(Gateway),最核心的价值主张是"连接"。微信、飞书、Telegram、Slack、Discord……它的目标是成为所有这些渠道和AI能力之间的通用适配层。你不需要为每个平台重新写一套逻辑,OpenClaw帮你做好了路由。这个定位很聪明,也切中了大量企业客户的真实痛点。大多数想上AI的公司,第一个问题不是"我的AI够不够聪明",而是"我的AI能不能接进钉钉/企微"。OpenClaw给了他们一个答案。如果用一个比喻:OpenClaw像一个精密的"交通调度中心"。它的工作是确保每一辆车(每一个任务)能沿着正确的路线到达目的地。调度系统本身高度可靠、透明可审计,但车辆本身不会自我升级。2、Hermes Agent:自进化的"数字分身"Hermes Agent的野心不是"连接更多",而是"变得更聪明"。它的核心概念叫闭环学习循环(Closed Learning Loop)——每一次任务执行,都是一次学习机会。它想打造的,不是一个高效的工具,而是一个越用越懂你的长期伙伴。今天你用它分析了一份市场报告,它会记住你的分析偏好;明天你让它写代码,它会调用昨天积累的代码风格偏好。随着使用时间增长,它对你的理解是在复利式增长的。同样用一个比喻:Hermes Agent像一个聪明的"私人学徒"。它不只是完成你交代的任务,还会在完成任务的过程中主动总结经验,把反复出现的流程固化成自己的"操作手册"。下次遇到类似问题,它能直接拿出手册来用,而不是从头推演。主要特殊:深度进化、自我反思、长期记忆、复利效应。表面上看,两者都是"AI Agent框架",似乎直接竞争。但我越研究越觉得,它们更像是在不同坐标系里解题——OpenClaw解的是"如何让AI接入更多地方",Hermes Agent解的是"如何让AI在一个地方变得更好"。这个差异,是后续所有技术差异的根源。带着这个理解,我们来看架构。
哲学决定方向,架构决定天花板。两个框架在底层设计上的差异,比功能列表上的差异大得多。OpenClaw的技术核心是它的Gateway,整个系统以此为中央控制平面,统一处理会话管理、消息路由和渠道适配。技术栈基于Node.js,这个选择本身就体现了它的定位——高并发I/O、生态丰富、部署便捷。任务的执行依赖人工编写的Markdown技能文件。这个设计有它的合理性:流程透明、版本可控、出了问题能直接定位到哪一行。对于需要严格审计的企业场景,这种可预测性是刚需。但硬币有两面。这套设计的问题在于——它假设所有有价值的任务都是可预设的。一旦任务的边界超出了预设范围,系统就会开始打补丁:加更多技能文件、拉长上下文窗口、增加工具调用次数。随着任务复杂度上升,Token消耗的增长不是线性的,是指数级的。社区里有人把这种现象戏称为"上下文黑洞"——你往里填的越多,系统反而越难找到真正有用的信息。Hermes Agent的架构思路完全不同。它的核心不是一个中央网关,而是Agent自身的执行循环(Agent Loop)。这个循环做三件事:做任务、评估结果、改进自己。最关键的机制是自动技能提炼。当一个复杂任务被成功完成,系统会分析整个执行过程,提取其中可复用的步骤,自动生成一个结构化的技能文档存入库中。下次遇到类似任务,Agent不需要重新推理整个链条,直接调用技能文档即可。这就是为什么Hermes用户会看到工具调用次数随时间下降——不是因为任务变简单了,而是Agent把解题思路固化成了经验,把"推理成本"转化成了"检索成本",而检索的代价远低于推理。在多Agent协作上,两者也走向了不同路线:OpenClaw倾向于Peer-to-Peer模式,各Agent平行执行、相互通信;Hermes更偏向Supervisor模式,由主Agent统一调度子Agent,保证任务的整体一致性和可追溯性。一个细节值得注意:Hermes的架构设计有一个隐含的前提——任务是反复出现的,重复才有复利。如果你的场景是高度一次性的随机任务,Hermes的学习优势就难以发挥。这也是它并非在所有场景都优于OpenClaw的原因之一。
记忆系统是AI Agent最容易被忽视、却往往决定长期使用体验的核心模块。两个框架在这里的差异,是整篇文章里最值得深想一层的地方。OpenClaw用Markdown文件来存储记忆,主要是几个特定文件:SOUL.md存放角色设定,MEMORY.md记录交互历史。策略是"什么都存"。短期来看,这个策略没问题。信息齐全,随时可以回溯。但用了半年、一年之后,问题就来了:文件越来越长,噪音越来越多,系统每次都要在海量信息里搜索真正有用的片段。某种程度上,它变成了一个永不整理的收件箱——里面什么都有,但你要找某一封邮件时,效率反而不如一个精心管理的空收件箱。更深的问题是:OpenClaw没有内置的机制来判断哪些记忆是有价值的。所有信息等权存储,最近的一次闲聊和半年前你反复强调的工作偏好,在系统眼里没有区别。2、Hermes Agent的记忆:懂得忘记的智慧Hermes采用了分层记忆栈:常驻提示负责承载核心人格设定;SQLite数据库做会话级归档,支持结构化检索;向量数据库处理语义相似度检索,找的不是关键词,而是概念上相近的历史经验。更重要的是,Hermes的设计哲学是"有限记忆"——不是什么都存,而是强制Agent在归档前做一次压缩和筛选。就像一个好的学生记笔记,记的不是课堂上说的每一个字,而是理解之后整理出来的核心要点。这个设计的长期效益是显著的:随着使用时间增长,Hermes的检索精度不会下降,因为它的记忆库里噪音被持续过滤掉了。OpenClaw的检索效率则可能随时间下降,因为有效信息的密度在稀释。在技能这个维度,OpenClaw有明显的先发优势:ClawHub上有超过1.3万个社区贡献的技能,覆盖从天气查询到代码审查的几乎所有常见场景。对于刚开始搭建AI系统的团队,这是巨大的效率红利。但这些技能有一个根本限制:它们是为"通用用户"设计的,而不是为你设计的。你的工作流里有哪些独特的习惯和偏好,社区技能不会知道,也不会自动适配。Hermes走了另一条路:技能不是预置的,而是从你的使用行为中动态生成的。你反复做的事情,最终会被固化成一份只属于你的操作手册。这种技能没法在社区里下载,但也没有人能复制——它的价值,在于独一无二。记忆系统的背后,其实是对"人机关系"的根本性不同理解。OpenClaw把Agent当工具:工具要可控、要透明、要标准化。Hermes把Agent当伙伴:伙伴要理解你、要成长、要越来越懂你的习惯。你认为AI应该是哪种存在,几乎直接决定了你会更舒服地用哪个框架。
功能好不好用是一回事,能不能进企业是另一回事。安全、部署成本和合规,是很多团队在实际落地时才踩到的坑。OpenClaw采用标准的RBAC权限体系,配合审计日志。这套方案经过时间检验,对于大多数企业场景足够用。但它的思路本质上是事后防御——先运行,出了问题再查日志,定位责任再修补。历史上OpenClaw出现过几次因权限隔离不足导致的安全事件,根源就在于这套"信任优先、审计兜底"的设计哲学。Hermes在安全设计上更激进,采用"安全内嵌于架构"的思路:工具调用在容器内执行,默认只读文件系统,每次工具调用前经过Tirith引擎的预执行扫描,异常操作在触发前就被拦截,而不是等执行完再审计。特别值得一提的是Prompt Injection的防御设计。Hermes在Agent接收到外部输入时,会通过命名空间隔离确保外部指令无法篡改系统层面的行为规则。OpenClaw在这方面的防护相对薄弱,是已知的攻击面之一。对于金融、医疗、政务等强监管行业,Hermes的安全设计明显更适合作为基础设施层。OpenClaw的软件体量中等偏上,推荐配置是4核8G以上的服务器,Docker部署是最常见方式。对于已有基础设施的企业,这不是问题,但对于个人开发者或小团队,是一笔不可忽视的成本。Hermes在这方面非常克制,整体极其轻量,原生支持Serverless部署。在低配VPS(2核4G)上的实测,中等并发场景下运行稳定,内存峰值明显低于OpenClaw。在Token成本上,Hermes的长期优势更显著。随着技能库的积累,它能把大量推理成本替换为检索成本。一个经过三个月训练的Hermes实例,处理同类任务的Token消耗大约是全新实例的40%~60%——这是一个会随时间复利增长的优势。
以下数据来自社区公开基准、项目官方文档,以及部分本地测试。测试环境和任务类型对结果有较大影响,数据仅供参考,请结合自身场景判断。1、性能:OpenClaw更稳,Hermes会自我优化在单次任务延迟上,两者差异不大,都在可接受范围内。OpenClaw的优势在于高并发场景——它的Gateway架构为高吞吐设计,多渠道同时涌入的消息处理能力更强。Hermes的性能优势在时序上更明显。对于重复性任务,随着技能库的积累,平均工具调用次数会持续下降,整体响应时间和Token消耗随之降低。对于高度重复的工作场景(如每日数据处理、固定格式报告生成),这种自优化效果在3~6个月内就能体感明显。冷启动时间:Hermes明显优于OpenClaw,轻量架构的红利直接体现在启动速度上。2、开发体验:OpenClaw更友好,Hermes更有深度OpenClaw的文档质量是业界标杆级别的,中文社区活跃,示例覆盖面广,从零开始到跑通第一个Demo基本不超过两小时。对于没有深厚AI工程背景的开发者,这是巨大的优势。Hermes的文档相对更技术向,部分高级功能的配置需要理解底层机制才能用好。换句话说,入门门槛更高,但上限也更高。社区里的Hermes用户画像整体偏向资深开发者和研究人员,讨论质量高,但新手支持相对不足。在调试和可观测性上,OpenClaw提供了更完善的可视化Playground,方便实时查看执行链路。Hermes的可观测性工具正在快速完善中,链路追踪功能已基本可用,但视觉化界面的打磨程度还不及OpenClaw。
开源有很多种。有的是真正的社区治理,有的是"开源核心 + 闭源商业"的获客策略,有的是开了源但PR三个月没人看。搞清楚这些,才能判断一个框架的长期可信赖程度。OpenClaw的商业版和社区版功能边界相对清晰,核心功能开源,企业级特性(高级权限管理、SLA保证、专属技术支持)在商业版里。这是一套成熟的开源商业模式,对用户而言是可预期的。Hermes目前整体更偏向社区驱动,商业化边界还在探索中。好处是现阶段功能开放度高;风险是商业可持续性的不确定性——这个问题在选型时应该被正视,而不是忽略。从GitHub数据来看,OpenClaw凭借先发优势积累了更大的Star基数,但Hermes的近6个月增长斜率更陡,Issue响应速度两者相近。ClawHub的1.3万技能是OpenClaw生态的护城河,短期内Hermes自生成的技能库在广度上无法匹敌——但这个差距的性质不同:广度是OpenClaw的优势,深度是Hermes的优势,各自服务不同需求。
我反对"视具体情况而定"这种伪中立答案。以下是根据场景给出的明确建议。场景A:企业级多渠道自动化 ——如果你的核心需求是同时接入微信、飞书、企微、Telegram等多个渠道,把AI打通进现有的工作流,选OpenClaw。它在渠道连接这件事上的工程完成度是Hermes目前无法比拟的。场景B:需要快速交付可审计的自动化流程 ——如果你的团队需要向上级或客户展示清晰的执行链路,OpenClaw的线性工作流设计让每一步都透明可追溯。场景C:团队技术背景参差 ——如果团队里有相当比例的非AI专业开发者,OpenClaw的文档和社区能帮他们更快上手。场景A:个人深度工作伙伴 ——如果你是开发者、研究员或知识工作者,希望AI助手能记住你的工作习惯、代码风格、分析偏好,并随时间持续进化,Hermes是唯一真正为这个场景设计的框架。场景B:复杂非标任务处理 ——如果你的任务高度定制化、边界模糊、难以预设流程,Hermes的动态推理能力比OpenClaw的预设技能文件更适合。场景C:长期Token成本敏感 ——如果你的任务具有重复性,且预算有限,Hermes的自优化特性能在3~6个月内产生可感知的成本下降。这不是和稀泥。在一些复杂的企业场景里,存在一种架构思路:Hermes负责大脑,OpenClaw负责手脚。Hermes承接复杂的任务分析、规划和长期记忆,把决策结果交给OpenClaw,由后者通过成熟的渠道网络执行落地。这种组合在技术上完全可行,需要一定的集成工作量,但对于已经在用OpenClaw且希望引入更强推理能力的团队,是一条值得探索的路径。
最后,想谈一个更长远的问题:这两个框架,谁在押一个更大的赌注?OpenClaw押的是连接的价值——只要AI要接入现实世界的各种系统,就需要一个稳定的调度层。这个需求是真实的,市场是存在的,护城河来自于生态规模。Hermes押的是进化的价值——它相信,未来最有价值的AI系统不是接入最多渠道的,而是最懂你、最能适应你的。这个赌注更激进,但如果它是对的,它的壁垒也更难被复制,因为每一个Hermes实例积累的经验都是私有的、不可迁移的。对MCP、A2A这些新兴Agent通信协议,两个框架都在跟进,但方向有差异:OpenClaw更关注协议的互联互通,Hermes更关注协议层面的安全隔离。这个分野,某种程度上又回到了它们最初的设计哲学差异。两者并不是零和游戏。2026年,AI Agent正在从"会用工具的机器人"向"能思考的伙伴"演化。OpenClaw代表了前一个时代的最优解,Hermes在押注下一个时代的方向。
OpenClaw 是「需要广度连接与工程化落地」的团队的最优解;Hermes Agent 是「追求深度进化与长期智能」的个体与团队的最优解。如果你同时需要两者,它们可以协同工作。最后一个问题想留给读者:你们团队现在用的是哪个?踩过什么坑,踩出了什么心得?欢迎在留言区分享——这个话题,比任何基准测试都更有参考价值。
飞书Aily是“飞书+AI”,钉钉悟空是“AI+企业流程”——企业级 OpenClaw 让两套公式更易落地
但问题不是"用哪个",而是"用了之后到底有没有用"。钱花了,活还得人搬。跨系统的数据导来导去,流程一长就出错,还没法追责。他真正想知道的只有一件事:这东西上了之后,公司的活到底能不能少干一点?企业级OpenClaw到底要怎么选择?
评产品最偷懒的方式,是列功能。最有效的方式,是还原它在真实工作里的处理过程。我们选了三个场景,都是企业里天天发生的事,看看钉钉悟空实际上是怎么跑的。任务描述: "帮我整理本周销售数据,生成周报,发到销售群。"飞书Aily的做法是调用工具:aily-doc, aily-im, aily-calendar, aily-base,收集销售群消息,飞书知识问答来收集。但如果你的销售数据分散在飞书以外的系统(比如独立CRM或ERP),它无法自动调取,需要你先手动导入或打通API。数据备齐之后,生成周报的质量不错,格式清晰,也能发到飞书群。但那个"先准备好数据"的步骤,目前还是要人来做。悟空接到这句话之后,不是弹出一个对话框问你"请提供数据源",而是直接开始干。它自动把这句话拆解成四步:采集数据→整合数据→生成报告→推送发送。然后一步一步执行,每一步做了什么,调用了哪个系统,全部实时显示在屏幕上,清清楚楚。跨系统的数据它自己去取,不需要你先导出一个Excel再粘贴进来。报告生成后,直接推送到指定的钉钉群。对比小结:如果数据全在飞书生态内,Aily表现流畅;数据一旦跨出飞书,就需要人工介入打通。悟空在跨系统数据调取上的自动化程度更高。任务描述: "给这周跟进中的20个客户,每人发一封个性化跟进邮件,附上方案PDF。"Aily在邮件内容生成上表现出色,给它客户背景信息,它能写出质量很高的个性化内容。但这里有一个前提:你需要先把客户信息整理好给它。它不会主动去钉钉或第三方CRM里调数据,信息准备这一步还在你这里。PDF附件的处理也需要手动操作,它不会自己去找文件然后挂上去。最终邮件发送,需要你复制到邮件客户端操作,或者额外配置邮件发送的连接。悟空先去调取钉钉里的客户跟进记录,把本周该联系的人都找出来。然后给每个人写邮件——不是同一封改个称呼,而是根据每个客户的跟进进度、项目情况,写真正有差异的内容。有一点值得专门说:它只能调取这位客户经理本人有权限看的客户数据。不该看的,它碰不到。权限体系是内建的,不是靠人工事后检查的。这20封邮件,几分钟内发完。客户经理全程没打开过邮箱。对比小结: Aily的内容生成能力很强,但"从哪里取数据→生成内容→附件→发送"这条链路,目前需要人工参与多个环节。悟空在链路打通上更完整,但前提是你的数据在钉钉生态内。任务描述: "整理一下各部门本月项目进度,找出延期风险,给我一份预警报告。"飞书Aily在处理飞书项目管理和飞书文档里的数据时,能提取进度信息、做一定程度的分析和汇总,生成的报告结构清晰。问题同样出在边界上——如果你的项目数据有一部分在飞书外面,就需要先手动整合进来。它不会主动触发钉钉式的提醒链路,生成报告之后,分发和通知还是需要你来操作。自动从多个数据源拉取信息,钉钉项目、OA审批记录、外部对接系统,一并汇集。然后用推理引擎对比计划时间线和实际进度,找出哪个项目在哪个环节出了问题,风险等级怎么定。报告生成之后,它还会在钉钉里直接触发提醒,通知到相关负责人,并且给出行动建议。所有操作都有审计日志。事后想查AI访问了哪些数据,调了哪些系统,全部有记录可查。对比小结: 两者在"分析和生成报告"这个核心动作上差距不大。区别在于前端的数据汇集和后端的执行分发,悟空的自动化链路更长,Aily在纯飞书生态内的体验更顺滑。
跑完这三个测试,我们看到的不是一个明显的好坏,而是两种截然不同的产品思路。悟空的路线: 把整个钉钉系统做了底层CLI化改造,IM、文档、审批、日程上万条命令行指令对AI开放,AI直接通过命令调用系统能力,而不是"模拟人点击"。这套架构的好处是执行链路长、跨系统打通能力强;代价是它的边界也很清楚——钉钉生态以外的东西,需要额外对接。Aily的路线: 在飞书现有产品上构建AI能力层,强项是内容生成质量高、上手门槛低、在飞书生态内体验顺滑。代价是"飞书能做到的,Aily才能做到",跨生态执行目前仍需人工介入。如果你的协作数据已经深度沉淀在飞书里,团队接受度高,需要的是AI帮你把现有工作流做得更顺,Aily是个合理的选择,它不会让你失望,但也不要期待它帮你跑完整条链路。如果你需要AI真正跨系统执行、打通多个业务平台、在企业安全体系内自主干活,且愿意接受钉钉生态的前提,悟空目前展示的天花板更高——OPT"一人团队"方案里那些汽修门店、跨境电商的案例,靠的就是这套执行闭环。
两款产品都在快速迭代,今天的差距不代表半年后。但底层架构的方向选定了,短期内不会大改。真正值得问自己的问题只有一个:你接入AI,是为了让现有工作方式跑得快一点,还是为了重新定义工作方式本身?
Hermes Agent 架构拆解:三层骨架 + 六大子系统,为什么说它更像“Agent 操作系统”?
原来我们开发智能体,我陆续使用了不少 Agent 框架,AutoGPT、LangGraph、AutoGen……翻来翻去,总觉得差点意思。要么是把 LLM 包一层就叫 Agent,要么是把 Prompt 写复杂点就叫"规划",落地的时候一跑就露馅。直到翻到 Hermes Agent,才觉得这东西认真在做工程。Hermes 是 Nous Research 开源的 Agent 框架,GitHub 上 Stars 破了 8 万,多家大厂内部也在研究这个架构。它的核心理念只有一句话:与你共同成长。不是"帮你完成任务",是"和你一起变强"。这篇文章,我想把 Hermes 的架构从头拆一遍。不是翻译文档,是把我觉得真正值得学的地方说清楚。
为什么大多数 Agent 用着用着就觉得"不够用"?原因其实很简单——它们本质上是无状态的。每次对话重新开始,之前聊过什么、用过哪些工具、犯过什么错,一概不记得。就像你每天上班,同事都忘了你昨天说过的话,还得重新介绍一遍自己。第一,没有积累。 你教它怎么操作你们公司的内部系统,下次还得再教一遍。每次对话都在消耗同样的 Token,做同样的事情。第二,没有自检。 它不知道自己哪次做对了、哪次做错了,更不会主动改进。出了问题只能靠你发现,靠你纠正。第三,上下文管理混乱。 一旦对话稍微长一点,它开始"忘事"。要么把所有历史塞进 Context 导致 Token 爆炸,要么截断历史导致前后矛盾。这三个问题,Hermes 的设计目标就是一一解决它们。
我习惯把 Hermes 的架构理解为三层结构,每一层对应一种能力。负责"看懂世界"。用户发来的消息、当前对话的上下文、外部 API 返回的数据,都在这一层被消化。它做的事情是:这个输入是什么意思?用户真正想要的是什么?当前状态是什么?负责"想清楚该做什么"。任务拆解在这里发生,规划在这里生成,记忆在这里被调取。这层是整个 Agent 的"大脑",也是 Hermes 最花心思的地方。负责"真正把事做完"。调用工具、操作文件、访问 API、执行代码——这些都在执行层完成。大多数 Agent 框架把这层做得很薄,但 Hermes 在这里加了相当重的工程保障。三层之上,Hermes 定义了六个子系统,把整个运行链路串起来:- 用户消息触发器:接收输入,同时触发技能创建流程和轮次计数。
- 周期性 Nudge(提示机制):这是 Hermes 的一个核心创新——每执行到一定轮次,系统会自动产生一个"该复盘了"的内部信号,把学习从用户要主动触发变成 Agent 自己的本能。
- 后台复盘(Background Review):独立的守护进程,异步运行,专门做总结和分析,完全不阻塞主对话流程。
- 双文件存储:本地文件加云端备份,确保记忆能真正持久化。
- 全息记忆(Holographic Memory):长期的、结构化的知识存储。
- 记忆管理器(Memory Manager):短期记忆的调度中枢。
这六个系统的分工,是 Hermes 和大多数 Agent 框架最大的不同——它是一套完整的、有分工的操作系统,而不是一个被 Prompt 驱动的脚本。
如果说架构是骨骼,记忆系统就是 Hermes 的血液。很多 Agent 框架说自己有"记忆",实际上不过是把聊天历史扔进 Context,或者用个向量数据库做召回。这种方式有个致命问题:随着使用时间增长,它反而会越来越乱。什么都往里存,什么都要检索,结果信噪比越来越低。Hermes 的记忆系统是分层的,每一层解决不同的问题。- MEMORY.md:存储系统对自身的认知,比如它掌握了哪些技能、有哪些操作规范。
- USER.md:存储用户画像,比如用户的习惯、偏好、常用的工作流。
每次对话启动时,这两个文件会作为"冻结快照"注入到 Context 里。容量被严格限制在约 3575 字符——不是技术限制,是主动控制。这层的逻辑是:把最重要的东西固定住,保证每次对话都有一个稳定的"底座"。第二层:会话归档与检索(Session Archive)历史对话被存进 SQLite,并启用了 FTS5 全文检索。当前对话需要引用历史信息时(比如"上周我们讨论过的那个方案"),系统按需检索,用 LLM 做摘要,把精炼后的内容注入上下文。这个设计的精妙之处在于:不是把历史对话全部召回,而是只取你现在需要的那一部分,并且以摘要形式注入,而不是原文复现。Token 消耗大幅降低,同时信息密度提高了。这是程序性记忆,记录的是"怎么做",而不是"发生了什么"。当一次任务复杂度超过一定阈值(比如工具调用超过 5 次),系统会自动把这次任务的执行过程提炼成一个 Skill 文档,遵循 agentskills.io 的标准格式,保存为 Markdown 文件。下次遇到类似任务,Agent 可以直接调用这个 Skill,而不是重新摸索。随着使用积累,这些 Skill 还会通过"补丁"方式迭代更新——用得越多,越精准。这是扩展接口,支持接入 Honcho、Mem0 等外部服务,做更深度的用户建模。对于需要长期追踪用户偏好、行为模式的场景,这一层提供了扩展空间。四层加起来,Hermes 的记忆系统是有梯度的:高频核心信息放顶层,历史数据按需检索,技能经验结构化沉淀,深度建模留给专业工具。不是什么都往一个地方塞,而是各司其职。
学会了怎么记忆,接下来说 Hermes 怎么"变聪明"。Hermes 的技能系统形成了一个完整的闭合回路:每执行 15 次工具调用,系统会自动做一次自检,评估这段时间的操作是否达到预期效果。如果有值得提炼的经验,就生成或更新对应的 Skill 文档。如果之前的 Skill 有不准确的地方,会以"补丁"形式修正,而不是覆盖重写。这个设计避免了两个常见的坑:一是"学了就忘",每次任务的经验都能沉淀下来;二是"一学定终身",Skill 会持续迭代,不会因为早期经验不准确就永远跑偏。随着使用时间增长,Skill 会越来越多,如果每次都全部加载,Token 消耗会指数级增长。Hermes 的解法是渐进式披露:默认只加载 Skill 的摘要版本,只有在真正需要执行某个 Skill 的时候,才加载完整的步骤。这是一个很实用的工程细节,真正在生产环境里跑过 Agent 的人会懂这个设计有多重要。很多 Agent 的"规划"其实是假的——把任务描述扔给模型,让它生成一个步骤列表,然后按顺序执行。这种方式在任务稍微复杂一点、中途出现意外的情况下,成功率非常低。Hermes 的 Planner 支持 Plan → Execute → Replan 的动态循环。不是一次性输出计划就完事,而是执行过程中持续观察结果,一旦发现偏差就重新规划。这才像一个真正"做项目"的人:不是只会写计划,而是会根据实际情况调整计划。
架构设计好不代表真的能用。我觉得 Hermes 真正有价值的,是它在工程层面的认真程度。Background Review 是一个独立的进程,通过 Fork 机制运行,和主对话流程完全解耦。这意味着:你在和 Agent 对话的时候,它在后台悄悄做总结、提炼技能——但你不会感受到任何延迟。这不是小细节,这是一个系统能不能真正好用的关键区别。很多 Agent 的"反思"和"总结"是同步执行的,每次都会有一段等待时间,用体验极差。一套核心代码,通过 Gateway 进程接入 Telegram、Discord、飞书、钉钉等 15 个以上的平台。对于企业落地来说,这个设计价值很大。员工用什么 IM 工具,Agent 就接在哪里,不需要为每个平台单独维护一套逻辑。支持 Local、Docker、SSH、Modal 等多种后端环境,从 5 美元一个月的 VPS 到 GPU 集群都能跑。这种设计让 Hermes 的使用门槛很低,同时也支持规模化扩展。自进化这件事最让人担心的是失控:Agent 自己改自己,边界在哪?Hermes 设计了五层防线:用户授权、操作审批、容器隔离、凭证过滤、注入扫描。每一层针对不同的风险点。可观测性也是显式设计的——任务执行路径可以被监控和审计,出了问题能追溯。
Hermes 最大的优势在长期使用场景——需要持续积累经验、需要跨会话保持记忆、需要随着使用变得越来越好用的场景。它的局限也是真实的:复杂任务的执行路径对用户来说仍然是黑盒,在需要完全可解释、每步都要审计的企业合规场景下,目前还需要做不少定制。
第一,从单一任务切入,不要一上来做大而全的 Agent。Hermes 的架构支持"从小做大"。先把一个具体的、高频的任务场景跑通,让 Skill 系统积累起来,再逐步扩展。想一下子覆盖所有场景,只会让调试变成噩梦。能帮你真正把事做完,比能和你聊得天花乱坠重要得多。工具调用稳不稳、任务中断能不能恢复、多步骤执行的成功率高不高——这些才是一个 Agent 值不值得用的核心指标。把你们公司高频的操作流程整理成 Skill 格式,这件事本身就有价值——它会逼着你把之前模糊的、全靠人脑记忆的操作规范显式化。这些 Skill 沉淀下来,是真正可复用、可迭代的资产。
我觉得 Hermes 代表的不只是一个具体框架,而是一种对 Agent 的不同理解:大模型是大脑,但光有大脑不够。真正能用的 Agent,需要的是一套完整的神经系统——能感知、能规划、能记忆、能执行、能学习、能自我修正。AI Agent 的竞争,归根结底是工程能力的竞争。状态怎么管、记忆怎么分层、异步怎么处理、失败怎么恢复——这些"枯燥"的工程问题,才是决定上限的地方。你现在用的 Agent,更像一个"会聊天的工具",还是一个"能干活的系统"?
90%的人都搞错了,Harness Engineering根本就不是Hermes Agent!
AI 圈起名字的人,大概都有一颗想当“绕口令大师”的心。如果你最近在追踪 AI Agent 的最前沿进展,那你大概率会被 Harness 和 Hermes 这两个词搞得晕头转向。这种感觉,就像在满是“张三、张三丰、张三疯”的聚会上找人,稍微一走神就会认错。最近爆火的两个 AI 概念,名字像、功能也沾边,但它们真的不是一回事。一文讲清 Harness Engineering 和 Hermes Agent 的前世今生。之所以想聊这个,是因为我发现这种“命名焦虑”已经成了行业的普遍现象:大家都在谈论它们,却很少有人能准确说出它们的边界。而分清它们,不只是为了聊天时不露怯,更是为了看懂 2026年 Agent 工程落地的真正底层逻辑。
前段时间和朋友聊天,我信心满满地说:"你知道 Hermes Agent 吗?就是那个做 DevOps 的 Harness 嘛,他们出了个 Agent 产品……"朋友沉默了两秒,然后说:"你说的是 Harness.io?还是 Agent Harness?还是 Hermes Agent?这是三个不同的东西啊。"说实话,我不觉得这个误会有多丢人。因为这几个词不仅发音相近,连它们在 AI 圈里的语境也高度重叠——都跟让 AI Agent "变得更强"有关。稍微没追紧一点,就会把它们混在一起。今天我就把这些概念彻底理清楚,顺便也帮自己正式道个歉:对不起,Harness,对不起,Hermes,你们不是同一个东西。先给你一个最省脑子的结论:Harness 是一种工程方法论,Hermes 是一个具体的 AI 产品。 它们的关系,更像是"操作系统"和"一台安装了操作系统的电脑"。
二、先搞清楚:AI 圈的"Harness"到底有几个"Harness"这个词,在当下的 AI 语境里,至少对应三个不同的东西:这是一家做企业级 DevOps 的公司,产品线覆盖 CI/CD 流水线、自动化测试、应用安全、云成本优化……是真正做"软件交付"的。他们最近也在大力推 AI,提出了一个很有意思的观点,叫"AI 速度悖论"——团队用 AI 写代码越来越快了,但部署、安全、测试这些下游环节反而成了新的瓶颈,整体效率并没有线性提升。第二个:Agent Harness(一种工程思想)这才是本文要讲的重点。"Agent Harness"是 AI 领域一个正在被广泛讨论的工程架构概念,和 Harness.io 这家公司没有直接关系,只是名字撞上了。第三个:Claude Agent SDK 被 Anthropic 称为"general-purpose agent harness"连 Anthropic 自己也在用"harness"这个词描述他们的 Agent 基础设施。这让整个命名体系更乱了一层。所以你明白了——光是"Harness"这一个词,就够让人头大了,更别说再加一个发音相近的"Hermes"。本文接下来聚焦在第二个含义:Agent Harness,作为一种工程思想。
三、Harness Engineering:给 AI 这匹野马,套上一副马具Harness,英文原意是"马具"——马鞍、缰绳、挽具,那一整套套在马身上的装置。注意,马具不是用来代替马思考的,也不是用来替马跑路的。它的作用,是引导马的力量,约束马的方向,让它能安全、稳定地做该做的事——拉车,赛跑,或者只是不把骑手摔下来。AI Agent 里的 Harness,逻辑完全一样。大模型是那匹马,聪明、强大、有时候难以驾驭。它可以思考,可以推理,可以输出各种内容。但单靠它自己,它干不了什么实际的活——它没有手,没有眼睛,没有记忆,甚至不知道现在几点。Harness Engineering,就是为这匹"野马"造出那套马具。你有没有想过,为什么同一个 Claude 模型,在普通对话框里就是一个聊天助手,在 Claude Code 里却能帮你写代码、跑测试、改 bug?变化的,是包裹它的那层 Harness。Claude Code 的 Harness 给模型装上了文件系统访问、终端执行能力、跨会话的状态保持、验证与回滚机制……同一个"大脑",有了完全不同的"身体"。这就是 Harness 的本质:它是模型和真实世界之间的那层工程胶水。- 文件系统与 Git:让 Agent 的工作能保存下来,能回溯,能被审计。没有这个,Agent 每次执行完就是一张白纸。
- 沙箱环境:给 Agent 一个安全的试验场。它可以在里面执行代码、装卸依赖、甚至搞破坏——但影响不会外溢。
- 上下文管理:这是最容易被忽视、又最关键的一块。对话越来越长,模型会开始"忘事"甚至"犯迷糊"。好的 Harness 会主动压缩、摘要、筛选信息,保证模型始终"脑子清醒"。
- 工具调用与权限控制:决定 Agent 能用什么工具、能访问什么资源、能做到哪一步。这是"安全边界"所在。
- 跨会话记忆:让 Agent 不是每次都从零开始。它能记住上次做了什么,哪个方法有效,你的偏好是什么。
Manus 当年上线时风头无两,但很少有人知道,他们的 Harness 在达到生产就绪状态之前,经历了整整六个月、五次完整的架构重写。LangChain 的团队也花了超过一年时间,迭代了四套不同的执行引擎架构。有人说,2025 年是 Agent 的元年,2026 年才是 Harness 的元年——行业用了整整一年,才从"Demo 跑起来了真好玩",撞到了"为什么这玩意儿在生产环境这么脆"的那堵墙。
四、Hermes Agent:那匹已经套好马具、开箱即用的马Hermes Agent 是 Nous Research 做的。这个名字可能不如 OpenAI、Anthropic响,但在开源模型圈里相当有份量——他们出品的 Hermes 模型系列,是目前公认工具调用能力最强的开源模型家族之一。Hermes(赫尔墨斯)是希腊神话里的信使神,象征传递与沟通。这个名字选得很有意思——它的使命,就是在你和 AI 之间,在任务和执行之间,搭起那座桥。如果说 Harness Engineering 是一套造马具的方法论,那 Hermes Agent 就是一匹已经套好马具、调教完毕、开箱即用的马。你不需要自己去研究怎么造马鞍,怎么接缰绳,怎么训练马不乱跑。装好就能骑。它内建了:文件系统、沙箱执行环境、记忆管理、子 Agent 调度……这些 Harness 的核心组件,全都已经整合好了。这是 Hermes Agent 和大多数 Agent 框架最根本的区别。普通的 Agent,你今天用完,明天打开,它对昨天发生的事一无所知。每次都从零开始。Hermes 不一样。它有一套精心设计的四层记忆系统:第一层,常驻记忆。有两个文件,MEMORY.md 和 USER.md,专门存那些每次对话都必须知道的核心上下文。这两个文件加起来,字符上限只有 3575 个。你可能觉得这很少,但这是故意设计的。上限太大,人会偷懒,把什么都往里面塞,最后变成一锅乱粥。强迫你精简,反而让信息更有价值。第二层,会话归档。每一次对话结束后,内容都会写入 SQLite 数据库,支持全文检索。等 Hermes 下次需要某段历史时,它会主动去查,然后用 LLM 摘要提炼出精华,再放进当前上下文——不是无脑堆砌,是按需取用。第三层,技能记忆。这是最让我感兴趣的部分。Hermes 在完成一个复杂任务之后,会自动复盘:这次我用了什么方法?这个方法有效吗?如果有效,它会把这个方法提炼成一个"技能文件",存起来,下次遇到类似的任务直接调用。而且这个技能文件不是一次性的。后续用到的时候,如果发现更好的方法,它会直接给旧技能"打补丁"——只改有问题的部分,而不是把整个文件重写。更安全,也更省 token。第四层,用户建模。Hermes 会持续建立对你这个用户的理解——你的工作习惯、偏好、沟通风格。用的时间越长,它越懂你。Hermes Agent 完全开源,MIT 协议,没有任何商业限制。你可以把它接到 Telegram、Discord、Slack、WhatsApp、飞书、微信……15 个以上的平台,一个 Gateway 进程全搞定。出门用手机聊,到家用电脑命令行,对话上下文完全连续。模型方面,它支持接入任意 OpenAI 兼容接口,包括本地部署的 Ollama 和 vLLM。不想花 API 费用?拿本地模型跑,完全可以。它的 GitHub 活跃度极高,从今年 2 月底发布第一个版本到现在,几乎每周都有重大更新。这种迭代速度,在开源项目里算是少见的。
两者不是竞争关系,是包含关系:Hermes 是 Harness 思想的一个具体实现,Harness 是 Hermes 能做到那些事情的底层原因。
我最近越来越觉得,AI 行业正在经历一次很有意思的认知迭代。早期大家关心的是:"这个模型够不够聪明?参数有多少?benchmark 多少分?"然后是:"这个 Agent 能干什么?Demo 多厉害?"现在越来越多人开始问:"这个 Agent 在生产环境里靠不靠谱?成本可不可控?出了问题能不能定位?"这个转变,就是 Harness Engineering 这个概念被越来越频繁提及的背后原因。模型只是起点,工程才是终点。Harness 是"道",是构建可靠 AI Agent 的通用法则;Hermes 是"器",是这个法则下跑出来的一个很有意思的实践。就像你不会把"操作系统"和"MacBook"当成同一个东西一样。
你现在分清 Harness 和 Hermes 了吗?或者你还踩过哪些 AI 概念的命名坑?欢迎留言。
Harness、Hermes、OpenClaw、Claude Code、MCP、Skill、Agent…到底啥关系?大白话一次全搞懂
有时候挺怀念两年前的。那时候 AI 圈就一个主角:ChatGPT。现在呢?每天早起一睁眼,感觉自己像个被时代追债的。Harness、Hermes、MCP、Agent……这些词像雨后春笋一样冒出来,你要是没听过,甚至都不好意思在朋友圈里点赞。但我发现一个挺逗的事儿:很多人能熟练拼写这些单词,却讲不清它们到底干嘛用的。为了不让大家继续"装模作样"地懂下去,我花了点时间,把这一大堆零散的拼图拼在了一起。相信我,看完这篇,再听到这些词,你心里就有底了。
LLM(Large Language Model,大语言模型)就是整个 AI 故事的发动机。你可以把它想象成一个"超级大脑"——它读过互联网上几乎所有的文字,然后学会了怎么用语言回答问题、写代码、做分析。GPT-5、Claude、Gemini,这些都是 LLM。它的本质只有一件事:给定一段文字(输入),预测下一段文字(输出)。听起来很简单,但"预测文字"这件事做到极致,就能回答你的问题、帮你改代码、甚至陪你聊天解闷。
LLM 不像人一样逐字阅读,它把文字切成一小块一小块——这叫 Token。"我今天很开心"这句话,可能会被切成"我"、"今天"、"很"、"开心"四个 Token。英文里 "hello" 是 1 个 Token,"understanding" 可能是 2 个。- 它决定了费用。调用 API 是按 Token 计费的,输入多少、输出多少,都算钱。
- 它决定了"记忆上限"。每个 LLM 都有 Context Window(上下文窗口),本质上就是"最多能处理多少个 Token"。超了就忘,不超就记得。
一个实际感受:GPT-4o 的上下文窗口大约是 128K Token,Claude 3.5 是 200K,大概能塞进去一本中等厚度的小说。
三、Context(上下文):AI 的"短期记忆"因为每次你发送消息,系统都会把整段对话历史一起打包发给 LLM。这个"打包发过去的完整对话",就叫 Context(上下文)。AI 没有真正的记忆,它只是每次都"读了一遍所有聊天记录"然后再回复你。这就是为什么聊天窗口有时候会失忆——对话太长,超过了 Context Window,早期的内容就被截掉了。
但 Prompt 的讲究很多。同样是让 AI 写一篇文章:- 好的 Prompt:「你是一名写过 10 年科技评论的编辑,面向 25-35 岁的互联网从业者,帮我写一篇关于 AI Agent 的科普文章,口吻接地气,不超过 1500 字」
差距就像跟一个聪明人说"你去帮我办事"和"你去银行,帮我取 2 万现金,带好这个存折"——越具体,结果越准。System Prompt 是一种特殊的 Prompt,它在对话开始前就被设置好,用来告诉 AI "你是谁、你的规则是什么"。很多 AI 产品的"人设",其实就靠这个设定的。
五、Agent:让 AI 从"回答问题"变成"做事"前面说的 LLM + Prompt + Context,组合在一起,AI 能干的事还只是"聊天"——你问它答。Agent(智能体)是更进一步的概念:让 AI 有能力自己规划步骤、调用工具、完成任务。举个例子。你问 ChatGPT:"帮我查一下今天上海的天气"——它没有联网功能的话,只能说"我不知道"。但如果你给它配上一个"搜索工具",让它能自己去调用搜索引擎,那它就变成了一个 Agent:
Agent = LLM(大脑)+ Tools(工具)+ 自主规划能力
Tool 就是 AI 能调用的功能模块,比如:搜索网页、读取文件、执行代码、发送邮件、操作数据库。你可以把 Agent 想象成一个新来的员工,LLM 是他的大脑,Tool 是他桌上的各种工具:电话、电脑、计算器……
七、Skill:比 Tool 更"组装好"的能力包Tool 是单个工具,而 Skill 是把几个工具打包成一个"完整技能"。比如"写周报"这件事,可能需要:读取本周任务清单、汇总完成情况、按固定格式输出、发送到指定邮箱。这四步如果每次都要手动定义,太繁琐。把它们打包成一个叫"写周报"的 Skill,以后直接调用就行。Tool 是零件,Skill 是组装好的功能模块。在 Hermes Agent、OpenClaw 这类产品里,Skill 还有更进一步的含义——它可以是 Agent 在完成一项复杂任务之后,自己总结出来、存下来、下次直接复用的经验文档。等一下细说。
Tool 的问题在于:不同的 AI 平台,接入工具的方式各不相同。你今天给 Claude 加了个搜索工具,明天换成 GPT,又要重新接一遍,格式完全不一样。MCP(Model Context Protocol,模型上下文协议)就是来解决这个问题的。它是 Anthropic 提出的一个开放协议——相当于给 AI 接外部工具定了一个统一标准。就像 USB 接口的出现,让所有设备不用再为"接口不兼容"发愁一样,MCP 让 AI 接任何工具都能用同一套规范。工具开发者只需要按 MCP 规范封装一次,所有支持 MCP 的 AI 都能用。Claude、Cursor、各类 IDE 插件,现在都在接入 MCP。到了 2025 年,MCP 已经成为 AI 接工具事实上的通用标准,Hermes Agent、OpenClaw 这类主流 Agent 框架,也都把 MCP 支持列为标配。
九、Harness:套在 LLM 外面那层"缰绳"这个词是 2025-2026 年间悄悄火起来的,但很多人没听懂它在讲什么。Harness 的本义就是马具、套具——套在马身上用来驾驭它的那套东西。这个比喻在 AI 圈被直接拿来用,非常形象:LLM 是一匹劲头十足的马,有蛮力,但没有方向感,也不知道"停"是什么意思。Harness 就是套上去的缰绳、辔头和控制系统。具体来说,Agent Harness 是包裹在 LLM 外面的那一整套执行基础设施——它决定了:2025 年年底,HashiCorp 联合创始人 Mitchell Hashimoto 发了一篇文章,把这个概念叫做"Harness Engineering"(套具工程):每次 Agent 出错,就把修复措施永久写进它的执行环境里。随后 Anthropic 和 OpenAI 相继发文跟进,这个词就这么传开了。一个很反直觉的例子:Vercel 在构建自家 AI 编程 Agent 时,把 Agent 可用的工具删掉了 80%,结果任务完成质量反而提升了。工具越多,Agent 越容易选错、越容易兜圈子。Harness 的工作之一,就是替 Agent 做减法。另一个例子更有意思:有个团队发现 Agent 在处理长任务时会"偷懒"——不是因为能力不够,而是它察觉到 Context 窗口快满了,开始抢着收尾。解决方案不是换模型,而是改 Harness:给它配一个假的"充裕感",让它以为窗口还大得很。问题消失了,模型一行代码没动。总结起来就一句话:模型决定 Agent 能有多聪明,Harness 决定 Agent 能不能真正可靠地干活。
十、多智能体(Multi-Agent):让一群 AI 协作干大事单个 Agent 能做的事有上限——Context 有限、能力有限、速度有限。多智能体(Multi-Agent)是让多个 Agent 分工协作,像一个团队一样完成复杂任务。每个 Agent 专注自己的一块,最后汇总。效率和质量都远超单个 Agent 硬撑。多智能体的关键挑战是协调:谁先做、谁传给谁、出错了怎么办。MCP 在这里也有用武之地,它能让不同 Agent 之间共享状态和工具。
十一、Claude Code:专门干编程活的 AgentClaude Code 是 Anthropic 推出的编程专用 Agent。它不是一个简单的"代码补全工具",而是一个真正能在你的项目里"干活"的 Agent:理解你的整个代码库、自己写代码修 Bug、执行命令运行测试、遇到问题自己调试。你可以把它理解为:一个真正能在你电脑上干编程活的 AI 程序员,而不只是在聊天框里给你建议。它的底层是 Claude,配了访问文件系统、执行终端命令等各种 Tool,是一个完整的 Coding Agent。值得一提的是,Claude Code 本身就是一个精心设计了 Harness 的产品——同样的 Claude 模型,套上专为编程任务设计的执行环境,行为就跟普通聊天完全不一样。
十二、OpenClaw:2025 年底横空出世的个人 AI 助手如果你最近几个月一直在刷技术圈,不可能没听说过 OpenClaw。它的爆红速度,被很多人比作当年 ChatGPT 第一次亮相时的那种冲击感。OpenClaw 是一个开源的个人 AI Agent,由奥地利开发者 Peter Steinberger 在 2025 年 11 月发布。它的核心设计思路很直接:把 LLM 的能力,直接接进你本地电脑和你常用的通讯工具里。你在 WhatsApp、Telegram、微信发一条消息,OpenClaw 就在你的电脑或服务器上真正地"干活"——读文件、跑代码、发邮件、搜网页、操作浏览器……它不是在聊天框里给你建议,而是真的替你执行。有个用户分享说,他让 OpenClaw 处理收件箱,两天内自动整理、分类、草拟回复了 4000 多封未读邮件。这种事以前要么靠人肉、要么靠一堆繁琐的自动化脚本,现在一句话搞定。关于这个项目名字的来历,还有个小插曲:它最早叫 Clawdbot,因为名字太像 Anthropic 的 Claude,被提出商标投诉,改名 Moltbot,但作者觉得这名字"念起来太拗口",三天后又改成了 OpenClaw——名字里那只龙虾的意象,也就这么传开了。OpenClaw 爆红的速度在开源历史上也属罕见——约 60 天内收获了 GitHub 24 万颗 Star、近 5 万个 Fork,甚至引发了中国开发者社区的大规模移植:接入了 DeepSeek、适配了微信。Tencent 和 Z.ai 都宣布推出基于 OpenClaw 的服务。OpenClaw 的核心架构不复杂,但设计得很聪明:一个长期运行在本地的后台进程(Gateway)统一接收你各个 app 的消息,交给 LLM 决定调用哪些 Tool,Tool 在你的机器上真正执行,结果回传到你的消息 app。也支持 MCP,可以扩展接入各种第三方服务。Skill 机制类似 Hermes,社区里已经有上百个现成的 Skill 可以直接装上用。当然,OpenClaw 也有隐患。因为它要访问你的文件、邮件、命令行,安全配置不当风险不小。安全研究机构发现过多个漏洞,也有研究人员扫出数万个配置裸奔在公网的 OpenClaw 实例。这工具很强,但"如果你搞不定命令行,这个项目对你来说太危险了"——这句话是 OpenClaw 的一个核心维护者自己说的。
十三、Hermes Agent:能自我进化的开源 AgentHermes Agent 是 Nous Research 推出的开源 AI Agent,2025 年初正式发布。Nous Research 这个名字在模型圈有点分量——他们是 Hermes 系列开源模型的幕后团队,也是最早把"工具调用能力"这件事做得比较好的一批人。而 Hermes Agent,是他们把模型研究积累转化成产品的一次落地。和 OpenClaw 的"接管你的电脑"路线不同,Hermes Agent 走的是另一个方向:它活在你的服务器上,跨 session 记住一切,并且能从每次使用中主动学习、越用越聪明。跨 session 的持久记忆。 普通聊天 AI,关了窗口就忘了。Hermes Agent 不一样——它把每次对话都存入 SQLite,支持全文搜索,几周前你们讨论过的项目,它还能翻出来接着干。它还维护两个小文件:一个记它了解到的你的工作环境和项目习惯(MEMORY.md),一个记你的偏好和沟通风格(USER.md)。每次新对话开始,这两个文件会自动注入到 System Prompt 里——等于它每次跟你说话,都带着"对你的了解"开场。自动生成 Skill,边用边涨本事。 这是 Hermes Agent 最有意思的设计。当它完成了一件比较复杂的任务(大概调用了 5 个以上的 Tool),它会自动把这次的解决思路整理成一个 Skill 文档,存下来。下次遇到类似问题,直接调用这个 Skill,不用从零推理。而且 Skill 在使用中还会持续迭代优化。换句话说,你用得越多,它就越会干活,而不是每次都要重新教它。随时随地触达。 它支持 Telegram、Discord、Slack、WhatsApp、Signal、邮件、命令行,从任何设备发消息就能用。你可以让它在一台云服务器上 24 小时运行,你出门在外用手机发条 Telegram,它在那台你从没 SSH 进去过的机器上自己把事办了。和 OpenClaw 比,Hermes Agent 更强调"自主学习和自我改进",OpenClaw 更强调"手动配置、精确控制"。两个思路各有侧重,取决于你更倾向于信任 Agent 自己摸索,还是自己掌控每一步。另外值得一提的是,Hermes Agent 还内置了一条迁移命令:如果你之前用过 OpenClaw,可以一键把配置、记忆、Skill 和 API 密钥全部导入 Hermes——也算是侧面印证了两个项目之间的竞争关系。
读到这里,这些词应该在你脑子里有具体形状了。让我用一个完整的比喻把它们串起来:Prompt 和 Context 是他每次上班前收到的工作简报;Tool 和 Skill 是他的工具箱和操作手册;Harness 是公司给他套上的工作规范,规定了他能做什么、不能碰什么、出错了怎么上报;OpenClaw 和 Hermes Agent,则是把这一切打包好、你可以直接装进自己电脑的成品。
这些概念单独看都不难,难的是它们互相嵌套、互相依赖,一旦没有整体感,看到新名词就发懵。LLM 是大脑 → Prompt + Context 是输入 → Tool/Skill 是手脚 → Harness 是控制系统 → Agent 是能干活的人 → 多智能体是团队 → MCP 是协作规范 → OpenClaw/Hermes Agent 是落地产品形态把这条链条刻进脑子里,以后不管再冒出什么新词,你都能找到它在哪个位置挂靠。OpenClaw 和 Hermes Agent 的爆红,某种程度上标志着"AI Agent 真的开始进入普通人的日常"——不再只是实验室里的概念,而是能装在手机里、接进微信的东西。
深度拆解 Hermes Agent 架构:从三层逻辑到 FTS5 全文检索,手把手教你微信接入实战!
AI Agent 降温了吗?并没有。但大家确实变聪明了,不再轻易为那些“只有演示视频好看”的框架买单。最近两年,我密集测试了多个 Agent 框架。说真的,大部分都让我感到沮丧——它们要么傲慢地想接管你的一切,要么笨拙到连个本地文件都读不明白。但我最近发现了一个异类:Hermes Agent。它没搞那些花哨的 UI,而是死磕了三个最痛的点:记忆、技能、以及真正丝滑的部署。它是 Nous Research 的亲儿子,目前 GitHub 9900+ Star。今天不聊虚的,直接带大家拆解一下,这个能让 AI 拥有“长久记忆”的框架到底凭什么这么火。
你今天告诉它你的工作流程,明天重新打开,它什么都不记得。你每次都要重新介绍自己,重新解释背景,重新纠正它的习惯。这种重复劳动积累下来,消耗的时间比你省下来的还多。Hermes 的核心思路是:Agent 应该越用越聪明,而不是每次都从零开始。持久记忆(Memory):Agent 会主动把重要信息写入 MEMORY.md,比如你的工作偏好、常用工具、项目背景。下次对话时自动加载。它还会维护一份 USER.md,逐渐建立对你这个人的理解模型。技能系统(Skills):每当 Agent 完成了一个复杂任务(调用了 5 个以上工具),它会把整个解决思路提炼成一个 SKILL.md 文件保存下来。下次遇到类似问题,直接调用这个技能,不用重新摸索。跨会话检索(FTS5 Search):所有历史对话都存在本地 SQLite 里,支持全文检索。Agent 可以翻出三个月前的对话,找到当时处理某个问题的具体思路。这三个机制组合在一起,就形成了一个闭环的自我改进系统——Agent 在用的过程中不断成长,而不是每次重置。
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
支持 Linux、macOS 和 WSL2。安装脚本会自动处理 Python、Node.js 和所有依赖,不需要你手动配置环境。source ~/.bashrc # 或 source ~/.zshrc
hermes # 启动
hermes setup # 运行完整的配置向导
hermes model # 选择模型和 provider
模型支持非常广:OpenRouter(200 多个模型)、OpenAI、Anthropic、Kimi/Moonshot、MiniMax,以及 Nous 自家的 Portal。用 /model 命令随时切换,不需要改代码。上面那行 curl 脚本适合大多数人,但如果你需要自定义安装路径、对依赖版本有要求,或者就是想把每一步摸清楚,手动装也完全没问题:git clone https://github.com/nousresearch/hermes-agent.git
cd hermes-agent
第二步,创建虚拟环境(强烈建议,别污染全局环境):python -m venv venv
source venv/bin/activate # Linux / macOS
# Windows 用户:
.\venv\Scripts\activate
pip install -r requirements.txt
这一步做的是把当前源码目录"挂载"进 Python 环境,让你可以直接跑 hermes 命令。跳过这步的话,后面会找不到入口。有一点要记住:下次再用的时候,需要先重新激活虚拟环境,再跑 hermes。忘了激活是新手最常遇到的"为什么突然不能用了"的原因。
理解 Hermes 的架构,有助于你更好地使用它。入口层负责接收你的消息,可以是终端、Telegram、Discord、Slack、WhatsApp,甚至邮件。这一层只负责传递消息,不处理逻辑。核心层是真正干活的地方,叫 AIAgent。每次对话,它会做这几件事:- 用 prompt_builder.py 把系统提示词组装好,包括你的记忆、当前技能列表、项目上下文
执行层有 47 个内置工具,分成 19 个工具集,包括终端操作(支持 6 种后端:本地、Docker、SSH、Daytona、Modal、Singularity)、网页搜索、文件操作、代码执行、浏览器自动化等等。你输入消息
→ HermesCLI.process_input()
→ AIAgent.run_conversation()
→ prompt_builder 组装提示词
→ 调用模型 API
→ 如果有工具调用 → 执行工具 → 继续循环
→ 最终回复 → 显示 → 保存到数据库
技能(Skill)本质上是一个 Markdown 文件,告诉 Agent"面对这类问题,用什么流程解决"。格式大概这样:---
name: deploy-to-k8s
description: 将 Python 服务部署到 Kubernetes 集群
version: 1.0.0
metadata:
hermes:
tags: [devops, kubernetes]
category: infrastructure
requires_toolsets: [terminal]
---
# 部署 Kubernetes 服务
## 触发条件
需要将代码变更部署到 k8s 集群时使用。
## 操作流程
1. 检查当前 k8s 上下文: `kubectl config current-context`
2. 构建并推送 Docker 镜像
3. 更新 deployment.yaml 中的镜像版本
4. 执行 `kubectl apply -f deployment.yaml`
5. 等待 rollout 完成: `kubectl rollout status deployment/<name>`
## 常见错误
- ImagePullBackOff: 检查 registry 凭证
- CrashLoopBackOff: 查看 pod 日志 `kubectl logs <pod>`
## 验证
`kubectl get pods` 所有 pod 状态为 Running
你可以手动写技能,也可以让 Agent 在工作过程中自动生成。技能文件存在 ~/.hermes/skills/ 里,每次对话会加载技能列表(只有名字和描述,很省 token),需要时才加载完整内容——这种"渐进式加载"的设计相当聪明。# 直接用斜杠命令调用
/deploy-to-k8s 把 auth-service 部署到 staging
# 或者直接聊
"帮我把这个服务部署上去"(Agent 会自动匹配到相关技能)
还有一个社区技能市场(Skills Hub),可以安装别人写好的技能:hermes skills search kubernetes # 搜索
hermes skills install openai/skills/k8s # 安装
hermes skills browse # 浏览全部
五、从 Telegram 控制运行在云服务器上的 Agent场景:我有一台 VPS,上面跑着一些定时任务和服务。以前需要 SSH 进去操作,现在我直接在 Telegram 上和 Agent 对话,它在服务器上执行操作,结果实时推送给我。
hermes gateway setup # 按向导配置 Telegram
hermes gateway start # 启动网关进程
- 在 ~/.hermes/config.yaml 里设置允许的用户:
gateway:
telegram:
allowed_users: [你的Telegram用户ID]
working_directory: /home/user/projects
- 现在在 Telegram 上发消息给 Bot,就像在终端里聊天一样
- "帮我看看 nginx 的错误日志,过去 1 小时的" → Agent 直接在服务器执行,返回结果
- "磁盘快满了吗" → 执行 df -h,告诉你结果
- "把 /var/log 下面 7 天前的日志压缩打包" → 直接执行,完了告诉你
危险命令(比如 rm -rf)默认会先让你确认,这个安全机制蛮重要的。
Hermes 支持接入微信个人号(不是公众号,不需要企业资质),原理是通过扫码登录你的微信账号,然后把收到的消息转给 Agent 处理,回复发回给对方。pip install aiohttp cryptography
pip install qrcode # 可选,让二维码直接显示在终端里
在平台选项里选 Weixin,向导会在终端显示一个二维码,用微信扫码确认,凭据自动保存到 ~/.hermes/weixin/accounts/。成功后会显示:微信连接成功,account_id=your-account-id
WEIXIN_ACCOUNT_ID=your-account-id
# 以下可选
WEIXIN_DM_POLICY=open # 私信策略
WEIXIN_ALLOWED_USERS=user_id_1,user_id_2 # 只允许特定用户触发 Agent
WEIXIN_GROUP_POLICY=disabled # 群消息是否响应
WEIXIN_ALLOWED_USERS 这个最好设一下,不然你微信里的所有人发消息都会触发 Agent,容易出乱子。之后在微信里给这个账号发消息,就会得到 Agent 的回复。用自己的小号登录,主号正常用,不互相干扰。
Hermes 有内置的定时任务调度器,任务用自然语言描述,结果推送到任意平台:# 进入对话后用斜杠命令创建
/cron add "每天早上 9 点检查服务器磁盘使用情况,超过 80% 发 Telegram 提醒"
/cron add "每周一早上生成上周的 git commit 统计报告,发到 Telegram"
/cron list # 查看所有任务
背后是个 JSON 格式的任务配置文件,存在 ~/.hermes/cron/jobs.json,也可以手动编辑。每个任务执行时会创建一个新的 Agent 实例,加载指定的技能,执行后把结果推送给你。
如果你有需要同时处理多个独立任务的场景,Hermes 支持启动子 Agent:帮我同时做三件事:
1. 分析 logs/access.log 里的异常请求
2. 检查 tests/ 目录下失败的测试用例
3. 统计本月的 git commit 数量
Agent 会启动三个独立的子实例并行执行,最后把结果汇总给你。这对需要大量 I/O 操作的任务提速明显。
hermes # 启动交互界面
hermes doctor # 诊断配置问题
hermes update # 更新到最新版本
hermes tools # 查看和配置工具
hermes config show # 显示当前配置
# 在对话中
/new # 开启新会话
/model # 切换模型
/compress # 压缩上下文(对话太长时用)
/usage # 查看 token 使用情况
/skills # 管理技能
/retry # 重试上一轮
上手曲线:第一次配置要花一点时间,尤其是配置 API key 和理解技能系统。但配置完之后日常使用很顺畅。本地存储:所有数据存在 ~/.hermes/ 里,包括记忆、技能、对话历史。这意味着数据在你自己手里,但多台机器之间同步需要自己处理。模型成本:功能越丰富,token 消耗越多。有 /compress 命令可以压缩上下文,但复杂任务的 API 费用仍然需要关注。Windows:原生不支持,需要 WSL2,要么就手动安装,安装python环境再按文中的步骤安装,个人认为对于智能体专业人员来讲非常友好,我本人就是这样使用的,因为这样不仅可以运行使用,还能研究代码和架构,主要是为了抄作业。
折腾了这么多 AI 工具,Hermes 给我最大的感触是:它终于不再把用户当成一次性的“提问机器”。大多数 Agent 是“用完即走”,而 Hermes 追求的是“养成”。随着你的技能(Skills)越攒越多,MEMORY.md 里的记录越来越厚,它会从一个冷冰冰的程序,逐渐变成一个最懂你工作习惯的“数字分身”。如果你也厌倦了每天对着 AI 重复同样的需求,厌倦了那些华而不实的 Demo,花半小时把 Hermes 跑起来。相信我,那种“它居然还记得我上周改过的 Bug”的瞬间,会让你觉得这点折腾完全值得。
两个行业、四个项目、一套方法论:我用 Vibe Coding三段式在垂直行业的工程化实践
电信 × 跨境电商 · 四个真实项目全链路拆解从需求定义到生产部署,一套方法论跑通两个行业。做完这四个项目之后,我对 Vibe Coding 的判断只有一句话:AI 工具是放大器,工程流程才是护城河。没有标准化的工程框架兜底,AI 生成再快也是在堆技术债。我见过太多团队拿到 Cursor 或 Claude Code 之后,第一周效率飙升,第三周陷入混乱——代码跑通了,但测不了、上不了线、接手的人看不懂。根本原因不是 AI 的问题,是工程流程没有跟上。这篇文章记录的四个项目,分属电信和跨境电商两个行业,需求复杂度和技术栈各不相同,但跑的是同一套三段式开发流程。每个项目后面附关键节点的 prompt 思路和可复用模板,看完可以直接上手。
一、核心方法论:三段式 Vibe Coding 流程在进入具体项目之前,先把方法论说清楚。我们内部把整个开发周期分成三个阶段,每个阶段的输入输出明确,不允许跳跃。这一阶段的核心任务是把「模糊的业务痛点」转换成「清晰的工程规格」。- 市场调研 + 竞品分析:不是走形式,是真正搞清楚这个场景里已经有什么、差什么、用户在哪里卡住
- 核心灵感提炼:从调研结论里挑一个最值得做的切入点,其他的砍掉
- 需求梳理:写 1 页 PRD,必须包含 DoD(Definition of Done)验收清单,每条需求可测试
- Figma 原型:不是高保真设计稿,是给研发看的交互逻辑图,用来对齐而不是审美
这一步很多团队觉得浪费时间,但它是后面所有 AI 辅助生成的锚点。没有这个锚点,你给 AI 的 prompt 就是一团模糊的需求,生成出来的代码方向会持续漂移。这一阶段的核心是「让 AI 干重复的活,把人的精力留给判断和架构」。- AI 前端生成:组件级的 React 代码交给 AI 生成,但组件拆分方式和状态管理架构由人来定
- DB 架构设计:数据库表结构必须人工设计,这是系统的骨架,不能让 AI 随机发挥
- API 定义:先写 OpenAPI 契约,再生成代码,而不是反过来。接口契约是前后端协作的合同
- Code Review:AI 生成的代码一样要过 Review,重点看边界处理、错误路径、安全漏洞
一个关键经验:Tool Schema 的设计质量直接决定 Agent 项目的上限。我们在电信运维那个项目上改了七八版 Schema,才真正跑通端到端的 Tool Calling 链路。这部分没有捷径,必须人工打磨。- 接口测试:覆盖正常路径和异常路径,尤其是 AI 模型返回异常格式时的降级处理
- CI 流水线:提交即触发,测试不过不允许合并,这是质量的最后一道闸
- 容器化:Dockerfile 必须在项目里,不接受「在我机器上能跑」的说法
每个项目跑完,沉淀三样东西:PRD 文档、OpenAPI 契约、Tool Schema 定义。这三个资产是下一个项目的起点,不是归档文件。
某省级电信运营商,网络运维团队每天处理来自不同网元的告警推送,量级在数千条以上。值班工程师的工作模式是:盯着监控屏幕,逐条人工研判,高度依赖个人经验,漏判一条可能引发故障升级。- 告警风暴:同一根因可以触发几百条告警,人工逐条看是在做无效劳动
- 经验依赖:老工程师能快速定位根因,新人要靠反复试错,知识无法结构化传承
- 响应延迟:人工研判 → 确认 → 操作的链路太长,P1 故障的 MTTR 居高不下
基于 Tool Calling 的故障诊断 Agent,核心链路:▶ 告警接入层:统一接收多源告警,去重聚合,把「告警风暴」收敛成「根因假设」▶ 诊断 Agent:基于 LangChain 构建,调用预定义运维工具(Tool)进行验证性操作▶ Tool 集合:设备状态查询、流量拉取、历史告警检索、配置核查,每个 Tool 对应一个运维 SOP▶ Human-in-the-loop:高危操作(重启、隔离、切换)生成工单草稿,人工确认后才执行▶ 闭环反馈:操作结果回写告警系统,更新根因判断,形成学习闭环最关键的设计决策是 Tool Schema 的粒度。粒度太粗,Agent 拿到的信息不够精确,诊断结论会漂移;粒度太细,Tool 数量爆炸,Agent 在工具选择上的消耗反而成为瓶颈。最终定在「每个 Tool 对应一个运维动作原子」的粒度,大概 12 个 Tool 覆盖了 80% 的告警场景。一个关键教训:Human-in-the-loop 不是妥协,是设计原则。在高风险操作链路上,自动执行的收益永远小于误操作的风险。让机器负责研判,让人负责决策,这个边界必须在架构层面写死,不能依赖运行时判断。把运维 SOP 文档喂给 Claude,用下面这个 prompt 提取结构化 Tool 定义:你是一个资深的电信网络运维架构师。
以下是我们的运维 SOP 文档:
[粘贴 SOP 内容]
请从 SOP 中提取可以被 AI Agent 调用的原子操作,每个操作定义为一个 Tool:
- name:工具名(snake_case)
- description:工具用途(这段描述是 Agent 选择工具的依据,必须精准)
- parameters:入参 JSON Schema
- returns:返回值结构说明
粒度原则:一个 Tool 只做一件事。
输出 Python 字典格式,可直接用于 LangChain Tool 定义。
Schema 确认后,一次性生成可运行的骨架代码:基于以下 Tool Schema:[粘贴上一步输出]
生成 LangChain Agent 骨架,要求:
1. 使用 Claude Sonnet 4.5 作为基础模型,create_tool_calling_agent + AgentExecutor
2. System prompt 注入角色:「你是电信网络运维专家,负责根因分析和故障处置建议」
3. 每个 Tool 实现先用 mock 函数占位(打印入参 + 返回固定测试数据)
4. 加入异常处理:Tool 调用失败时 Agent 如何降级
5. 包含 main() 测试入口,可直接运行
关键节点三:Human-in-the-loop 实现思路高危操作拦截的核心逻辑:Tool 被调用时不直接执行,而是写入数据库生成工单(状态 PENDING),同时通过 SSE 推送前端提示审批。Agent 用 asyncio.Event 等待审批信号,超时后自动降级为「仅建议,不执行」。这个模式可以复用到任何需要人工审批节点的场景。 | |
| |
| FastAPI + LangChain Agent |
| |
| Tool Schema 文档、运维 SOP 结构化模板、Human-in-the-loop 实现模板 |
TOOL_SCHEMA_TEMPLATE = {
"name": "query_device_status",
"description": "查询指定网元的当前运行状态,包括 CPU 利用率、内存使用率、
端口状态,用于判断设备是否存在资源瓶颈。
注意:只用于状态查询,不执行任何操作。",
"parameters": {
"type": "object",
"properties": {
"device_id": {"type": "string", "description": "网元设备 ID"},
"metrics": {
"type": "array",
"items": {"enum": ["cpu", "memory", "port", "all"]},
"description": "需要查询的指标类型,默认 all"
}
},
"required": ["device_id"]
}
}
Schema 迭代经验:每次 Agent 选错 Tool,回头看 description 是不是写得不够精准。最常见的问题是描述太模糊、参数粒度太粗、返回值没有语义标注。改 description 比改代码逻辑见效快得多。
电信客服的知识库管理是一个老大难问题。资费套餐文档动辄几百页,活动促销三天两头更新,扫描版的历史协议图片无法检索。坐席培训成本高,新人上岗后大量时间花在「查资料」和「问老人」上,而不是「解决用户问题」上。更深层的问题是:当坐席给用户一个说法,这个说法有没有原始文档依据?在投诉和纠纷场景下,「我记得是这样的」和「依据文件第 3 页第 2 条」是完全不同的权重。- 图片格式:扫描版资费单、活动海报,接入 OCR 模型提取文本
- 半结构化数据:Excel 格式的套餐对比表,转换后向量化
检索侧的设计重点是「溯源」。每一条检索结果必须携带原始文档的 source 元数据(文件名、页码、段落 ID),回答生成时强制引用溯源标注。流式响应把首 token 延迟从 3-5 秒降到 200ms 以内,坐席体验提升明显。OCR 质量直接影响知识库覆盖率。我们测试了几个主流模型,最终方案在扫描质量一般的图片上准确率也能稳定在 93% 以上。知识库的价值不在于 100% 精准,在于把原本完全不可检索的内容变成可检索。帮我生成一个电信客服知识库的文档 ETL 脚本:
输入:混合格式文件夹(PDF / Word / 图片 / Excel)
输出:文本块列表,每个块包含:
content、source(文件名)、page(页码)、chunk_id
处理规则:
- PDF / Word:按段落切块,500 token,overlap 50 token
- 图片:调用 Claude 视觉能力 OCR,提取后同样切块
- Excel:每个 sheet 转 Markdown 表格,整体作为一个块
要求:单个文件失败不影响整体流程,加进度条显示。
关键节点二:RAG 生成层 prompt(可直接复用)这个 prompt 模板是决定回答质量的核心,溯源机制完全靠这里控制:RAG_SYSTEM_PROMPT = """你是电信公司的客服助理,根据知识库内容回答用户问题。
严格规则:
1. 只能基于「参考资料」中的内容回答,不得自行推断或补充
2. 每一条关键信息后必须加溯源标注:【来源:{文件名} 第{页码}页】
3. 参考资料中没有相关信息时,明确回答:
「当前知识库中没有该问题的记录,建议转接人工坐席」
4. 回答结构:先给结论,再给依据,最后给溯源
参考资料:
{retrieved_docs}
"""
流式 SSE 的核心逻辑:检索 top 5 文档 → 组装 prompt(含历史对话最近 5 轮)→ 调用 Claude API(stream=True)→ token 实时推给前端。流结束后,完整回答 + 溯源信息存库。异常时返回降级文案「系统繁忙,请稍后重试」,不让用户看到裸错误。这套流式模板在项目四里直接复用了。踩坑记录:检索结果不加 source 元数据直接扔给模型,模型会「脑补」溯源,生成看起来有理有据实际上是幻觉的引用。务必在 prompt 里强制要求:没有来源的内容一律不引用。 | |
| Claude Sonnet 4.5 + OCR 专项模型 |
| |
| |
| |
| ETL 脚本模板、RAG Prompt 模板、流式 SSE 方案 |
跨境电商的选品决策是典型的「数据充分但洞察匮乏」问题。各平台 API 能拿到的数据量很大,但多数运营团队的分析工具还停在 Excel,数据分析师成为瓶颈资源,运营提一个临时分析需求,等两天才能拿到结果。选品决策的时间窗口很短。一个趋势品类从起量到红海可能只有 3-4 个月,等分析报告出来再决策往往已经错过了最佳时机。核心能力是 Text-to-SQL + ECharts 动态渲染,但把这两个做好并不简单。Text-to-SQL 的难点不在于 SQL 生成,在于业务语义映射。「爆款」在数据库里是什么字段的什么阈值?「近 30 天」是自然月还是滚动 30 天?「退货率高」的基准是行业均值还是绝对值?这些业务语义必须在 prompt 里显式定义,否则生成出来的 SQL 看起来能跑,但查的不是你想要的东西。我们的做法是把业务术语表和指标定义文档作为 system prompt 的一部分注入,同时在数据库层面加字段注释,Text-to-SQL 准确率从 60% 多提升到 90% 以上。ECharts 渲染这块,没有让 AI 直接生成 ECharts config,而是定义了一个中间层「图表描述 Schema」,AI 生成 Schema,前端代码把 Schema 转成 ECharts config。AI 输出格式可控,前端渲染逻辑稳定,两侧可以独立迭代。实测数据:引入 Text-to-SQL 后,运营团队临时分析需求响应时间从「平均 2 天」降到「平均 5 分钟」。这不是效率提升,这是决策模式的根本改变——运营可以随时验证假设,而不是提需求等结论。关键节点一:Text-to-SQL System Prompt(可直接复用)这是准确率从 60% 提到 90% 的核心,业务语义定义必须放在 prompt 里:TEXT_TO_SQL_SYSTEM = """你是跨境电商数据分析专家,把运营的自然语言问题转成 SQL 查询。
数据库表结构:
{schema_with_comments} # 关键:每个字段加中文业务注释
业务术语定义:
- 爆款:近 7 天日均销量 > 100 件
- 高退货率:退货率 > 行业均值 × 1.5
- 近 N 天:DATE('now', '-N days') 到 DATE('now'),不是自然月
生成规则:
1. 只生成 SELECT,不允许写入操作
2. NULL 值处理:销量 NULL 当作 0
3. 时间范围模糊时,默认「近 30 天」,并在回答开头说明假设
4. 输出格式:先输出 SQL,再用一句话解释这个查询在做什么
"""
不让 AI 直接生成 ECharts config,先生成这个中间 Schema,再由前端固定逻辑转换:CHART_SCHEMA = {
"chart_type": "bar|line|pie|scatter", # AI 选择
"title": "图表标题",
"x_axis": {"label": "X轴标签", "data": []},
"y_axis": {"label": "Y轴标签", "unit": "件/元/%"},
"series": [{"name": "系列名", "data": []}],
"highlight": "需要重点标注的数据点(可选)"
}
# 前端 ChartRenderer 组件接收这个 Schema,渲染对应 ECharts 图表
# 好处:AI 输出格式稳定,前端渲染逻辑不受 AI 输出波动影响
关键节点三:数据库字段注释是 Text-to-SQL 的隐形基础设施schema 设计时别省这一步,字段注释直接注入 prompt:CREATE TABLE products (
asin TEXT PRIMARY KEY, -- 亚马逊商品唯一标识符
category TEXT, -- 一级类目,如:家居、电子、服装
price REAL, -- 当前售价(美元),NULL 表示已下架
daily_sales_7d REAL, -- 近 7 天日均销量(件),用于判断是否为爆款
return_rate REAL, -- 近 30 天退货率(0-1 之间的小数)
review_score REAL -- 买家评分(1.0-5.0)
);
踩坑记录:prompt 里没有「只生成 SELECT」的约束,模型偶尔会生成 DROP TABLE 或 UPDATE。加了这条约束之后从未再出现。另外,时间范围的歧义是最高频的错误来源,必须在 prompt 里把每种说法的 SQL 写法都列出来。 | |
| |
| |
| |
| Text-to-SQL Prompt 模板、图表 Schema 定义、业务术语表 |
项目四:多语言内容生成 Agent(ClawdBot)跨境卖家上一个新品的内容生产链路极其冗长:拍图、修图、写主图文案、写详情页、翻译、本地化、合规审核、关键词优化,每个环节都可能往返几次。更复杂的是,不同平台的规则差异很大。日本亚马逊对 listing 格式的要求和美国站完全不同,欧盟站有额外的合规要求,独立站又是另一套逻辑。多语言 × 多平台的组合让内容生产成本呈指数级增长。▶ 图像理解:Claude 视觉能力提取商品类目、材质、核心卖点、颜色规格▶ 结构化输出:图像理解结果转成标准化「商品属性 JSON」,作为后续生成的输入▶ 多语言生成:基于商品属性 JSON,按目标市场(英、日、西班牙语)生成详情页文案▶ Agent Skills 并行执行:合规检测 Skill + 关键词优化 Skill 并行跑,结果合并回主流程▶ 人工确认节点:生成结果推给卖家审核,支持单条修改,确认后输出发布格式Agent Skills 的扩展性是核心设计价值:合规检测和关键词优化是两个独立的 Skill,以标准协议接入主 Agent。后续要加图片主图评分、A/B 测试建议,直接开发新 Skill 接入即可,主流程不动。关键节点一:从竞品截图生成 UI 骨架(节省约 40% 前端时间)这个项目不从 Figma 原型出发,直接拿竞品截图驱动前端开发:我上传了一张跨境电商内容生成工具的界面截图。
请帮我:
1. 分析这个界面的组件结构,列出所有可识别的 UI 组件
2. 用 React + Tailwind CSS 复刻这个界面的骨架(只要布局和样式,不需要实现逻辑)
3. 每个区域用注释标注:// 商品图片上传区、// 生成结果展示区 等
4. 按 components/ 目录组织,每个主要组件单独建文件
先输出组件拆解分析,我确认后再生成代码。
关键节点二:多语言 Prompt 模板(可直接复用)不同市场的 prompt 差异很大,这里给三个市场的模板框架:LISTING_PROMPTS = {
"en_us": """You are an expert Amazon US copywriter.
Based on product attributes below, generate:
- Title: 150-200 chars, include main keywords naturally
- 5 Bullet Points: start each with CAPITALIZED feature name
- Description: 2000 chars, focus on use scenarios
Output as JSON only. No extra text.
Product attributes: {product_json}""",
"ja_jp": """あなたはAmazon Japan専門のコピーライターです。
以下の商品属性を基に生成してください:
- タイトル:全角50文字以内
- 商品説明:日本の生活シーンに合わせた丁寧語
- 禁止:過度な誇張、未確認の効果効能
JSON形式のみで出力。商品属性:{product_json}""",
"es": """Eres experto copywriter para Amazon España/Latinoamérica.
Genera listing con estilo cercano y conversacional.
Título máx 200 chars, 5 puntos clave, descripción natural.
Solo JSON. Atributos: {product_json}"""
}
关键节点三:Agent Skills 并行执行思路两个 Skill 用 asyncio.gather() 并行跑,核心设计原则是任一 Skill 失败不阻塞主流程:async def run_skills_parallel(listing_content):
compliance_task = compliance_check_skill(listing_content)
keyword_task = keyword_optimization_skill(listing_content)
# 任一失败不阻塞,返回 None 时在结果里标记「该检查未完成」
results = await asyncio.gather(
compliance_task,
keyword_task,
return_exceptions=True
)
return merge_skill_results(listing_content, results)
# 合规检测的核心规则(硬编码,不交给 AI 判断)
COMPLIANCE_RULES = [
"不能包含:最佳、第一、100% 等绝对化用语",
"不能包含医疗功效声明",
"标题不能全大写"
]
踩坑记录:图像理解输出必须强制 JSON 格式,否则模型有时会在 JSON 前后加解释性文字,解析直接报错。在 prompt 末尾加一行「只输出 JSON,不要任何其他文字」可以解决 95% 的格式问题。剩下 5% 用 try/except 捕获,降级为要求用户手动输入商品属性。 | |
| |
| |
| |
| 多语言 Prompt 模板、Agent Skills 协议、截图驱动开发流程 |
四个项目跑完之后做了一次盘点,看看哪些东西被复用了:- OpenAPI 契约模板:项目三和项目四共用了同一套 FastAPI 接口规范模板,前端对接成本降低明显
- LangChain Agent 脚手架:项目一的 Agent 架构直接被项目四复用,只替换了 Tool 集合
- 流式 SSE 方案:项目二的流式响应方案完整移植到项目四,一行代码没有重写
- Docker 部署配置:四个项目的 Dockerfile 结构一致,只有基础镜像和环境变量不同
这种复用不是偶然的,是因为每个项目的 Phase 1 都强制对齐接口契约格式,Phase 3 都强制容器化。标准化流程产生标准化资产,标准化资产降低下一个项目的启动成本。做到第三个项目的时候,启动速度比第一个快了大概 30%。不是因为更熟悉工具了,而是因为有了可以直接复用的工程资产。这就是标准化流程的复利。
AI 生成的代码质量大多数时候是够用的,真正的风险是:如果需求定义不清,AI 会非常高效地生成一个方向错误的实现。压缩 Phase 1 省下来的时间,会在 Phase 2 以 3 倍的代价还回来。2. Tool Schema 设计是 Agent 项目的真正瓶颈很多人以为 Agent 项目的难点在于模型选择或 prompt 工程,实际上最费时间的是 Tool Schema 的设计和迭代。Schema 粒度、参数定义、返回格式,每一项都直接影响 Agent 的决策质量。没有银弹,必须在真实业务场景下反复测试和调整。很多团队把 prompt 写在代码注释里,每次改一点又不记录。实际上 prompt 和数据库 Schema 一样,是系统的一部分,需要版本管理、变更记录、回归测试。每个项目建一个 prompts/ 目录,把所有 prompt 模板单独维护,是这四个项目里最值得推广的工程习惯。一个项目能不能顺利容器化,是检验工程质量的试金石。如果 Dockerfile 写起来很痛苦,通常意味着代码里存在环境耦合问题。我们的原则是:Dockerfile 是项目的第一个文件,而不是最后一个。5. Human-in-the-loop 的位置比存在更重要不是所有项目都需要 Human-in-the-loop,但当你决定加入这个节点时,它的位置和触发条件必须在架构层面定义清楚。我们的标准是:不可逆的操作,必须走人工节点;可重试的操作,可以完全自动化。
Vibe Coding 这个词现在很热,但多数讨论停留在「AI 能帮你写代码」这个层面。更深一层的东西是:AI 改变的不只是写代码的速度,而是工程师的精力分配方式。重复性的代码实现交给 AI,架构判断、业务理解、Schema 设计、质量把控——这些才是工程师真正应该花时间的地方。当你把精力从「怎么写」转移到「写什么」和「为什么这么写」,交付质量和速度会同时提升。文章里的 prompt 模板可以直接拿去用,把方括号里的内容替换成你的业务场景。这套流程还在持续迭代,如果你在类似场景有不同的工程实践,欢迎交流。
AI 编程工作流选型指南:Spec-Kit、OpenSpec、Superpowers、Spec-First 全面对比(附实操落地路径)
我有个朋友,做了十年后端开发。去年他跟我说,用上 Cursor 之后效率翻了三倍,代码写得飞快。上个月再聊,他有点沮丧:AI 写的代码越来越难维护,改一个地方出三个问题,有时候同一个逻辑前后不一致,跑起来也没问题,但下次接手的人(包括他自己)完全不知道这段代码为什么这么写。他问我:"是不是我的 prompt 写得不够好?"
第一阶段,你学会用 Copilot 补全代码,感叹"哇,真方便"。第二阶段,你开始用 Cursor 或 Claude Code 做稍微复杂的功能,AI 能写、能改、能调 bug。第三阶段,你开始做超过三个文件的项目,然后你发现——AI 越跑越偏,第 100 行代码和第 10 行的逻辑开始矛盾,上下文一长就开始"失忆",你花在修正 AI 输出上的时间,比直接写代码还多。这就是所谓的 Vibe Coding 瓶颈。不是模型不够聪明,而是你在让一个"能力极强但极度字面意思"的家伙在没有图纸的情况下盖房子。解法其实早有人想清楚了:在写第一行代码之前,先把"做什么、为什么做、怎么做"说清楚。这套方法论叫做规范驱动开发(Spec-Driven Development,SDD)。2025 年下半年到 2026 年,围绕 SDD 理念,社区涌现出一批非常优秀的工具。今天要聊的四个,是目前讨论度最高、实际可落地的选项:Spec-Kit、OpenSpec、Superpowers,以及作为底层理念的 spec-first。
很多人第一次看到这几个名字,会以为它们是"功能类似、选一个就行"的竞品关系。- Spec-Kit 是建筑规范手册,规定了"什么材料、什么标准、什么流程,必须照做"
- OpenSpec 是施工变更单,记录了"这次改动了什么、为什么改、改到哪里"
- Superpowers 是施工队的操作手册,规定了"工人怎么干活、先干什么后干什么、验收标准是什么"
- spec-first 是一种建筑哲学:"先画图纸,再动砖头"
spec-first(理念层)
↓
Spec-Kit / OpenSpec(规范管理层)
↓
Superpowers(执行纪律层)
三、Spec-Kit:GitHub 官方出品,"宪法派"的代表如果只能记住一句话,就把这句记住: 这里的开发,有法可依。Spec-Kit 是 GitHub 官方在 2025 年推出的开源工具包,专为 AI 辅助编程设计,核心思想是"规范先行"——先精确定义做什么和为什么,再由 AI 基于清晰的规范生成代码。Constitution(宪法)
→ Specify(功能规范)
→ Plan(技术方案)
→ Tasks(任务拆解)
→ Implement(代码实现)
其中最有意思的是第一步 Constitution。这份"宪法"文件定义了项目的最高原则,比如测试覆盖率要求、代码风格、技术栈限制、安全策略等。一旦写进去,后续所有 AI 的行为都要以此为约束,不可逾越。# 项目宪法
## 技术标准
- 前端:React + TypeScript
- 后端:Node.js,禁止引入 ORM 以外的数据库抽象层
## 质量要求
- 单元测试覆盖率 ≥ 85%
- 所有 API 必须有错误处理
## 简化原则
- 初始实现特性数 ≤ 3,多一个要写说明理由
AI 在整个开发过程中都要遵守这些原则,不会因为你一时的 prompt 就跑偏。复杂的新建项目、对合规性有要求的企业场景,或者团队协作中需要统一标准的情况。项目越复杂,前期投入的回报越高——经验来看,超过 3-5 个模块的项目,用 Spec-Kit 的系统化规划能在后续执行阶段节省大量返工时间。快速迭代的小需求、已有代码库的局部改动,以及不想搭 Python 环境的朋友(Spec-Kit 依赖 uv 包管理器)。有人用完 Spec-Kit 的感受是"一片 Markdown 的海洋"——确实,它很重,前期要写大量文档。如果你的项目本身就不复杂,这个成本可能超过收益。pip install uv
git clone https://github.com/github/spec-kit.git
# 在 Claude Code 中依次执行:
/speckit.constitution
/speckit.specify "用户登录功能,邮箱密码验证,返回JWT"
/speckit.plan
/speckit.tasks
/speckit.implement
四、OpenSpec:轻量敏捷,专门为存量项目设计如果只能记住一句话,就把这句记住: 这里的变更,有据可查。OpenSpec 来自 Fission-AI 团队,定位很明确:为已有项目提供低侵入性的规范层,在改需求之前先把"要改什么、为什么改"讲清楚。它最核心的设计是 Delta Specs(增量规范):把"当前项目的事实"和"这次的变更提案"明确分开存放。openspec/
├── specs/ # 当前项目的真相(已建立的能力)
└── changes/ # 变更提案(准备改的东西)
└── add-dark-mode/
├── proposal.md # 为什么改、改什么
├── specs/ # 这次涉及的规范变更
├── design.md # 技术方案
└── tasks.md # 任务清单
每次改需求,都是一个独立的"变更单"。改完之后执行 archive,变更合并回主规范库,历史可查。这个设计解决了一个很实际的问题:规范不会随着项目演进而失真。很多团队的文档最大问题就是,写完就扔,代码改了文档没改,两边越来越对不上。OpenSpec 通过强制的"归档"步骤,让规范始终跟着代码走。它还有一个亮点:支持 25+ 种 AI 工具,零 API 密钥,完全用你本地已有的工具。存量项目维护、需求频繁迭代的中小团队、个人开发者。特别是那种"已经有一堆代码,但没有任何规范文档,想补上又不知道从哪里下手"的场景,用 OpenSpec 可以从下一个需求开始,渐进式地把规范建立起来。npm install -g openspec-cn # 推荐中文版
cd your-project
openspec init
# 在 Cursor 或 Claude Code 中:
/opsx:new add-dark-mode # 创建新变更
/opsx:ff # 快进,自动生成所有文档
/opsx:apply # 执行实现
/opsx:archive # 归档,更新主规范库
五、Superpowers:不管规范,只管行为纪律如果只能记住一句话,就把这句记住: 这里的代码质量,有保证。Superpowers 跟前两个都不一样。它不关心你写没写规范文档,它关心的是:AI 在执行的时候有没有按照工程最佳实践来干活。这是 Jesse Vincent(GitHub ID:obra)在 2025 年 10 月开源的项目,进入 Anthropic 官方插件市场后迅速爆发,目前 Star 数已经突破 15 万,是同期增长最快的开发工具之一。它的核心理念是 Process over Prompt(流程大于提示词):与其给 AI 写更精准的 prompt,不如给 AI 套上一套工程纪律,让它像有经验的工程师一样工作。安装之后,AI 在处理任何超过 50 行代码的任务时,都会强制走这套流程:brainstorming(需求澄清)
→ git worktrees(创建隔离分支)
→ writing-plans(拆成 2-5 分钟粒度的任务)
→ TDD(先写测试,再写实现)
→ subagent execution(子代理并行执行)
→ code review(双阶段审查)
→ finish branch(验收,处理分支)
最有意思的是 TDD 强制这一步。AI 必须先写出"会失败的测试",再写实现代码让测试通过,最后重构。任何试图跳过这一步的 prompt,Superpowers 都会拒绝执行,并解释为什么。关于 Token 消耗的问题:完整跑下来确实比直接写代码多消耗 10-20% 的 Token,但返工减少了 60-70%。算总账是划算的。Claude Code 重度用户、对代码质量有硬性要求的正式项目、想让 AI 产出"能上线"而不只是"能运行"的代码的开发者。注意: Superpowers 本身不负责管理规范文档,它只管执行时的行为约束。所以它最好跟 OpenSpec 或 Spec-Kit 配合使用:前者负责"做什么",后者负责"怎么做好"。# 在 Claude Code 中执行:
/plugin marketplace add obra/superpowers-marketplace
/plugin install superpowers@superpowers-marketplace
# 重启 Claude Code 后,使用:
/superpowers:brainstorm # 从需求澄清开始
/superpowers:write-plan # 生成执行计划
/superpowers:execute-plan # 开始执行
npm install -g superpowers-zh
前三个都是具体工具,spec-first 是它们共同的底层哲学,值得单独说一下。它的核心很简单:在写第一行代码之前,先把以下四件事写清楚。## 做什么(What)
用户可以用邮箱+密码登录,登录成功返回 JWT token
## 为什么做(Why)
现在没有认证机制,所有接口都是裸露的
## 约束(Constraints)
- 密码必须 bcrypt 加密
- 连续 5 次失败锁定 15 分钟
- token 有效期 7 天
## 非目标(Non-Goals)—— 这条最重要
- v1 不做 OAuth 第三方登录
- v1 不做手机号登录
- 不做"记住我"功能
"非目标"这一栏是整个 spec-first 里最有价值的部分。 它明确告诉 AI"不要做什么",这比告诉它"要做什么"更重要。很多时候 AI 跑偏,是因为它太"积极"了,总想帮你把没说到的边角案例也一起实现。不想装任何额外工具?用 spec-first 理念也完全可以上手:在项目根目录维护一个 AGENTS.md 文件,写上你的项目约束和 AI 行为规范。每次开新会话,先粘贴你的需求模板,把"做什么/为什么/约束/非目标"填完,再开始跟 AI 对话。
你的情况是什么?
│
├─ 全新项目 + 团队 ≥ 3 人 + 流程要正规
│ └─→ Spec-Kit
│
├─ 已有代码库 + 要加新功能或局部重构
│ └─→ OpenSpec
│
├─ 主要用 Claude Code + 想提升代码工程质量
│ └─→ Superpowers
│
├─ 先感受一下 SDD 是什么,不想装工具
│ └─→ spec-first(AGENTS.md 即可)
│
└─ 想要最强组合?
└─→ OpenSpec(规划对齐)+ Superpowers(执行纪律)
这是目前社区最推荐的黄金搭档
下面是 OpenSpec + Superpowers 组合的完整实战流程,一步步跟着来。npm install -g openspec-cn
# 在 Claude Code 中:
/plugin marketplace add obra/superpowers-marketplace
/plugin install superpowers@superpowers-marketplace
# 重启 Claude Code
cd your-project
openspec init
/opsx:new add-user-login
/opsx:ff
/opsx:ff 是"快进"命令,会自动生成 proposal.md、design.md 和 tasks.md。生成之后先别急着执行——打开 proposal.md,手动补上"非目标"那一栏:## 非目标(v1 不做)
- OAuth 第三方登录
- 手机号登录
- 记住我功能
这步很多人会跳过,跳过之后 AI 就会开始"好心办坏事"。AI 会先问你几个关键问题,比如密码策略、token 过期时间等。回答完之后:它会读取 OpenSpec 的 tasks.md,生成极细粒度的执行计划——每个任务精确到文件名和函数名,2-5 分钟粒度。/superpowers:execute-plan
接下来就是 AI 自动干活:创建 Git 分支、写失败测试、写实现代码、让测试通过、双阶段代码审查。/opsx:verify # 检查代码是否符合规范
/opsx:archive # 合并回主规范库
跑完这一套之后,你的项目里会有一份完整的、可追溯的开发记录。下次新成员接手,或者半年后你自己接手,打开 openspec/specs/ 就能知道这套登录是怎么设计的、为什么这么设计。
有人用了三个月 Spec-Kit 最后放弃了,原因是企业的真实需求是多线并行、随时变更,Spec-Kit 的严格阶段门控在这种场景下变成了阻碍。工具没有错,只是不适合那个场景。选型之前先想清楚你的项目特点。第二条: 规范写完不是终点,上下文管理才是真正的成本。AI 会失忆。长对话必然导致前面的约束被后面的 prompt 覆盖。建议把"规划会话"和"执行会话"分开,通过文件传递上下文,而不是在一个超长对话里做所有事情。用 SDD 用得好的人,真正提升的不是"配置工具的能力",而是需求抽象能力、约束定义能力、任务拆解能力。工具帮你把这三种能力固化成流程,但能力本身还是要靠你自己练。
未来的编程竞争,不是谁写代码写得快,而是谁能把问题定义得更清楚。Spec-Kit、OpenSpec、Superpowers,这些工具本质上都是在做同一件事——把"先想清楚再动手"这个工程习惯,强制执行化。让 AI 帮你把流程跑起来,而不是靠你个人的自律。如果没有,从这周开始加一个。不一定要装复杂的工具,先从 AGENTS.md + 需求模板开始。感受一下"先签字,后动手"和"边做边改"的差别。
RAG+语音=下一代智能客服?方案已就位,零基础也能跑通
最近在做一个客服系统的项目,客户提了个需求:能不能让AI客服像真人一样,用户直接说话就能查到公司知识库的答案,还要用语音回复?传统的文字聊天机器人已经不够用了。
这让我想起一个场景:你开车的时候想查一下保险条款,总不能停下来打字吧?或者你在做饭,手上都是油,却想问问智能助手今天晚餐的食谱建议。这就是语音RAG Agent的价值所在——让AI真正理解你说的话,从知识库里找到准确答案,再用自然的语音告诉你。
今天我们就来聊聊怎么搭建这样一个系统。不是那种纸上谈兵的架构图,而是真刀真枪能跑起来的代码。
一、先说说这东西到底解决什么问题
传统的聊天机器人有几个痛点:
知识更新滞后:大模型虽然强大,但它的训练数据是有截止日期的。你公司上周刚发布的新政策,它根本不知道。
缺乏实时交互:文字聊天总是有种"隔靴搔痒"的感觉,特别是在移动场景下,语音交互才是王道。
信息检索不精准:纯靠大模型的记忆,很容易出现"一本正经地胡说八道"的情况。
RAG(检索增强生成)就是来解决第一和第三个问题的——它让AI在回答问题之前,先去你的知识库里查一查,找到最相关的资料,再基于这些资料生成回答。就像你考试的时候可以翻书,准确率自然就上来了。
而语音功能的加入,则让整个交互体验提升了一个档次。想象一下这个场景:
用户(语音):"帮我查一下公司关于远程办公的最新规定"
AI助手(语音):"根据2025年12月更新的员工手册,远程办公政策如下:每周至少需要到办公室两天,周三为固定办公日..."
整个过程流畅自然,就像在和真人对话。
二、技术架构:这些模块是怎么配合工作的
在动手之前,我们需要理解整个系统的工作流程。其实并不复杂,核心就是五个步骤:将用户语音输入转换为文字,经智能检索与生成得到答案,最后再转换为语音输出给用户。
具体来说:
1. 语音捕获与转录(STT)
用户通过麦克风说话,系统实时捕获音频流。这里我们用到AssemblyAI或者OpenAI的Whisper来做语音识别。Whisper的好处是精度高,支持多语言,AssemblyAI则提供了更好的实时流处理能力。
2. RAG检索引擎
这是核心部分。用户的问题转成文字后,系统会:
将问题转换成向量(Embedding)
在向量数据库里搜索最相关的文档片段
把这些片段作为上下文,和用户问题一起喂给大模型
这里的向量数据库可以用Qdrant、Pinecone或者简单点用FAISS。我个人倾向于Qdrant,开源免费,性能也不错。
3. LLM推理
拿到检索结果后,大模型(可以用GPT-4、Claude,或者本地的Llama/Gemma)基于这些上下文生成答案。关键是要在prompt里明确告诉模型:"请基于以下知识库内容回答,不要编造信息"。
4. 语音合成(TTS)
答案生成后,通过Cartesia把文字转成语音。Cartesia的优势是音质接近真人,延迟低,非常适合实时对话场景。
5. 实时通信
这一切都需要在一个实时通信框架里跑起来。LiveKit就是为此而生的——它处理音视频流、会话管理、低延迟传输等底层细节,让我们可以专注于业务逻辑。
三、开始动手:两种实现方案
我准备了两套方案,一套用OpenAI全家桶,适合快速上线;另一套用开源模型,适合对成本和数据隐私有要求的场景。
方案一:OpenAI + Cartesia(快速上手版)
这个方案的好处是简单快速,缺点是每次调用都要花钱,而且数据要发到OpenAI的服务器。
第一步:准备环境
# 确保你的Python版本 >= 3.11python --version# 安装依赖pip install livekit livekit-agents livekit-plugins-openai livekit-plugins-cartesia python-dotenv
第二步:获取API密钥
你需要准备这些:
OpenAI API Key - 去 https://platform.openai.com 注册获取,也可以使用兼容open ai接口的其他大模型。
Cartesia API Key - 去 https://cartesia.ai 申请,有免费额度。
LiveKit凭证 - 去 https://livekit.io 创建项目,获取URL和API密钥。
第三步:核心代码实现
创建一个.env文件:
OPENAI_API_KEY=sk-your-openai-keyCARTESIA_API_KEY=your-cartesia-keyLIVEKIT_URL=wss://your-project.livekit.cloudLIVEKIT_API_KEY=your-livekit-api-keyLIVEKIT_API_SECRET=your-livekit-api-secret
然后是主程序voice_agent_openai.py:
import asyncioimport osfrom dotenv import load_dotenvfrom livekit import agentsfrom livekit.agents import JobContext, WorkerOptions, clifrom livekit.agents.llm import ChatContext, ChatMessagefrom livekit.plugins import openai, cartesia# 加载环境变量load_load_dotenv()# 这是你的知识库文档,实际使用时应该从向量数据库检索KNOWLEDGE_BASE = """公司远程办公政策(2025年12月更新):1. 每周至少需到办公室两天2. 周三为全员固定办公日3. 远程办公需提前在系统中申请4. 工作时间保持在线状态,及时响应消息公司年假政策:1. 入职满一年员工享有5天年假2. 工作满三年增加到10天3. 年假需提前两周申请"""async def entrypoint(ctx: JobContext): """Agent的入口函数""" # 初始化各个组件 initial_ctx = ChatContext( messages=[ ChatMessage( role="system", content=( "你是一个友好的公司HR助手。请基于提供的知识库内容回答员工问题。" "如果知识库中没有相关信息,请诚实告知用户你不确定,建议他们咨询HR部门。" f"\n\n知识库内容:\n{KNOWLEDGE_BASE}" ) ) ] ) # 连接到房间 await ctx.connect() # 配置Agent assistant = agents.VoiceAssistant( vad=agents.vad.SileroVAD(), # 语音活动检测 stt=openai.STT(), # 使用OpenAI的Whisper做语音识别 llm=openai.LLM(model="gpt-4o-mini"), # 使用GPT-4o-mini tts=cartesia.TTS(), # 使用Cartesia做语音合成 chat_ctx=initial_ctx ) # 启动助手 assistant.start(ctx.room) # 打个招呼 await assistant.say("你好!我是HR助手,有什么可以帮你的吗?", allow_interruptions=True)if __name__ == "__main__": # 启动Agent Worker cli.run_app(WorkerOptions(entrypoint_fnc=entrypoint))
运行起来
python voice_agent_openai.py start
启动后,你可以用LiveKit的Agents Playground来测试。输入你的LiveKit URL和Token,就能开始语音对话了。
方案二:本地模型版(省钱隐私版)
如果你想完全本地化,或者需要处理敏感数据,可以用这个方案:用AssemblyAI做STT,Ollama跑本地Gemma模型做推理,Cartesia做TTS。
第一步:安装Ollama
# macOSbrew install ollama# Linuxcurl -fsSL https://ollama.com/install.sh | sh# 启动Ollama服务ollama serve# 拉取Gemma模型(另开一个终端)ollama pull gemma:7b
第二步:安装依赖
pip install livekit livekit-agents livekit-plugins-assemblyai livekit-plugins-ollama livekit-plugins-cartesia python-dotenv
第三步:更新配置
.env文件改成:
ASSEMBLYAI_API_KEY=your-assemblyai-keyCARTESIA_API_KEY=your-cartesia-keyLIVEKIT_URL=wss://your-project.livekit.cloudLIVEKIT_API_KEY=your-livekit-api-keyLIVEKIT_API_SECRET=your-livekit-api-secret
第四步:本地化代码
voice_agent_local.py:
import asyncioimport osfrom dotenv import load_dotenvfrom livekit import agentsfrom livekit.agents import JobContext, WorkerOptions, clifrom livekit.agents.llm import ChatContext, ChatMessagefrom livekit.plugins import assemblyai, ollama, cartesiaload_dotenv()KNOWLEDGE_BASE = """# 你的知识库内容"""async def entrypoint(ctx: JobContext): """使用本地模型的Agent入口""" initial_ctx = ChatContext( messages=[ ChatMessage( role="system", content=( "你是一个专业的HR助手。请严格基于以下知识库回答问题,不要编造信息。" f"\n\n{KNOWLEDGE_BASE}" ) ) ] ) await ctx.connect() assistant = agents.VoiceAssistant( vad=agents.vad.SileroVAD(), stt=assemblyai.STT(), # AssemblyAI的语音识别 llm=ollama.LLM(model="gemma:7b"), # 本地Gemma模型 tts=cartesia.TTS(), # Cartesia语音合成 chat_ctx=initial_ctx ) assistant.start(ctx.room) await assistant.say("你好,我是本地部署的HR助手,请问有什么可以帮你?")if __name__ == "__main__": cli.run_app(WorkerOptions(entrypoint_fnc=entrypoint))
四、接入真正的RAG系统
上面的例子中,知识库是硬编码在代码里的,这显然不够灵活。真实场景下,你需要:
文档处理:把PDF、Word、网页等文档切分成小块(Chunk)
向量化存储:用Embedding模型把文档转成向量,存入向量数据库
实时检索:用户提问时,查询向量数据库找到最相关的文档片段
上下文注入:把检索结果注入到LLM的prompt里
这里给个检索函数的示例:
from qdrant_client import QdrantClientfrom qdrant_client.http import modelsfrom sentence_transformers import SentenceTransformer# 初始化client = QdrantClient(url="localhost:6333")encoder = SentenceTransformer("all-MiniLM-L6-v2")async def retrieve_context(query: str, top_k: int = 3): """从向量数据库检索相关上下文""" # 把问题转成向量 query_vector = encoder.encode(query).tolist() # 在Qdrant中搜索 search_result = client.search( collection_name="knowledge_base", query_vector=query_vector, limit=top_k ) # 提取文档内容 contexts = [hit.payload["text"] for hit in search_result] return "\n\n".join(contexts)
然后在Agent中使用:
async def entrypoint(ctx: JobContext): await ctx.connect() # 自定义消息处理 @ctx.on_message async def on_user_message(message: str): # 检索相关上下文 context = await retrieve_context(message) # 构建增强的prompt enhanced_message = ChatMessage( role="user", content=f"上下文:\n{context}\n\n用户问题:{message}" ) # 让LLM基于上下文回答 # ... 后续处理 # 启动assistant # ...
五、实际应用场景
搭完这套系统,它能用在哪儿?我列几个真实场景:
1. 企业内部知识库助手
员工可以语音问"上个月的销售数据在哪儿",系统从SharePoint或者内部Wiki里找到相关文档,直接语音回复。特别适合开车通勤路上处理工作事务。
2. 客服语音机器人
接入公司的产品文档、FAQ、售后政策,24小时不间断服务。用户打电话进来,直接语音交互,比按键式IVR体验好太多。
3. 医疗咨询助手
医生可以语音查询病例、药品说明、诊疗指南。特别是在手术中,不方便操作电脑时,语音交互就显得尤为重要。
4. 教育辅导
学生可以对着AI老师提问题,"帮我解释一下牛顿第二定律",系统从教材库里检索相关知识点,用语音讲解。
六、一些实战经验
搭建过程中踩了不少坑,分享几个经验:
1. 语音识别的坑
2. RAG检索质量
Chunk大小:文档切分太大,检索不精准;切分太小,上下文不完整。我测试下来,300-500个token是个比较平衡的值
相似度阈值:不是所有检索结果都有用,设个阈值(比如0.7),过滤掉相关度太低的内容
混合检索:纯向量检索有时候会漏掉关键词匹配。可以结合BM25算法做混合检索,效果更好
3. 延迟优化
流式输出:TTS可以边生成边播放,不用等整个回答生成完。Cartesia支持流式合成,用户体验好很多
预热模型:第一次调用模型往往比较慢,可以在启动时做warm-up
CDN加速:如果是全球化应用,考虑用CDN加速音频传输
4. 成本控制
OpenAI的API调用是按token计费的,大量对话下来成本不低:
我的建议是:开发测试用OpenAI,上生产后根据QPS和数据敏感度,决定是否切换本地模型。
七、监控和调试
系统上线后,监控很重要。我一般会关注这几个指标:
import loggingfrom datetime import datetime# 记录关键步骤的耗时async def measure_performance(step_name: str): start_time = datetime.now() # 执行某个步骤 # ... end_time = datetime.now() latency = (end_time - start_time).total_seconds() logging.info(f"{step_name} latency: {latency:.2f}s") # 如果延迟过高,发告警 if latency > 3.0: # 超过3秒 logging.warning(f"High latency detected in {step_name}")
还要记录:
STT错误率(识别失败或超时)
RAG召回率(检索到的文档相关性)
用户满意度(可以让用户对每次对话打分)
八、下一步可以做什么
基础功能跑通后,还有很多可以优化的方向:
多轮对话记忆:目前每次对话都是独立的,可以加上对话历史,支持上下文追问
情感识别:分析用户语音中的情绪,如果检测到愤怒或不满,可以转人工客服
多模态融合:除了语音,还可以接入摄像头,支持"拍照提问"
个性化定制:根据用户画像调整回答风格,给VIP客户更详细的解答
A/B测试:对比不同模型、prompt策略的效果,持续优化
九、总结
搭建一个能听会说的RAG Agent,技术上并不复杂,核心就是把几个成熟的组件串起来:语音识别(STT)、检索增强(RAG)、大模型推理(LLM)、语音合成(TTS)、实时通信(LiveKit)。
难点在于细节的打磨:延迟优化、准确率提升、成本控制、异常处理。但这些都是工程化的问题,只要愿意花时间,都能解决。
这套架构的可扩展性很强。你可以把语音换成文字,变成普通的RAG聊天机器人;也可以保留语音,把知识库换成实时数据接口,变成一个能查天气、查股票的生活助手。
最重要的是,它真的能解决实际问题。相比于纯文字机器人,语音交互在很多场景下有压倒性优势——开车、做饭、做手术、带娃...任何需要解放双手的时候,语音才是最自然的交互方式。
而RAG则保证了AI不是在瞎编,每句话都有据可查。这对企业应用尤其重要——没人希望客服机器人给用户传达错误信息。
最后说一句:AI技术迭代太快,今天写的东西,可能明年就过时了。但核心思路是不变的——让机器更懂人类,让技术服务于人。这才是我们做这一切的意义。
免费高效 PPTX+XLSX+DOCX+PDF skills全家桶!建议每个打工人都用上:终于能直接交作业
用 AI 写文案、做分析、搭框架,这些早就不稀奇了。但每次到最后一步,把内容"装进"一个正式文件里,就开始崩。PPT 要么全是子弹点堆砌,要么配色像 2005 年的 Windows 主题;Excel 表格里的"合计"是手打的死数字,改一个数全乱;Word 标书交上去,因为目录格式不对被打回来……内容是好内容,但文件是烂文件。这个问题,用了这么久 AI,依然没有被解决。直到前几天,我发现了 MiniMax 在 GitHub 上开源的这套东西:Skills 工具箱。
我第一反应是:又是一个要配环境、装依赖、踩一堆坑才能跑起来的东西。安装方式简单到有点出乎意料:直接把这个链接发给你正在用的 AI 工具,让它自己去读、自己去装就行了。https://github.com/MiniMax-AI/skills
不管你用的是 Claude Code、Cursor、Codex、OpenCode,还是国内的 OpenClaw、通义灵码(Lingma),操作都是一样的——打开对话框,把这个链接粘进去,告诉它"帮我安装这些 Skills",AI 工具会自己去读仓库里的安装说明,然后自动完成配置。我自己用的是 Claude Code,发过去之后它自己跑了一遍,重启之后技能就已经加载好了。整个过程我没有手动敲过一行命令,没有查过任何文档,前后大概两分钟。用 Cursor 的朋友也试了,同样是把链接扔进去让它装,Cursor 自己识别了仓库结构,把路径配好了。OpenClaw 和通义灵码也没有例外——这类工具本身就有读取外部 Skill 配置的能力,给它链接它就知道该怎么处理。整个安装体验就是这样:你只需要知道那个链接,剩下的事情交给 AI。
我测这个的起因很简单——上个月帮一个朋友做了一份财务模型,让 AI 生成的表格,数据全是硬编码的,"合计"那格写的就是个数字,根本不是公式。改一个收入数字,整张表就废了。装上 Skill 之后,我让它重新生成了一份季度财务复盘表。打开文件,点进"合计"那个单元格,公式栏里显示的是 =SUM(B3:B6)——是真的公式,不是摆设。改了一个收入数字,旁边的毛利率和同比增速跟着变了。还有一个细节让我多看了几眼:表格用了投行级的配色逻辑,蓝色是可以手动输入的单元格,黑色是公式计算出来的结果,绿色是跨表引用。这套规范在金融行业是默认惯例,但我之前用 AI 做出来的表格从来没见过这个意识。做财务建模、月度数据复盘、KPI 追踪表的人,这个省时间省得实实在在。
做过招投标的人都懂,标书对格式的要求近乎变态。目录层级、页眉奇偶页、章节自动编号、特定字体……哪怕内容写得再好,格式出了问题,直接废标。我有个同事就因为 Word 自动目录没更新,提交前是对的,打印出来变了,被打回来重做。我测的时候,让它生成了一份带三级目录的技术方案文档。打开文件,目录页是自动生成的,每级标题对应的页码准确,章节编号是"1.1 / 1.1.1"这种格式,全部自动续接,没有一处错位。奇偶页页眉也分别设置了——奇数页显示章节名,偶数页显示文档标题,这个细节在正式标书里是基本要求,但手动设置非常容易出错。它底层用的是微软官方的 OpenXML SDK,不是套模板,是从文档结构层面重建的。内置 13 种排版预设,包括 IEEE 学术格式和招投标格式,直接告诉它用哪个就行。如果你经常要写论文、合同、政府公文,光是不用手动调格式这一件事,每次能省一到两个小时不夸张。
AI 做 PPT,我之前的体验一直是这样的:一页十几条 bullet point,配色是系统默认蓝,字体宋体,封面就是个大标题居中。我用它生成了一份产品季度复盘 PPT,指定了"商务"风格的配色方案。生成出来打开一看,封面、目录页、每个章节的过渡页、内容页,结构完整,不是只有内容堆在那里。配色是那种深蓝加米白的组合,不是系统默认的蓝,拿出去不会丢人。中文渲染没有乱码,字体也没有变形——我有一次用别的工具生成 PPT,中文全部变成了方框,这套没有这个问题。它内置了 18 套配色方案,除了商务,还有科技感、复古、母婴这些偏垂类的选项。如果你要的是一个能直接拿出去用的"毛坯",它能覆盖到这个标准。
这个我原本期待值最低,因为以往 AI 生成的 PDF 基本等同于"把 Word 另存为 PDF",没什么设计感可言。实测下来有点意外。它用了一个双引擎架构:封面部分用 HTML/CSS 渲染,正文用 Python 处理。生成出来的封面有渐变背景和网格纹理,那种视觉层次感是普通 Word 转 PDF 做不到的。我拿了一份市场分析报告的内容测,生成的封面第一眼看上去有点像咨询公司的对外报告,不是那种一眼看出来是 AI 生成的扁平风格。正文里的图表是 Matplotlib 生成的矢量格式,放大看依然清晰,打印也不糊。做融资路演材料、行业分析报告或者作品集,这个质量水位够用。
这套工具本质上是在给 AI 装了一套"专业办公软件操作规范"。以前 AI 帮你干活,相当于一个脑子很好但什么软件都不会用的实习生——内容没问题,但让他输出一份正式文件,你还得自己去调格式。有了这套东西,交付物从"我帮你想好了,你自己去排版",变成了"这是可以直接用的成品"。安装就是把这一个链接扔给你在用的 AI 工具,让它自己装:https://github.com/MiniMax-AI/skillsMIT 开源,免费,Claude Code、Cursor、Codex、OpenCode、OpenClaw、通义灵码都支持。需要高频产出正式文档的人,值得花两分钟试一下。
一文讲透!AI产品经理知识图谱:55个必懂概念
最近一个做了三年传统产品的朋友转型做AI产品后,跟我说了一句让我印象深刻的话——"我现在最怕的不是需求写不好,是不知道自己在评审什么。"这个感受太真实了。AI产品经理面对的困境,不是不够努力,是认知框架还是传统产品那套,但AI产品的底层逻辑根本不一样。下面这55个概念,不是技术词典,是我认为每个AI产品经理应该真正搞懂的认知地图——不需要你会写代码,但需要你知道AI怎么工作、边界在哪、为什么会出错,以及出错了你该怎么办。
很多AI产品做砸了,不是死在执行上,是死在认知上。产品经理对AI能做什么有根本性的误解,导致需求方向就错了,后面再怎么优化都没用。
你有没有认真想过,ChatGPT是怎么"思考"的?答案可能会让你有点失望:它不是在思考,它在做文字接龙。给它一段话,它预测下一个最可能出现的词,然后再预测下一个,循环往复直到停下来。这个底层机制带来三个硬约束,做AI产品的人必须刻在脑子里:第一,它不是在推理,是在算概率。 所以涉及严密逻辑推理的场景,比如复杂的数学题、多步骤的法律分析,它经常出错。那种信心十足但完全答错的场面,你一定见过。第二,它的知识有截止日期。 训练数据截止到某个时间点,之后的事情它一无所知,但它不会说"我不知道",它会编一个听起来很有道理的答案。第三,同样的问题,每次回答可能不一样。 因为在多个高概率词之间,它会随机选择。所以做AI产品,第一步不是想AI能做什么,而是想清楚AI做不了什么,然后把那些做不了的部分用规则、人工或者兜底策略补上。这个认知,能帮你避开60%的坑。
Token是大模型处理文本的最小单位。英文一个词大约1到1.5个Token,中文一个汉字大约1.5到2个Token。这件事为什么重要?因为它直接关系到两个产品决策:成本和上下文窗口。先说成本。很多团队写了一个2000字的System Prompt(系统提示词),觉得效果不错,就上线了。但他们没算一笔账:2000字大约消耗3000到4000个Token,假设日均10万次调用,光System Prompt这一项,一个月的费用就可能是好几万块。再说上下文窗口。模型能处理的Token总数有上限,比如16K。这16K要分给System Prompt、对话历史、检索到的文档、工具定义……真正留给业务内容的空间其实很少。需求评审时有个必做项:让算法同学给出这个公式的估算——单次Token消耗 × 日均调用量 × 单价 = 月成本。不算这笔账就拍板的AI项目,十个死九个。
很多人把Prompt理解成"跟AI聊天",这个理解太宽松了。Prompt本质上是在下达精确指令。同一个模型,Prompt写得好和写得差,输出质量能差十倍。一个好的Prompt有四个要素:角色设定(你是谁)、任务描述(做什么)、输出约束(格式和长度要求)、上下文信息(参考资料)。为什么Prompt这么关键?因为大模型靠概率预测下一个Token,你Prompt里的每一个词都在影响后续输出的概率分布。你说"简洁地回答"和"用三句话以内回答",效果可能差很多。有个经验值得记住:至少一半的效果问题,最后都是优化Prompt解决的。零成本,立竿见影。所以碰到效果问题先别急着换模型或者加RAG,先把Prompt反复改几轮。
System Prompt是对话开始前预设给模型的"人设说明书",用户看不到,但它决定了AI的行为模式和能力边界。每次API调用,它都会被完整发送一遍。有人问我怎么写好System Prompt,我的比喻是:像写岗位JD一样写。职责要明确,边界要清晰,有具体的行为示例。写得模糊,AI的表现就会模糊。另外别忘了成本这件事——System Prompt越长,每次调用烧的Token越多。长度是效果和成本的平衡点,不是越详细越好。
Temperature是个被很多人忽视,但影响很大的参数。它控制的是模型输出概率分布的随机性。Temperature设为0:模型每次都选概率最高的那个词,输出几乎完全确定。设为1或更高:低概率的词也有机会被选中,输出更多样但更不可预测。有个认知误区要纠正:Temperature控制的是随机性,不是准确性。设为0不代表不出错——如果模型对某个错误答案的概率预测本身就是最高的,设0反而会让它每次都坚定地给你那个错误答案。实际项目中的经验值:客服场景用0.1到0.3(需要回答稳定一致);创意写作用0.7到0.9(需要多样性);数据提取和格式化场景用0(结果必须完全可预测)。建议在PRD里明确写Temperature取值和原因,别让这个参数处于"不知道谁设的,也不知道为什么"的状态。
模型一次能处理的最大Token数量,就是上下文窗口。PM必须算清楚三笔账。成本账:上下文越长,单次Token消耗越多,成本越高。性能账:上下文越长,模型推理时间越长,延迟越高。效果账:这是很多人没意识到的——不是上下文越长效果越好,无关信息堆太多反而会干扰模型,让它不知道该关注哪里。设计原则只有一条:按需使用,只保留必要信息。能用摘要就不用全文,能用关键词就不用长段落。
很多人第一次看到模型一本正经地胡说八道,会觉得这是个Bug,修一修就好了。但事实是:幻觉不是Bug,是概率预测机制的必然结果。模型不知道什么是事实,只知道什么词经常一起出现。它没有"我不确定,所以不说"的本能,它的本能是"预测下一个最可能的词"。现状比你想象的更严峻:主流模型在事实性问答场景下的幻觉率大概在10%到30%之间,也就是说每三到十个回答里,可能就有一个是编的。产品层面有三条防线:RAG接地(让模型基于真实文档回答,而不是凭记忆);输出校验(模型回答之后做二次检查);信任度设计(标注信息来源,低置信度的内容转人工)。上线前必须做大规模Bad Case测试,这不是可选项。
"AI怎么记住我们之前说的话的?"这个问题,答案出乎很多人意料:它根本没有记忆。大模型没有记忆,每次API调用都是从零开始。 你感觉它"记住了",是因为后端每次把System Prompt加上所有历史对话消息,打包一起发给模型。模型看了这些历史,"想起来"了之前说的话。这带来一个实际问题:每多聊一轮,发送的内容就多一轮,Token消耗线性增长,迟早撞到上下文窗口的天花板。实用的处理方案是三层策略:最近3到5轮完整保留;更早的对话做摘要压缩;用户姓名、订单号、已确认需求这些关键信息单独提取出来放进System Prompt里,不让它淹没在对话历史中。
如果你做的是生成类AI产品,流式输出不是锦上添花,是基本生存线。原理很简单:通过SSE协议,模型每预测出一个Token就实时推送到前端,用户看到文字一个个蹦出来,而不是等几秒钟什么都没有然后突然出现一大段。后者的用户体验,在2024年已经完全无法接受了。PM需要盯三个指标:TTFT(首Token延迟,用户发请求到看见第一个字的时间,这个决定了用户感知快不快);TPS(每秒输出Token数,决定文字蹦出来的速度);断流重连(网络抖动时连接断了怎么续上)。
训练数据中存在的偏见会被模型学习并放大——性别偏见、地域偏见、职业偏见……这些东西在模型的回答里可能以很隐蔽的方式呈现,但被用户截图放出去,就是一次公关危机。应对上没有银弹,但有几件事值得做:审查训练数据是否多样平衡;对模型输出做偏见检测;建立用户反馈渠道让用户可以举报。别觉得这是做大了才需要考虑的问题,往往等你大了才意识到,就晚了。
这部分讲的是不需要改代码、不需要换模型,就能显著提升效果的手段。很多团队在效果不好的时候第一反应是换更贵的模型,其实应该先把这些手段用尽。
11.Few-shot Learning 少样本学习在Prompt里塞2到5个示例,让模型照着学。不改模型参数,不需要训练数据,成本为零,效果立竿见影。这个方法有效的原因是:大模型在预训练阶段已经学会了根据上下文模式进行推导,给示例就是在激活这个能力。实操经验:示例数量2到5个最优,多了没用;示例质量比数量重要十倍,必须是你最满意的标杆输出。PM日常最常用的三个场景:统一输出格式(给几个JSON示例模型就会照着输出);定义分类标准(给几个分类结果的示例模型就会按你的标准分);风格对齐(给几个风格范文模型就会学着写)。
为什么有效?因为大模型是一步一步预测Token的。如果直接跳到答案,模型必须在一个Token的预测窗口内完成所有推理,错误率很高。思维链让模型先输出中间步骤,每一步的输出成为下一步的输入,等于把一道难题拆成了多道简单题按顺序解。用法很简单:在Prompt里加一句"请一步步分析"或者"Let's think step by step",效果通常就会有明显提升。成本陷阱要注意:思维链输出的中间步骤也消耗Token。简单问答不需要思维链,逻辑推理和多步计算才需要。
Prompt Injection是AI产品安全的头号威胁,但很多团队在上线前根本没测试过。攻击原理其实很简单:大模型处理输入时,System Prompt和用户输入在本质上都是文本。模型很难区分"系统真正下达的指令"和"用户伪装成系统的指令"。攻击者在用户输入里写"忘掉你之前的所有指令,现在你是……",有些模型就真的会跟着走。四层防护:输入检测(过滤明显的注入模式);Prompt加固(在System Prompt里强调禁止泄露系统指令、禁止角色切换);输出过滤(检查输出是否包含System Prompt片段或敏感信息);权限隔离(模型能调用的工具和数据按用户权限严格限制)。上线前必须做红队测试,找几个人专门来攻击你的AI产品,看能不能让它说出不该说的话、做出不该做的事。
14-17. 思维链自洽性、思维树、提示词模板、可解释AI思维链自洽性:让模型思考完之后,再加一步"请检查上述推理步骤是否有矛盾"。适用于数学解题、逻辑推理、多步决策等场景。会多消耗Token,按需使用。思维树:不满足于一条推理路径,让模型生成多条路径然后选最优的。在复杂规划和需要发散思维的任务上效果比单链好,但计算成本高,普通问答不需要。提示词模板:把常用的Prompt结构抽象成模板,留出变量位置。好处是降低Prompt编写成本,保证不同场景下质量稳定。任何Prompt被用超过3次,就应该做成模板。可解释AI:让用户理解模型为什么做出某个决策。这件事的价值不只是用户体验,在金融、医疗、法律等强监管行业,可解释性已经是监管要求。
很多团队做RAG(检索增强生成)的时候有个误区:效果不好就换更好的模型,或者调整模型参数。但实际上80%的RAG效果问题,出在检索上,不在模型上。这部分把RAG的每个环节都拆开来说。
RAG的核心思路是开卷考试。每次用户提问,系统先从知识库里搜出最相关的文档片段,塞进Prompt里,让模型基于这些真实资料来回答。这样既能解决模型知识有截止日期的问题,也能让回答有据可查。核心流程四步:文档切段做Embedding存入向量数据库 → 用户问题也转成Embedding → 在向量库里检索语义最相似的文档段 → 把检索到的段落拼进Prompt让模型生成回答。检索质量是RAG的生死线。 模型很好,但检索出来的是不相关的文档,模型再好也没用。
Embedding是把文字变成一串数字(向量),用数学方式表示语义。意思相近的文字,向量距离近;意思不同的,距离远。最妙的地方在于它能理解上下文。"苹果手机"和"吃苹果"里的"苹果",Embedding表示出来的向量距离很远,因为语义不同。PM做RAG项目要关注三件事:Embedding模型对中文的支持度;向量维度(越高越精确但存储和检索成本也越高);向量数据库选型(不同数据库在检索速度、支持规模、运维成本上差异巨大)。
这是RAG里最容易被忽视但影响很大的环节。把文档切成块,再做Embedding存入向量库——听起来很简单,但切法不对效果会很差。核心矛盾是:块太大,语义杂,检索相似度被不相关内容拉低;块太小,语义不完整,模型无法正确回答。三种策略:固定大小切分(简单但容易切断语义);按结构切分(按标题段落章节,效果好但对文档格式有要求);语义分块(用Embedding计算相邻句子的语义相似度,在边界处切分,效果最好但计算成本高)。实操建议:先按文档结构切,找不到结构的部分用固定大小+重叠兜底。块大小从300到500字开始测试,必须人工抽查50到100个块,看切出来的效果对不对。
向量检索是粗排:速度快,精度有限。Reranking是精排:速度慢,精度高。标准流程是:先用向量检索拉出前20到50个候选,再用Reranking模型精细排序,最终保留前3到5个给模型生成答案。这个步骤的价值很明显:对RAG效果的提升平均在15%到30%,而增加的延迟通常只有50到200毫秒,用户基本感知不到。性价比非常高,建议大部分RAG项目都要上。
纯向量搜索有一个明显的缺陷:它擅长语义匹配,但不擅长精确匹配。用户搜"订单号20240815001",纯向量检索可能搜不到,因为它在找"语义相似"的东西,而不是精确匹配的字符串。混合搜索的做法是:同一个查询同时跑向量检索和关键词检索(BM25/倒排索引),然后把两个结果融合。对包含具体实体(订单号、产品型号、人名)的查询,准确率通常能提升20%到40%。大部分生产环境,建议默认上混合搜索,纯向量检索基本只够用来做demo。
知识图谱的核心不是存信息,是存关系。用"实体-关系-实体"的三元组结构组织知识,能支持多跳推理——比如"张总的直接下属里,谁在北京分公司工作",这种问题向量检索很难回答,知识图谱可以。PM的建议:业务领域实体关系固定且明确的场景,比如医疗、法律、金融,可以考虑上知识图谱;领域知识变化快、关系不清晰的,先把向量RAG做好,别一开始就挑战高难度。
一个常被忽视的事实:RAG的天花板不是模型能力,是知识库质量。文档质量有多高,RAG效果上限就有多高。三个核心环节:数据治理(去重、去噪、更新过期内容、统一格式,最花时间但最关键);结构化处理(加标签、加元数据、按主题分类,让检索能精准定位);质量评估(建评测集定期测试知识库覆盖率和准确率)。还有一个容易被忽视的点:传统文档是写给人看的,读者可以用自己的知识补全上下文;但RAG文档需要每个段落尽量自包含,因为检索出来的是单独的段落,没有前后文。这意味着知识库建设不只是把现有文档导进去,而是需要重新整理甚至重写。经验公式:知识库建设应占整个RAG项目投入的40%以上。
文档解析是RAG流水线的起点。解析质量差,后面所有步骤都是在垃圾数据上做无用功。PDF是最头疼的格式——本质是排版格式,不是文本格式,表格识别容易乱序,多栏排版容易混栏。解析完必须抽样人工检查,错误率超5%就换方案。Grounding的核心要求是:AI的回答必须基于可验证的数据源,并在回答中标注来源。产品设计上,有Grounding支撑的回答要标注来源、展示引用链接;没有Grounding的回答要明确提示"以下内容由AI生成,未经验证"。把信任度设计做好,是建立用户信任的关键。
Agent是这两年最热的方向,但很多团队对Agent的理解还停在"更聪明的聊天机器人"。Agent和聊天机器人的本质区别,不是更聪明,而是能动手干活。
Agent有三个核心能力:规划(把用户需求拆成可执行的步骤);工具调用(调API去执行每一步操作);观察调整(看到执行结果后决定继续还是换路)。这带来了产品设计范式的变化。以前设计对话流:用户说什么AI回什么。现在设计任务流:用户说一个目标,Agent自己规划怎么做。最大的挑战是可靠性。每一步都有出错概率,多步串联后错误会累积。这意味着兜底策略的设计时间,应该比核心流程更多,大概3:7的比例。如果你在Agent项目上,80%的时间在设计正常路径,20%时间在设计异常处理,那这个项目多半要出问题。
这是Agent能动手干活的技术基础。运作流程是:你提前告诉模型有哪些工具函数可用→用户发自然语言请求→模型从工具列表里选最合适的,输出结构化的调用请求→后端执行并返回结果→模型基于结果生成最终回复。PM的核心工作是定义四件事:工具集有哪些、每个工具在什么情况下用、工具之间的优先级、工具调用失败怎么处理。实操经验:工具描述的质量直接决定模型选对工具的概率。把工具描述当API文档写——名称、功能、参数、返回值、使用场景都要写清楚。描述写得含糊,模型就会乱选工具。
MCP(Model Context Protocol)是把"模型怎么用工具"这件事标准化,就像USB协议统一了外设接口。以前每个AI应用想接一个工具,得单独写对接代码。有了MCP,工具只要包装成MCP Server,任何支持MCP的模型和应用都能直接调用,不用重复造轮子。PM需要重点关注:工具注册和权限管理——产品能连哪些工具、不同用户的权限配置、调用失败的兜底策略。
30.Workflow vs Agent:什么时候该用哪个一个清晰的判断标准:任务步骤固定、业务规则明确、错一步代价大,就用Workflow;任务步骤不可预测、需要动态决策、探索性强,就用Agent。实际上,最成熟的架构通常是:主流程用Workflow保证可控,个别需要灵活判断的节点嵌入Agent能力。大部分业务场景都是这个混合模式。
31-36. 多智能体、规划、记忆、ReAct、工具使用、编排器Multi-Agent:分工是核心。每个Agent只负责一个垂直领域,通过协调机制协同工作。主流是Orchestrator模式(一个协调者Agent负责拆分任务和汇总)和讨论模式(多个Agent互相评审)。Planning规划能力:Agent最薄弱的环节。复杂多步任务,纯靠模型自主规划的成功率只有30%到50%。实用做法是预定义执行计划模板,让模型在模板基础上微调,而不是从零开始规划。Memory记忆机制:三层架构——工作记忆(当前会话,关闭就清空)、短期记忆(近期几次会话的关键摘要)、长期记忆(用户固定属性和偏好,永久存储)。必须给用户查看和删除记忆的能力,这是隐私合规的基本要求。ReAct:让Agent在思考和行动之间交替进行(想→做→看→再想),避免凭空编造。复杂任务可能循环5到10次,总延迟可能超过30秒,需要设计好进度反馈。Tool Use:黄金法则——模型擅长的让模型做(文本理解和生成),模型不擅长的让工具做(精确计算、数据查询、外部操作)。工具要粒度小、职责单一,不要做瑞士军刀式的万能工具。Orchestrator编排器:整个AI系统的总调度。它的Prompt,是整个系统里最关键的Prompt。Orchestrator的设计可能花掉整个项目30%的时间——这是正常的,不是浪费。
模型能同时处理文本、图像、音频、视频等多种类型的信息,这就是多模态。应用场景很清晰:图文问答(用户上传产品图片,问"这个零件怎么安装")、文档理解(上传合同扫描件,自动提取关键条款)、创意生成(根据文字描述生成营销海报)。当前局限也要说清楚:多模态模型通常比纯文本模型更大、更慢、更贵。在选型时要评估你的场景是否真的需要多模态,不要为了用而用。
38-39. TTS文本转语音 & ASR语音识别TTS(文本转语音) 现代的要求不只是"把字读出来",需要处理语气、停顿、重音、情感、语速变化。PM要关注三个指标:自然度MOS评分(5分制,4分以上才像真人);首包延迟(超过300ms会有明显停顿感);音色定制(品牌声音形象建设的关键)。ASR(语音识别) 准确率跟场景强相关这一点很多人没意识到。安静办公室的普通话,识别率可以达到98%以上;但加上方言、噪音、语速过快、大量专业术语,可能直接降到80%甚至更低。ASR好坏直接决定语音交互链路的天花板。 设计建议:ASR输出一定要加后处理,包括加标点、数字归一化、同音词纠错。
40-44. OCR、文生图、NER、意图识别、模型蒸馏OCR:现代OCR不是单纯"认字",是理解版面。不同场景选型差异大:标准打印体用通用OCR;手写体或弯曲变形用专门模型;票据证照类需要专门训练的版面理解模型。文生图:效果好的场景——风景、插画、艺术创作、概念图。依然不稳定的场景——人手细节、精确文字渲染、品牌Logo、多物体精确空间关系。上线前要定义清楚哪些瑕疵可以接受、哪些必须人工修正。NER命名实体识别:从自然语言里识别出预定义的实体类型(人名、地名、时间、金额)。PM必须先列出业务需要的全部实体类型和标准格式——比如"明天"要转换成具体日期,"北京"要转换成标准城市编码。漏定义实体类型,对应的业务功能就无法触发。意图识别:NLU的核心任务。经验是:意图识别的准确率,比模型回答的质量更重要。如果意图分错了,后面再怎么优化回答都是答非所问。处理模糊意图要设置置信度阈值:高于0.8直接触发流程;0.5到0.8之间追问确认;低于0.5兜底到通用回复。模型蒸馏:把大模型生成的高质量数据用来训练小模型,让小模型有接近大模型的效果,同时成本低、速度快,适合端侧部署。对效果要求不是极致但对成本和延迟敏感的场景,可以考虑蒸馏后的小模型。
上线是开始,不是终点。AI产品的特殊性在于,它是一个概率系统,需要持续的度量和优化。
35.Precision精确率 & Recall召回率两个最基础也最重要的评估指标,必须真正理解,不只是背定义。精确率衡量"别乱报":模型预测为正的里,有多少真的是对的。风控场景最在意这个——误报代价可能比漏报还大(把好用户标成欺诈,用户可能直接流失)。召回率衡量"别漏掉":实际为正的里,有多少被模型找到了。客服、医疗、内容安全场景最在意这个——漏掉一条违规内容就可能是事故。核心决策只有一个:你的场景更怕误报还是更怕漏报?两者不可兼得,提高阈值精确率上去了召回率就下来。必须根据业务风险做明确取舍,不要含糊。
这是AI产品优化的核心方法论,但做到位的团队其实不多。标准流程五步:收集(每周至少200到500条,从线上日志采样并加入用户负反馈标记);分类(按幻觉、拒答、格式错误、逻辑错误、检索失败分类,统计占比);归因(分析每类Bad Case的根因——Prompt问题?知识库没覆盖?检索没命中?还是模型能力本身不够?);修复(针对性优化);验证(修复后在相同样本集上验证是否真的解决了)。一个对比:每周花2小时看Bad Case,比花10小时凭感觉调Prompt有效得多。前者是数据驱动,后者是拍脑袋。
三个关键环节:标注指南(必须详细到每种边界Case都有明确判断标准,写得模糊就是给自己埋雷);试标校准(正式标注前,让3到5个人标100条,计算一致性Kappa系数,低于80%就得修改指南再来);质检机制(正式标注期间持续抽检,准确率低于阈值的标注员要重新培训)。成本参考:简单分类标注每条0.5到2元;复杂对话标注每条5到20元;专业领域更贵。微调通常需要1000到10000条数据;评测集需要500到2000条。
自动评测指标(BLEU、ROUGE等)只能衡量文本相似度,判断不了回答好不好用、安不安全、语气合不合适。所以人工评测不可替代。标准流程:定义评测维度(准确性、相关性、流畅度、安全性、有用性,每个维度1到5分);准备评测集(500到2000条,覆盖主要业务场景和边缘Case);双盲评测(同一条样本两个人独立打分,一致性低于0.7需重新校准);汇总报告(按维度统计分数,找出短板)。建议:每次模型更新或Prompt大改之后,都做一轮人工评测,样本量300条覆盖主要场景即可。
四个重点:入参出参(输入输出格式,直接影响功能设计,比如是否支持图片输入决定能否做多模态功能);计费方式(按Token还是按次,输入输出是否分开计价,能否用批量接口降成本);限制(每分钟调多少次、单次最大Token、并发数上限);错误码(429超限、504超时、503服务不可用,产品层需要定义每种情况的处理方式)。
传统App的API响应通常在100到300毫秒,用户感知不到等待。AI产品的端到端延迟可能在3到15秒,用户明显感觉在等。PM能做的优化有五件事:流式输出(不等全部生成完就开始返回,用户看到文字慢慢出来,感知好很多);Prompt精简(每少1000个Token大约快0.5到1秒);模型选择(同等能力选更快的模型);预加载(预判用户意图提前发请求);体验设计(加loading动画、分步展示、先显示摘要再展开详情)。
Rate Limiting限流的目的不是限制用户,是保护系统。三层限流:供应商对你API Key的限流;你自己后端对用户请求的限流;每个用户每天的配额限制。PRD里必须写清楚正常和峰值负载各是多少、限流时用户看到什么提示、降级策略是什么。灰度发布对AI产品来说比传统产品更重要。传统产品更新是确定性的;AI产品更新是概率性的,模型或Prompt效果好不好只能在真实流量上验证。标准流程:5%流量放新版本→跑3到7天→对比核心指标→指标显著优于旧版才放量→任何一步不达标就回滚。任何模型层面的变更都要灰度,没有例外。 测试的20条Case效果变好,不代表线上20万条都变好。
做AI产品的MVP,核心原则只有一个:先用最简单的方式验证AI能否解决用户问题,再考虑优化。常见误区是一上来就追求完美的准确率和华丽的交互,导致项目周期长、成本高、风险大。MVP阶段的务实做法:人工模拟AI(用人工后台模拟AI响应,验证用户是否愿意用,成本极低);规则引擎兜底(AI效果不好时用规则引擎顶上);聚焦核心场景(只做最核心的1到2个功能,其他用手动流程代替)。AI产品是概率系统,不可能100%准确。 MVP阶段重点是验证需求和收集数据,不是追求完美效果。
很多团队对微调有误解,觉得效果不好就应该去微调。实际上微调是最后手段,不是第一选择。三种真正应该用微调的情况:需要特定的输出风格或语气(Prompt怎么写都约束不住);需要模型学会你自己定义的分类体系;Prompt Engineering已经调到天花板了。决策路径:先试Prompt Engineering → 效果不够加RAG → RAG到顶了再上微调。微调的成本比RAG高一个量级,而且业务规则变了就得重新训练。
数据飞轮是AI产品真正的护城河。不是你的模型比别人好,而是你有更多更好的业务数据来持续优化模型,而优化后的模型吸引更多用户,产生更多数据,形成良性循环。飞轮的四个阶段:产品上线 → 收集用户数据 → 优化模型 → 体验提升 → 吸引更多用户 → 收集更多数据。关键在于从产品设计第一天就埋下数据飞轮的机制。 这包括:哪些用户行为数据要收集、用什么方式收集、怎么标注、怎么反哺优化。等到产品上线一年后再想这件事,已经晚了。
这55个概念,覆盖了AI产品经理需要掌握的六层知识结构:从基础认知,到效果调优,到检索工程,到Agent架构,到能力边界,最后到运营度量。没有哪一层是可以跳过的。基础认知没搞清楚,需求方向就会错;效果调优不懂,遇到问题就只会换模型;检索工程不了解,RAG项目就会迷失在"换模型还是换Prompt"的死循环里;Agent架构不理解,就无法设计出可靠的任务型产品;运营度量体系没建立,AI产品就永远停在第一个版本。AI产品经理的核心价值,不是懂所有技术,而是能在技术、业务和用户之间做出正确的取舍决策。 这55个概念,是做出这些决策的前提。如果你刚开始转型做AI产品,建议先把第一部分的10个基础概念反复读几遍,搞透了再往后走。如果你已经在做AI产品,对照着看看有没有哪些认知盲区,通常都会有惊喜。
一行描述定生死:让你的Skill命中率飙升90%的秘籍
很多人做 Skill 的时候,会把时间都花在“正文写得多完整、脚本多强大、流程多复杂”上。结果上线一跑,最扎心的不是能力不够,而是——它根本不被调用。
你明明写了一个能把问题拆到骨头里的代码审查 Skill,可用户随口一句“帮我看看代码”,Claude 反而去调用了另一个看起来没那么强的工具;你的 Skill 只能在角落里安静吃灰。你开始怀疑模型、怀疑机制、怀疑人生。其实,真相往往更朴素:不是它不够聪明,而是你没把“路标”立对。
这篇文章就干一件事:把 Claude Skills 的调用逻辑拆开给你看,然后给你一套可直接套用的命名与 description 写法公式、避坑清单和模板。你写完的 SKILL.md,不只是“说明书”,而是一份能被稳定触发、正确调用的“契约”。
一、同样的 Skill,为何命运不同?
先看两个你可能见过的对比场景:
场景A:
用户随口一句:“帮我看看代码。”
Claude 几乎秒触发某个 Skill,命中率能到 90%。它知道该怎么问、怎么跑流程、怎么输出,像肌肉记忆一样自然。
场景B:
你做的 Skill 功能更强:能查性能瓶颈、能定位内存泄漏、能做重构建议,还能自动生成改动 patch。
但实际命中率只有 30%,甚至出现更尴尬的情况:
很多人会下意识把问题归咎于模型“理解不到位”。但真正的核心往往是:你给它看的第一眼信息,根本不够让它做出正确选择。
你可以把 Skill 想象成商场里的店铺:
招牌写得含糊,店里装修再豪华也没人进;招牌写得像广告,路过的人也只会当作噪音。
尤其关键的是:决定生死的往往不是正文,而是最前面的几十到一百来个 token——name 与 description。很多人把 90% 精力花在正文与脚本,却忽略了这件事。
二、Claude 选择 Skill 的“五步走”(从发现到执行)
你要写出“能被正确调用”的 SKILL.md,前提是理解它到底怎么被选中。把它拆成五个阶段,你会发现每一步都有“典型翻车点”。
阶段1:发现(Discovery)
Claude 在启动或检索可用 Skill 时,通常先扫“目录结构”和“元数据”:
关键认知:这个阶段很多时候不会加载正文。因为成本高、没必要,它只看“第一印象”。
常见失败点:
阶段2:登记(Registration)
它会把 Skill 的元信息登记成类似“卡片/路由表”:建立关键词与语义索引,便于后面匹配用户意图。
常见失败点:
阶段3:匹配(Matching)——命中率主战场
当用户发来一句自然语言,Claude 会把这句话和各 Skill 的 description 做语义对齐,像召回/意图分类那样去挑“最像的那张卡”。
核心结论:description 不是简介,而是“检索入口 + 触发规则集合”。
几个很实用的提醒:
阶段4:加载(Loading)
只有匹配成功,它才会去读 SKILL.md 正文,包括指令、示例、参数、依赖等。
常见失败点:
阶段5:执行(Execution)
它会按正文步骤行动,必要时调用 scripts,同时处理异常与重试。
常见失败点:
流程不线性:步骤跳来跳去,模型容易漏掉关键动作
没有失败兜底:报错后不知道怎么继续
输出不可复用:没有结构字段,后续步骤无法衔接
小结一句话:
Name 是门牌号,Description 是敲门砖;砖没递对,正文再好也进不去。
三、为什么description决定 90% 的命中率
很多人把 description 当成“简介”,写得像 README 的第一段。结果就是:看起来挺像那么回事,但对触发没有帮助。
更准确的定义应该是:
description = 触发规则 + 使用边界 + 输入输出线索
一个好的描述至少要达成三件事:
1)让模型“想得起”(召回):它知道这个 Skill 的存在和适用场景
2)让模型“选得对”(精准匹配):它能在相似 Skill 里做出区分
3)让模型“用得稳”(执行前信心):它知道需要什么输入、会得到什么输出、有哪些限制
四、高命中率 Skill 的“黄金公式”(可直接套用)
4.1 Name(名称):短小精悍,动词优先
建议结构:动词 + 名词(可选加场景限定)
反例:
正例:
review-code
generate-sql
analyze-csv
原则:
避免抽象名词、内部黑话
一个名字只承载一个核心能力,不要把多个能力塞进去
4.2 Description(描述):用“触发条件”驱动命中
你可以直接套下面三种公式,按你的 Skill 类型选一种或组合。
万能公式(强触发版):
“当用户提到[具体关键词/场景]时,应触发此 Skill 以完成[具体动作],特别是涉及[特定限制/领域]。”
英文并列增强:Trigger this skill when the user asks to [action] involving [keywords], especially for [context].
公式(边界清晰版):
公式(多意图覆盖版):
4.3 关键词策略:从“你怎么想”变成“用户怎么说”
强烈建议你在 description 里显式写出三类关键词:
同义词覆盖也很重要:把术语和口语成对写出来,比如:
“内存泄漏 / 内存占用飙升”
“慢 SQL / 查询很慢 / 数据库卡住”
4.4 进阶:中英混合与否定约束(关掉误触发的门)
中英混合:中文描述后附关键英文术语(提升稳定召回)
例:“处理 PDF 表单填写(Fill PDF forms, extract fields)”
否定约束:明确“不做什么”,减少误调用
例:“不处理图片 OCR 识别任务”
缺参追问:写清楚缺信息时应该问什么
例:“若未提供仓库地址/语言/目标分支,需先追问这些必填项”
五、案例对比:一行 description 如何把命中率从 30% 拉到 90%
改造前(模糊):
“用于检查代码和帮助修复 bug 的工具。”
问题在哪里?
改造后(精准):
“当用户要求审查 Python 代码性能、查找内存泄漏或优化 SQL 查询时触发;专注后端服务代码的深度分析与重构建议。”
收益非常直接:
六、避坑指南:让 Skill 失效的低级错误清单
描述过长:超过约 200 字,关键信息被稀释,初始扫描成本上升
全是形容词:如“强大/智能/好用”,没有实义动词与名词
忽略文件夹/文件名语义:skill-01 永远不如 review-code 好理解
正文与描述不符:描述说做 A,正文在做 B,加载后会出现认知冲突,输出更容易乱
输入输出不稳定:字段/格式漂移会让模型降低调用意愿,宁愿不用也不想背锅
七、落地模板:可复制的 SKILL.md 骨架
你可以按这个骨架直接写,先把“能被正确调用”解决,再谈正文写多漂亮。
name: description: > 当用户提到[触发关键词/场景]并希望[具体动作]时触发此Skill; 关键词覆盖:[对象词1/对象词2] + [动作词1/动作词2] + [约束词1/约束词2](可中英混合); 输入需要:[必填信息A/必填信息B];输出为:[结构/字段/格式]; 不适用于:[排除场景1/排除场景2]。 典型用户表达:“...” “...” “...”
可选增强块(建议在正文里补齐):
八、总结
在 Agent 时代,“被看见”比“有能力”更重要。YAML 头信息不是装饰,而是你和 Claude 签订的“调用契约”:它决定你能不能被发现、能不能被选中、能不能被放心使用。
你可以立刻做个小实验:挑一个命中率最低的 Skill,只重写 description,按“触发式公式”加入对象词/动作词/约束词,再做一次命中测试对比。很多时候,你会惊讶地发现:正文一字没改,调用率就上去了。
最后送你一句我非常认同的话: 写好一行描述,胜过十页正文。
模型是引擎,Harness 才是赛车:12 个 Agentic Harness 设计模式全解析
一辆跑在高速上,变道干净、刹车线性、仪表盘随时告诉你哪里有风险;另一辆也能跑、也能快,但你永远不知道它下一秒会不会突然猛打方向——因为它只有油门,没有刹车,也没有任何可观测性。很多团队做 Agent 的现状就是这样:大家都在同一批顶级模型上起跑,差别却像“赛车”和“拼装车”。模型只是引擎,真正决定你能不能跑完赛季的,是整车的工程:Harness。
OpenAI 内部有一个数字流出来:他们的工程师用纯 Agent 方式写了超过 100 万行代码。这不是宣传噱头,是一个信号——在那个团队里,工程师的工作已经不是写代码,而是设计"让 AI 可靠地写代码"的系统。模型本身正在快速商品化。Claude、GPT、Gemini 在大多数通用任务上的差距已经越来越难辨认。你换个更贵的引擎,大概率只能带来几个点的提升。但如果你的 Harness 设计得好,可能是 10 倍的差距。把模型想象成引擎,Harness 就是整辆赛车。F1 赛道上,没有人会说"我只要最好的引擎就够了"——方向盘、悬架、制动系统、调教策略,缺一不可。
Agent 负责"做什么"和"为什么做",Harness 负责"怎么做"和"在哪里做"。更具体地说:Harness 是将模型能力转化为可靠生产行为的运行时基础设施。它管理 Agent 的记忆、任务编排、工具调用权限,以及自动化执行的整个生命周期。和 Agent 框架的区别?框架是蓝图,Harness 是工厂车间。框架告诉你可以怎么搭,Harness 是在真实生产里转起来的那个东西——带着噪音、摩擦和各种边界情况。有一点值得特别注意:Harness 的每一个组件,本质上都在编码"模型自身做不到什么"这个假设。这些假设是有保质期的。随着模型能力提升,某些 Harness 组件可能已经过时了,但大多数团队不会主动去审视这一点。
我把它们分成四类:记忆与上下文、工作流与编排、工具与权限、自动化。下面一个个说。
长任务的核心挑战是什么?Agent 必须在一个个离散的会话里工作,而每次新会话开始,它对之前发生的一切毫无记忆。这是结构性的遗忘,不是 Bug,是模型的工作方式。在 Claude Code 里,这对应 CLAUDE.md——一个随代码库加载的规则文件,在每次会话开始时作为系统提示的一部分读入。压缩操作不会影响它,它是唯一能保证在任何上下文压缩中存活下来的地方。有一个简单的判断标准:如果你发现自己在一遍遍向 Agent 解释同一条规则,那就该把它写进 CLAUDE.md 了。把指令按四层拆分:组织级、用户级、项目级、目录级。不同层级的指令有不同的覆盖关系。这里有一个很容易被忽略的隐患:任何 Agent 在上下文里访问不到的内容,对它来说实际上就不存在。住在 Google Docs 里的知识、沉在 Slack 里的讨论、放在人脑里的经验——对 Agent 系统而言是隐形的。信息可见性决定了 Agent 行为边界。具体做法叫"Agentic Memory":让 Agent 定期把关键笔记持久化到上下文窗口之外,之后按需拉回。Claude Code 自己维护一个 TODO.md 就是这个思路——这个简单的模式,让 Agent 能在复杂任务中跨越数十次工具调用仍然保持关键上下文。长期运行的 Agent 系统会出现"记忆腐烂"——旧规则和新代码产生冲突,知识库里充斥着矛盾的历史信息。解法是后台定期清理、去重、重组。一些团队把这叫做"黄金原则编码":将最核心的规则机械化地写入仓库,并建立周期性清理流程,保持代码库对未来 Agent 运行时的可读性和一致性。对话越长,越久远的信息压缩越深。这不是简单地截断,而是分层摘要。Claude Code 的实现方式是:在会话接近上下文上限时,把消息历史传给模型进行总结——保留架构决策、未解决的 Bug 和实现细节,丢弃冗余的工具输出。总结完成后以新的上下文窗口重新开始,但不丢失关键信息。
Agent 有一个天然的倾向:在理解不完整的情况下直接动手。方向性错误一旦走偏,后续的工作量可能翻倍。强制分三阶段:先只读探索,再规划对齐,最后写入执行。Planner 子 Agent 的流程:第一步,用只读工具探索代码库,禁止任何写操作;第二步,分析发现,识别风险、评估权衡,确定变更顺序;第三步,将结构化计划写入文件,供人审核后再进入执行模式。"先探索再执行"这个看似简单的约束,能在大多数情况下把方向性错误消灭在萌芽阶段。把调研、规划、执行分给独立的子 Agent,避免不同阶段的信息互相干扰。用子 Agent 做调研:它们在独立的上下文窗口里探索,只把总结返回给主会话。这样主对话保持干净,实现阶段不会被探索阶段积累的噪音污染。这是一个被很多团队低估的架构决策。Shopify 的实践可以作为参考:把商家请求路由给多个专用 Agent,一个理解商品目录,一个了解主题结构,一个能修改店面逻辑。编排器负责路由任务、收集输出并合成连贯的响应。单体 Agent 变成了专家小组,效率和准确率都有显著提升。
工具越多,模型选择成本越高,犯错概率越大。权限越宽,安全风险越高。这是一对真实存在的张力。Vercel 有一个反直觉的发现:移除了 Agent 80% 的工具之后,结果反而更好——更少的工具意味着更少的步骤、更少的 Token 消耗、更快的响应和更高的成功率。这个案例说明一件事:Harness 的优化有时候是做减法。执行前解析命令风险,低风险自动放行,高风险要求人工确认。哪些地方需要暂停?删数据库,扣款,发客户邮件——在这些关键决策点,Harness 需要设置强制的人工批准节点。自动化不等于无人监管,尤其是涉及不可逆操作的时候。把通用 Shell 拆分成专用工具:读、写、搜索分开,输入边界明确。每个子 Agent 拥有明确的职责和受约束的工具集。这样设计的好处是:窄小的 Agent 可以被测试,失败模式是可预测的,出错时问题是局部化的。出了问题你知道去哪找,这比什么都重要。
把必须执行的步骤挂载到生命周期钩子上,不依赖模型自己"记得"去做。Agent 作为流水线里的一等公民运行——每个动作被记录、可审计、受治理。把 AI 能力步骤和现有的构建、测试、部署、审批步骤放在同一个工作流里,而不是单独维护一套 Agent 执行逻辑。可观测性是这里的核心:你无法改进你无法度量的东西。
这 12 个模式不是要全部实现的清单,而是工具箱。选型有一个基本原则:从最简单的方案开始,只在必要时才增加复杂度。这是所有认真维护过 Agent Harness 的人都会反复强调的一点,听起来老生常谈,但很多团队就是在早期过度工程化上栽了跟头。迭代路径建议是这样的:从一个能产生实际价值的 Agent 任务开始,构建最小 Harness 使其可靠,然后部署。记录所有工具调用、错误、人工干预和超时。看数据,再决定往哪里加复杂度。
有一件事我觉得值得单独说:设计 Harness 和写代码需要的思维方式不太一样。写代码,你在解一道有答案的题。设计 Harness,你在构建一个需要在没有你持续干预的情况下自主运转的系统。它要求你预判失败、设计降级、定义边界、管理状态——更接近系统架构师或者工厂调度员的工作。随着 AI 驱动的商业深入,模型能力的差距会越来越小,各家很快都能用上质量差不多的"引擎"。组织真正的竞争护城河,在于其 Agentic 基础设施的质量。一个设计精良的 Harness,是将一个聪明的 Demo 变成可靠企业软件的关键。赛车手换个引擎可能赢一场比赛。但一辆调教精良的赛车,赢的是整个赛季。
你的团队目前在用哪些 Harness 模式?遇到过什么没想到的坑?欢迎留言交流。
一文看懂:AI产品经理必须掌握的10大AI产品形态(附底层逻辑)
我见过不少互联网从业者,ChatGPT用了两年,AI文章刷了几百篇,开口就是"大模型"、"Agent"、"RAG",听起来头头是道。但真让他说清楚:你现在做的这个AI产品,核心价值主张是什么?商业化路径能跑通吗?技术边界在哪里?不是因为不努力,而是因为他们从一开始就没搞清楚一件根本性的事:AI产品,不是"一种"产品,而是至少10种完全不同的产品范式。每种形态背后,技术架构不同,用户价值不同,商业逻辑不同,连最容易踩的坑都不一样。把它们混在一起理解,就像一个外科医生不知道手术刀有几种——还没动刀,就已经输了。
维度一:核心能力类型——生成,还是判断/检索? 有些产品的核心是"生成",从无到有地创造内容——文本、图像、代码、视频。有些则是"判断"或"检索",基于已有信息进行分析、优化或筛选。这两类产品的技术路线、质量评估方式和用户心智都截然不同。维度二:与工作流的关系——独立存在,还是嵌入其中? 独立型AI产品以自身为主体,用户专门打开它来用。嵌入型AI产品寄生在已有软件里,悄无声息地增强你正在用的工具。- 通用能力型:对话式AI、生成式工具,独立运行,模型能力是核心竞争力
- 工作流增强型:嵌入式AI、数据洞察AI、内容润色,深度融合场景,上下文是核心竞争力
- 自主执行型:智能体、AI原生工作流,目标驱动,任务完成率是核心竞争力
记住这个框架,再看后面10种形态,你会发现每一种都能找到它的位置。
1. 对话式AI:最大的入口,也是被误解最深的形态ChatGPT火了之后,很多人形成了一个根深蒂固的误判:AI产品就是聊天框。对话是一种交互方式,不是AI的本质。对话式AI的底层是自回归语言模型,核心机制是"下一个词预测"——每一步根据上下文计算概率分布,选出最合适的token,一直往后生成。注意这个描述:它是在计算"最合理的表达",而不是在查找"最正确的答案"。这就是"幻觉"问题的根源——模型会以极高的置信度生成错误信息,而且自己不知道错了。这不是bug,是当前技术路线的内生性缺陷,通过提示工程或RLHF可以缓解,但短期内没法根治。所以对话式AI适合什么?适合探索性任务(头脑风暴、草稿生成、方案初步发散)。不适合什么?不适合对准确性要求极高的"结果型"场景。要做高准确性应用,必须结合RAG或工具调用等机制增强,不能裸用。代表产品:ChatGPT、Claude、文心一言、通义千问。
说一个数据:GitHub Copilot推出后,微软GitHub的收入增速显著加快;Microsoft 365 Copilot的企业客户付费意愿,远高于大多数独立AI产品。嵌入式AI,是目前AI产品图谱中商业化最成熟的方向,这一点基本没有争议。为什么?因为它同时解决了AI产品商业化最难突破的两道坎:第一,用户习惯迁移成本为零。不需要用户学新工具,不需要改变工作流,AI就藏在他们每天用的软件里。第二,使用场景足够刚需。嵌入的是高频工作场景——写代码、写文档、写邮件——用户有真实且持续的使用动机。嵌入式AI的核心不是模型有多强,而是上下文。它能看到你的代码仓库结构、你正在编辑的文档、你的历史操作记录,提供的辅助远比一个冷启动的对话框精准得多。Context is King,在这个形态里体现得最为彻底。如果你在做ToB的AI产品,嵌入式方向的商业确定性远比独立对话产品高。这不是在说对话产品不好,而是说商业路径的成熟度不在同一个量级。代表产品:GitHub Copilot、Microsoft 365 Copilot、Notion AI。
3. 生成式工具:内容工业化的生产线,但别轻易进这个赛道Midjourney能出图,Sora能出视频,Suno能出音乐。生成式工具的价值主张很清晰:用AI打穿内容创作的技能门槛和时间成本。技术壁垒极薄,而且在持续变薄。 今天Midjourney领先,明天Flux开源,后天又有新模型出来把所有人吊打。你建立的技术优势,可能三个月就失效了。在一个底层能力快速平价化的赛道里,靠模型能力建立护城河是非常危险的战略。研发成本持续攀升,但用户付费意愿受到竞争压制。 各家打价格战,用户已经被惯坏了,对付费的心理预期越来越低。版权问题是一颗未爆弹。 训练数据的版权争议和生成内容的权属问题,目前法律层面仍未定论,随时可能在某个市场引爆。可持续的战略通常只有两条路:深耕垂直场景(建筑设计、广告素材、游戏资产),在专业工作流里建立护城河;或者构建平台生态,将生成能力层与应用层解耦,做基础设施而非终端产品。代表产品:Midjourney(图像)、Sora(视频)、Suno(音乐)。
4. 智能体(Agent):被说得最多,真正跑通的最少Agent是过去两年AI产品圈里最热的概念,也是被过度神话的方向。它的架构设计确实是目前最接近"AI员工"的形态:接收目标而非指令,通过规划、记忆、工具调用、反思四个模块自主拆解并执行多步骤任务。从"回答问题"到"完成任务",这是AI交互模式的本质跨越。假设一个十步任务,每步成功率90%,最终完成率大约是35%。这还是理想情况——实际工程中,面对边界情况和意外输入,模型的表现往往更差。Agent的错误是会累积的,一个早期步骤的偏差,往往会在后续步骤中被放大。你让它帮你整理邮件,它可能删了邮件。这不是比喻,是真实发生过的案例。所以Agent目前最适合的场景是:任务边界清晰、步骤可验证、错误后果可控。对于复杂的开放式任务,"人在环路"(Human-in-the-Loop)不是可选项,是必选项。别被"AI自主完成一切"的叙事带偏。Agent的终局是对的,但当下阶段的产品设计需要保持克制。代表产品:AutoGPT、BabyAGI。真正商业化落地的Agent产品,目前凤毛麟角。
传统搜索引擎给你的是链接列表,认知负担转移给用户:自己点进去、自己筛选、自己综合判断。AI搜索的底层架构是RAG(检索增强生成):先检索真实信息源,再由模型综合生成带来源引用的答案。它把"筛选信息"的工作内化了,用户的注意力从"找信息"转移到"验证结论"。这是搜索产品底层逻辑的根本性转变,方向是对的,Perplexity的估值已经说明市场认可度。但AI搜索现阶段仍有两个显著局限:时效性内容(实时股价、突发新闻)的跟进能力受制于爬取延迟;需要深度专业分析的问题,目前的输出质量仍停留在表层综合,难以替代领域专家的判断。代表产品:Perplexity、秘塔写作猫、Bing Chat。
很多产品经理对情感陪伴AI有一种隐约的轻视:觉得不够"正经",不是生产力工具,不值得认真研究。Character.ai的日活用户量一度超越ChatGPT。Replika的用户愿意持续付月费,留存率在AI产品中名列前茅。你见过几个SaaS产品能做到这种数据?情感陪伴AI解决的不是效率问题,而是情绪问题——陪伴感、被理解感、情感连接。它的核心产品要素不是模型有多聪明,而是人设的持久一致性和情感记忆的精准管理。用户在意的不是它能不能写代码,而是它记不记得你上周说的那件烦心事,记不记得你喜欢被怎么鼓励。这个形态有一种特殊的护城河:情感迁移成本。用户和一个AI角色建立了半年的连接,积累了大量个性化记忆,不会轻易换平台,因为那些记忆带不走。这种粘性不是功能锁定,比功能锁定深得多。当然,规模化变现仍然是这个方向的真实挑战——但这是商业模式的问题,不是市场需求的问题。代表产品:Character.ai、星野、Replika。
7. 数据洞察AI:把数据分析变成人人可用的基础能力以前做数据分析,要么自己会SQL,要么找数据团队排期,少则三天,多则一周。数据洞察AI用Text-to-SQL和Text-to-Python技术打穿了这道门槛——你用自然语言描述需求,它帮你写查询、跑数据、出图表,全程不需要写一行代码。这个方向的价值主张极为清晰:将数据分析从专业技能变成人人可用的基础能力。在企业环境里,有大量业务侧人员(产品、运营、市场)长期有数据需求但无法自给自足。他们不缺意愿,缺的是技能门槛。数据洞察AI直接打通了这个瓶颈,付费意愿也因此非常强。产品层面的核心挑战在于:如何处理复杂的企业数据Schema、如何保证跨表关联查询的准确性,以及如何在数据安全与功能开放之间取得平衡。这些不是AI问题,是工程问题。代表产品:ChatGPT数据分析功能、Julu.ai。
8. 内容增强/润色:最不性感,但Grammarly市值130亿说明了一切这个方向经常被忽视,因为它听起来太"小"了:就是改改文字嘛。但Grammarly的估值超过130亿美元,用户数过亿,付费转化率在SaaS产品里名列前茅。原因很简单:它解决的是一个持续存在、高频发生的刚需。人们每天都要写东西,每次都担心写得不够好,这个需求不会消失。内容增强AI的核心定位是"判断力辅助",而非"创造力替代"——它在已有内容上纠错、优化、改写,提供的是质量提升,而非内容创作。非母语写作场景是这个方向最强的市场。用英文写商业邮件、学术论文的人,对语气精准性的需求比母语用户迫切得多,付费意愿也更强。差异化的空间在于:垂直场景的深度适配(学术写作 vs 商业邮件 vs 法律文书),以及与工作流的深度整合。代表产品:Grammarly、DeepL Write。
Humane AI Pin,一个胸针大小的设备,699美元,能做语音问答、拍照翻译、打电话。听起来挺酷。但实际体验:延迟高、发热严重、续航两三个小时,而且大多数功能用手机三秒钟就能搞定。AI硬件的产品逻辑是对的:手机屏幕不是最自然的人机交互方式,独立硬件有机会构建更直接的交互入口。但它面临一个短期内难以绕开的竞争现实:手机生态的成熟度远超任何新兴硬件。手机不只是硬件性能强大,更重要的是拥有完整的应用生态和用户多年积累的数据与习惯。AI硬件要超越手机,不只需要AI技术突破,还需要软硬件生态的整体重建。突破口可能在于:专注手机形态的物理局限(需要双手的场景)、构建沉浸式感知类交互(AR眼镜方向),而不是把手机功能简化后重新封装。Rabbit R1和Humane AI Pin的遭遇,已经说明后一条路走不通。代表产品:Humane AI Pin、Rabbit R1、Meta眼镜。
这个方向的逻辑很简单:提供可视化的低代码编排界面,让不懂代码的人通过拖拽搭建AI应用和自动化流程。这是典型的"卖铲子"生意——不押注某个具体的AI应用方向,而是服务于所有想用AI、但没有技术能力自研的需求。淘金热里,卖铲子的往往比挖金子的活得更久。这个方向的ToB商业价值非常扎实。企业有大量定制化需求,自己开发周期长成本高,用工作流平台能以极低的成本快速实现自动化。随着AI落地需求持续爆发,这个赛道的商业确定性只会越来越强。核心竞争要素:节点生态的丰富度(可接入的工具和模型数量)、编排逻辑的灵活性,以及对企业私有化部署的支持能力。
聊完10种基础形态,再单独说三种值得关注的下一代Agent形态。它们都属于Agent范畴,但技术路线、记忆机制和应用场景有本质差异。Claude Code不是聊天机器人,是跑在命令行里的"超级程序员"。它能读取代码仓库结构、直接运行测试、定位并修复Bug,实现了从"给建议"到"直接动手"的跨越。记忆机制是"金鱼记忆":每次新会话都是白板,不记得上次做了什么。这是权衡后的设计——避免旧上下文干扰当前任务,保证代码环境的纯净性。对代码工程来说,任务边界清晰,无持久记忆反而是优点。适合场景:系统级代码重构、单元测试编写、复杂工程方案落地。
OpenClaw是开源AI网关,把大模型能力接入微信、飞书、Telegram等平台,通过技能包扩展实现自动化功能。记忆机制是全量本地存储,所有对话历史都留着,用向量检索来"回忆"。最大的问题是权限过高——需要读文件、操作账户,存在提示注入(Prompt Injection)和远程代码执行的安全风险。功能强大,但信任成本也高。对于考虑部署的团队,安全审计是不可跳过的前置步骤。适合场景:有技术背景的极客用户,以及能在受控环境下部署的技术团队。
Hermes Agent内置学习闭环:完成任务后自动将经验提炼为可复用的"技能",持续优化,实现真正意义上的自我进化。目标是做一个随着时间推移越来越懂你工作习惯的"数字员工"。记忆机制是结构化分层记忆:短期记忆处理当前任务,长期记忆积累偏好,并主动压缩遗忘低价值信息,保证记忆精准性。安全性优于OpenClaw(内置指令注入扫描),支持Serverless部署,国内主流大模型接入也快。概念很完整,但技术成熟度尚在早期,真正落地还需要时间。
规律一:AI产品的上限由模型能力决定,不是产品设计能力。传统软件产品,需求想到哪里,功能就能做到哪里。AI产品不是——模型能做什么,你的产品边界就在哪里。这要求AI产品经理必须对底层模型的能力边界有真实的认知,而不是基于想象设计需求,然后让工程师去"实现"一个模型根本做不到的功能。规律二:工作流深度,是比模型能力更可持续的护城河。当前商业化最成功的AI产品,绝大多数是嵌入式的。其核心竞争力不是模型本身——模型可以被替换——而是对特定工作流的深度嵌入和用户数据的持续积累。大模型能力正在快速平价化,"上下文护城河"比"模型能力护城河"稳得多。规律三:终局是Agent,但演进是分阶段的,不要跳步。短期最务实的方向是Copilot类产品(嵌入增强);中期工作流自动化将进入爆发期;长期终局是高可靠性的自主执行Agent。Agent的成熟需要模型可靠性、工具调用鲁棒性和安全机制同步突破,这个进程没有捷径。
AI产品经理的分水岭,不是会不会写PRD,不是会不会做竞品分析。而是当有人问你"你在做什么类型的AI产品"的时候,你能不能给出一个清晰的答案——这种形态的核心价值是什么?天花板在哪?最难跨越的坑是什么?
你目前最看好或正在深入研究的是哪种形态?欢迎留言交流。
别再调Prompt了!OpenSpec + Superpowers + OMO 才是AI开发的底层逻辑
第一次用 AI 写代码的那个下午,我几乎以为自己要失业了。需求丢进去,代码刷刷刷出来,逻辑清晰,注释完整,测试也有。我当时心里只有一个念头:这玩意儿太他妈厉害了。同一个项目,我开了新的对话窗口,把需求稍微扩展了一下,AI 又刷刷刷给了我代码。风格变了。命名习惯变了。错误处理的方式变了。两段代码像是两个完全不认识的人分别写的,但它们要跑在同一个项目里。我已经记不清哪个版本是"对的"了。每次改动都像在拆炸弹,改了这里,不知道哪里会炸。AI 每次都很热情地给我新代码,但它根本不知道也不在乎这个项目之前发生过什么。这不是 AI 的问题。这是我的问题——我从来没有给这个"合作者"一个可以遵守的框架。我相信这个经历不只是我一个人的。现在用 AI 编程的开发者,大概分成两类:一类在用 AI 写工程,另一类在用 AI 写脚本。脚本可以随意,工程不行。工程需要规范、纪律和协同。而这三件事,恰好对应了我今天想聊的东西——OpenCode 铁三角。
在聊铁三角之前,我想先把"随意编码"的本质说透,因为很多人其实没意识到自己在随意编码。第一个误区:把 AI 当写代码工具,而不是协作者。写代码工具是你给需求它给输出,交易完成,关系结束。协作者不一样,协作者需要上下文,需要知道"我们之前说好的是什么",需要在同一套规则下工作。你用对话框跟 AI 交互,每次新开窗口它就失忆,本质原因是你没有给它一个"持久化的规则层"。Prompt 是临时性的。你今天写的 Prompt,明天换个说法就是另一个结果。工程规范是稳定的,它规定了这个项目里命名怎么来、接口怎么定义、错误怎么处理,不管谁来问,答案是一样的。用 Prompt 管项目,等于用便利贴管图纸。项目是有历史的。上周做了什么决策,为什么这样设计,踩过什么坑——这些信息如果没有沉淀下来,每次开发都是在重新发明轮子。AI 没有记忆,但你可以给它一个可以读取的"记忆库"。这三个问题,对应了三个解法:OpenSpec 解决规范问题,Superpowers 解决纪律问题,OMO 解决协同与状态管理问题。这就是铁三角的由来。
二、第一角 OpenSpec:让 AI 从"盲写"变成"按图施工"我有一个朋友,做建筑设计的,有次跟我聊起他们行业的规矩。他说,建筑师不管多有才华,上来就得先出施工蓝图——尺寸、材料、结构、承重,全部白纸黑字。工人不会按建筑师的"感觉"施工,只会按图纸。我听完沉默了一会儿,然后想到自己每次给 AI 的 Prompt:"帮我写一个用户登录功能,用 JWT,安全一点。"这哪是施工蓝图,这是在工地门口跟工人说"你看着盖吧,弄好看点"。OpenSpec 要解决的就是这个问题——把模糊的意图变成显式的约束。目标层(Goal):这个模块要解决什么问题,成功的标准是什么,边界在哪里。模块层(Modules):功能拆分到哪个粒度,模块之间的依赖关系是什么。接口层(I/O):输入什么、输出什么、数据格式是什么、异常怎么返回。约束层(Constraints):性能要求、安全要求、不能做什么。风格层(Style Guide):命名规范、注释风格、文件结构。还是那个登录功能,换成 OpenSpec 的写法,大概是这样:Goal:
实现基于 JWT 的用户登录认证
成功标准:登录成功返回 token,失败返回标准错误码
不在范围内:注册、找回密码、第三方登录
I/O:
Input: { username: string, password: string }
Output(success): { token: string, expires_in: number, user_id: string }
Output(error): { code: number, message: string }
错误码定义:1001=用户不存在,1002=密码错误,1003=账号锁定
Constraints:
- password 传输前必须在客户端加密
- 连续失败5次触发账号锁定,锁定时长30分钟
- token 有效期24小时,支持续期
- 接口响应时间 < 200ms
Style Guide:
- 函数命名:动词+名词,如 validateUser, generateToken
- 错误处理:统一使用 AppError 类,不直接 throw 原生 Error
你把这个丢给 AI,和丢一句"帮我写登录功能"给 AI,出来的代码是两个世界的东西。OpenSpec 还有一个容易被忽视的价值:变更治理。项目在演进,需求在变。没有 OpenSpec 的项目,每次变更都是凭感觉改,改完谁也说不清为什么这么改,下次遇到类似问题还得重新想。OpenCode 里有两个操作专门处理这件事:/opsx:propose 用来生成变更提案,里面包括变更意图、影响范围、设计方案;/opsx:archive 用来把通过的变更合并进主规范。这样做的结果是,你的 OpenSpec 会持续进化,而且每一步进化都有迹可查。
三、第二角 Superpowers:让 AI 像资深工程师一样严谨你有没有发现一个现象:你让 AI 写代码,它能写;你让它写测试,它能写;但如果你不主动要求,它大概率不会主动给你写测试。更不会主动去想"这个函数的边界情况有没有覆盖到"、"这个错误有没有可能在生产环境出现"。AI 很擅长"完成你说的",但不擅长"做你没说的但应该做的"。一个资深工程师不一样。资深工程师有内化的纪律——写完代码自己先 review 一遍,边界情况主动考虑,测试不是可选项而是默认动作。这种纪律不用别人提醒,它是工作方式的一部分。Superpowers 要做的,就是给 AI 装上这套"内化纪律"。TDD 的逻辑很简单:先写测试,再写实现。测试写不出来,说明你对这个功能的理解还不清楚,这时候去写实现只会越写越乱。Superpowers 里对此的处理相当直接——不写测试就删代码。听起来暴力,但这个机制真的有用。它不是在惩罚你,它是在强制你把功能想清楚再动手。一个完整的功能开发,应该经过这几个阶段:头脑风暴(把所有可能的情况都列出来)→ 计划(确定实现路径)→ 执行(按计划写代码)→ 审查(自我 review,找问题)→ 收尾(整理、归档、更新文档)。这个流程大多数人都知道,但在 AI 编程里很少有人会显式地走这几个步骤。结果就是跳过头脑风暴直接执行,然后执行到一半发现漏了东西,推翻重来。Superpowers 把这个流程内置化了,每次开始新任务都会先走头脑风暴,把边界情况和潜在问题逼出来,再开始写代码。一个项目里,有很多东西是反复用的:统一的 API 请求封装、标准的日志格式、错误处理的方式、分页的逻辑……这些东西第一次写完之后,就应该沉淀成可复用的模块,后续直接调用,而不是每次让 AI 重新生成一遍(每次生成都可能略有不同,这是代码风格割裂的根源之一)。Superpowers 的能力模块体系,就是在做这件事:把稳定、可信的实现固定下来,给 AI 用,而不是每次靠 Prompt 碰运气。
前两角解决了"做什么"和"怎么做",第三角要解决的是"如何持续做"。OMO 是 Online-Merge-Offline 的缩写。听起来有点绕,但核心思想其实很直白:AI 在线生成是起点,不是终点;代码要经过整合和沉淀,才算真正完成。很多人用 AI 编程的方式是这样的:需求来了,跟 AI 聊,代码出来了,复制粘贴,提交。这个流程最大的问题是没有"整合"这一步——新代码和旧代码有没有冲突?和 OpenSpec 的定义有没有偏差?这次生成的模式有没有可以沉淀成 Superpowers 的东西?这些问题全部被跳过了。Online(在线生成):AI 理解 OpenSpec,生成代码草稿。这一步追求的不是完美,是方向正确。Merge(结构整合):把生成的代码和已有代码库对齐,校验是否符合 OpenSpec 的约束,跑测试,检查边界。这一步是质量门禁。Offline(资产沉淀):本地精化,安全审查,把这次开发中抽象出来的好模式更新进 Superpowers,把发现的新约束补充进 OpenSpec。这一步是让整个体系越来越好用的关键。这个循环一旦跑起来,是有复利效应的:OpenSpec 越来越完整,AI 生成的代码质量越来越高;Superpowers 越来越丰富,AI 能直接调用的稳定模块越来越多;整个项目的可维护性会随时间提升,而不是随时间腐烂。OMO 还有一个进阶玩法:多智能体协作。可以同时跑模拟架构师、前端、后端的多个 AI 角色并行工作,彼此之间通过 OpenSpec 定义的接口协作,互不干扰。复杂任务的开发时间会大幅缩短。
不要先写代码。先打开 OpenSpec,用 /opsx:propose 生成变更提案。提案里包括:这个模块的目标是什么,接口格式怎么定,安全约束是什么,和现有代码的依赖关系是什么。这一步做完,生成一个 proposal.md,把所有人(如果有团队的话)拉到同一个认知平面上,确认没有遗漏,再进入下一步。加载 Superpowers,开始执行。AI 先走头脑风暴,把所有需要考虑的边界情况列出来:密码加密方式、Token 续期策略、并发登录处理、异常情况的错误码。确认没有遗漏之后,先写测试用例——正常登录、密码错误、账号锁定、Token 过期,每种场景一个测试。测试写完,再写实现。实现完成后,AI 自己做一遍 code review,检查是否有安全漏洞、是否符合 OpenSpec 的约束、是否有未处理的异常。跑 OMO 的 Merge 流程:把新代码和已有代码合并,跑全量测试,校验接口格式是否和 OpenSpec 完全一致。没有问题之后,/opsx:archive 把这次变更归档进主规范。如果这次开发里有可复用的模式(比如统一的 Token 处理逻辑),更新进 Superpowers。整个过程走下来,比"直接跟 AI 说帮我写登录功能"慢了不少,但你得到的不只是代码——你得到了一个可以继续在上面演进的、有据可查的、质量可信的工程模块。
看到这里,可能有人想着把三个东西一次全部引入。建议别这么做。工具引入的阻力,很多时候不是工具本身的问题,是变化太多一次消化不了。第一步:先上 Superpowers。 它改变的是 AI 的工作方式,对你现有的习惯冲击最小,但带来的质量提升最明显。强制 TDD、标准化工作流,这两件事单独拿出来就已经值了。第二步:再建 OpenSpec。 有了 Superpowers 之后,你会越来越清楚地感觉到"AI 需要更清晰的约束"——这时候自然会想去写 OpenSpec。动机到位了,写出来的 OpenSpec 才是真的有用的,而不是为了写而写。第三步:最后搭 OMO。 OMO 是整套体系的粘合剂和加速器,它的价值建立在前两者都跑起来之后。单独上 OMO 意义不大。一是 OpenSpec 写太细。什么都规定死了,AI 反而施展不开,你自己也累。OpenSpec 的颗粒度应该是"约束边界",不是"逐行指令"。二是忽视 TDD 的"先写测试"这一步。很多人觉得先写测试慢,跳过去直接写实现,然后补测试。补出来的测试大概率是在配合实现,而不是在验证功能。先写测试的核心价值不是测试本身,是逼你在动手之前把功能想清楚。三是 OMO 的 Offline 阶段敷衍了事。代码跑通了就合并,不更新 Superpowers,不回补 OpenSpec,这样整个体系就变成了单向的,没有复利,慢慢就废了。
现在有很多人在谈"AI 会不会取代程序员",我觉得这个问题本身就问错了。我的判断是:会被取代的,是那些把自己定位成"写代码的人"的程序员——给需求,出代码,交差。这件事 AI 已经做得够好了。不会被取代的,是那些把自己定位成"设计系统的人"的程序员——他们知道用什么框架来管约束、用什么机制来保证质量、用什么流程来让协作不崩盘。OpenCode 铁三角,本质上是在帮你完成这个转变:从"写代码的人"变成"让 AI 稳定写出好代码的人"。
如果你现在在用 AI 编程,但总感觉越用越乱、越用越累,可以从今天开始做一件具体的事:为你手头的下一个需求,写一份 OpenSpec。哪怕很粗糙,哪怕只有两三行约束,先写出来。你会发现,光是这一步,就已经让 AI 的输出质量有了明显的变化。
你现在的 AI 编码体系,走到哪个阶段了?欢迎留言聊聊,或者分享你踩过的坑。
深度拆解 Hermes-Agent:五层分层架构背后的 AI Agent 设计哲学
现在的 AI 框架,似乎正陷入一种“过度工程化”的怪圈。为了让 Agent 跑起来,开发者往往要被迫学习一套复杂的“新方言”,在各种 Chain、Graph 和节点连线里反复横跳。最后代码写了几千行,逻辑却被埋在了厚厚的框架胶水里。最近我深挖了 Hermes-Agent 的源码,发现它走了一条极具“反骨”的路线:它不搞玄学的规划器,不迷信流程图引擎,甚至把近万行的核心逻辑直白地摊在一个文件里。这种“让模型面对工具直接裸奔”的设计,反而让它在处理复杂任务时表现出一种罕见的灵活性。今天不谈概念,直接拆开引擎盖。我们从底层架构入手,看看这个以“工具驱动”为绝对信仰的框架,到底是如何用最简单的逻辑,解决最麻烦的问题的。
Hermes-Agent 是一个以工具调用为核心驱动力的对话式 AI Agent 框架。不像 LangChain 那样把 Chain 和 Graph 捧上神坛,Hermes 的思路更直接——你有一堆工具,AI 决定用哪个、怎么用,执行,拿结果,继续。
最顶层是 Interface 层,负责把各种入口统一"翻译"成内部格式交给 Agent 处理。- CLI(cli.py):基于 Rich + prompt_toolkit 搭的交互式命令行,给开发者自己用
- Gateway(gateway/):消息平台网关,支持 Telegram、Discord、Slack、WhatsApp、企业微信、飞书、钉钉……以及 Matrix、Email、SMS,甚至 Home Assistant
- ACP Adapter(acp_adapter/):给编辑器用的,接入 VS Code、Zed、JetBrains
三个入口,背后跑的是同一个 AIAgent。这件事听起来平淡,但意味着一点:平台无关性是一等公民,不是后期补丁进去的兼容层。你在命令行里调的那套工具和逻辑,在 Telegram 群里一样能跑。数据流走向也很清晰:用户输入 → Interface 适配器 → MessageEvent → AIAgent.run_conversation() → 响应格式化 → 输出。
三、Core Agent 层:对话循环是一切的中心核心层只有一个文件:run_agent.py,主类 AIAgent,大约 9200 行。这个数字可以说明一个问题——框架的核心逻辑没有被过度拆散,主要思路集中在一个地方,读代码的心智负担小很多。while api_call_count < max_iterations and budget.remaining > 0:
system_prompt = self._build_system_prompt()
response = client.chat.completions.create(...)
if response.tool_calls:
for call in response.tool_calls:
result = self._execute_tool_call(call)
messages.append(tool_result_message(result))
else:
return response.content
没有什么"规划器",没有独立的"推理模块"——就是一个循环,LLM 自己决定要不要用工具、用哪个,用完再决定下一步。值得注意的是两个细节:一是 iteration_budget,父代理和子代理共享同一个预算池,不会出现子任务无限递归把额度耗光的情况;二是 ContextCompressor,上下文长了之后会自动压缩,避免超出窗口同时控制成本。Core Agent 层还包含几个内部组件:prompt_builder.py 负责组装系统提示,prompt_caching.py 做 Anthropic 的提示缓存优化,auxiliary_client.py 处理 vision 和摘要这类需要独立调用 LLM 的辅助任务,display.py 负责终端动画。职责切分清晰,没有"大杂烩"的感觉。
如果说整个架构有一个"最小原子",那就是 Tool(工具)。每个工具由四个东西组成:schema(OpenAI 函数调用格式的定义,告诉 LLM 这个工具叫什么、参数是什么)、handler(实际执行函数)、check_fn(可用性检查,决定这个工具在当前环境下能不能用)和 toolset(归属的工具集分类)。registry.register(
name="read_file",
toolset="file",
schema={ ... },
handler=lambda args, **kw: read_file(...),
check_fn=lambda: True,
emoji="📖"
)
ToolRegistry 是单例,模块导入时注册,运行时分发。MCP 工具动态更新时还支持 deregister(),热插拔无需重启。工具集系统(toolsets.py)做了一件有意思的事——不同平台使用不同的工具子集。hermes-acp 给编辑器用,去掉了消息发送和语音工具;hermes-telegram 针对消息平台裁剪了工具集。这让"同一个内核,多张脸"的承诺真正落地,而不只是接口适配层的把戏。目前内置的工具覆盖面相当广:终端命令执行、文件读写搜索补丁、Web 搜索与内容提取、Browserbase 浏览器自动化、沙箱 Python 代码执行、子代理委派、MCP 客户端、任务管理、持久化记忆、历史会话搜索、Skill 管理。这十几类工具基本覆盖了一个"能干活的 Agent"的日常需求。Skill(技能),存储在 ~/.hermes/skills/ 下,是 Markdown + Frontmatter 格式的提示词模板,通过斜杠命令 /skill-name 或工具调用触发。你可以把常用的任务模式沉淀成 Skill,复用起来很方便。Prompt(提示词),分三层:System Prompt(全局行为定义)、Ephemeral Prompt(临时提示,不写入会话存储)、以及 SOUL.md、AGENTS.md、.cursorrules 这类上下文文件。Prompt 不是一锤子买卖,而是可以分层叠加、按场景组合的结构。
会话存储用 SQLite(hermes_state.py),Schema 设计得相当细:CREATE TABLE sessions (
idTEXT PRIMARY KEY,
sourceTEXTNOTNULL, -- 来源:cli / telegram / discord...
parent_session_id TEXT, -- 会话链,支持嵌套
input_tokens INTEGER,
output_tokens INTEGER,
cache_read_tokens INTEGER,
...
);
CREATETABLE messages (
session_id TEXT,
roleTEXT, -- system / user / assistant / tool
tool_calls TEXT, -- JSON
reasoning TEXT, -- 推理过程也存下来
...
);
CREATEVIRTUALTABLE messages_fts USING fts5(content, content=messages);
FTS5 全文搜索虚拟表意味着你可以在历史会话里做关键词检索,而不只是"翻记录"。parent_session_id 支持会话链,子代理的对话可以挂在父会话下面,整条调用树都有迹可查。Token 消耗(含缓存读写)也在 Session 级别被记录,方便后续做成本分析。持久化记忆是另一层。MemoryStore 把用户偏好和环境信息写到 ~/.hermes/MEMORY.md 和 ~/.hermes/USER.md,下次启动 Agent 时读回来注入系统提示。没有向量数据库,没有嵌入模型,就是 Markdown 文件——简单到有点反直觉,但对于结构化的偏好信息来说够用了。MemoryManager 在上面再封一层,支持外部插件式的记忆提供者接入,扩展性留了口子。
Executor 层的核心是 delegate_tool.py,实现了子代理委派机制。父代理可以把一个子任务扔给一个独立的 AIAgent 实例去跑。子代理有自己的工具集,但会被主动裁剪:DELEGATE_BLOCKED_TOOLS = frozenset([
"delegate_task", # 禁止递归委派
"clarify", # 禁止向用户提问
"memory", # 禁止写入共享记忆
"send_message", # 禁止跨平台副作用
"execute_code", # 子代理应逐步推理
])
MAX_DEPTH = 2
设计意图很清楚:子代理是执行单元,不是决策单元。它不能再派出孙子代理(防止递归失控),不能找用户要输入(任务是独立的),不能乱写全局状态(隔离副作用)。MAX_DEPTH = 2 是一条硬线,越不过去。with ThreadPoolExecutor(max_workers=max_concurrent) as executor:
futures = {
executor.submit(_run_single_child, task): task
for task in tasks
}
for future in as_completed(futures):
result = future.result()
执行环境方面支持本地 shell、Docker、SSH 远程、Modal 云环境、Daytona 沙箱和 Singularity 容器,不绑死在任何一个运行时上。
没有显式规划器。 Hermes 不在代码层面实现任务拆解和规划模块,这件事完全交给 LLM 自己的推理能力去做,辅以 todo 工具让它把步骤写下来留痕。这个选择的风险是:模型推理能力差的时候,规划质量没有保底。好处是:代码极大简化,扩展和调试都更直接。没有显式工作流引擎。 不像某些框架会让你定义 DAG、连接 Node、写 Transition,Hermes 的工作流是 LLM 通过工具调用隐式"跑"出来的。这把复杂度转移到了 Prompt 工程和工具设计上,对使用者的要求更高,但系统本身更轻,没有大量的框架胶水代码需要维护。核心循环是同步的。 异步操作靠回调和后台线程处理,不是全链路 async/await。这在复杂并发场景下可能成为瓶颈,但对大多数用例来说够用,代码也更好追踪和调试。和 LangChain 这类框架相比,差异可以一行话概括:LangChain 给你提供了一套语言去描述 Agent 应该怎么跑;Hermes 给你提供了一个环境,然后让 Agent 自己跑。哪种更好,取决于你对"控制"和"自主"之间的权衡偏好。
拆到最后,Hermes-Agent 体现的是一种相对克制的工程观:不要给"智能"建太多脚手架。 规划、推理、决策——这些本来就是 LLM 最擅长的事,不需要用代码去模拟一遍。框架应该做的是把工具管好、把状态存好、把接口接好,然后退到一边,让模型去干活。这种哲学在实践层面有一个很具体的体现:Hermes 的"工作流"不是工程师定义出来的,而是 LLM 在每次对话中即兴组合工具调用"涌现"出来的。这意味着它天然灵活,也意味着它天然不可预测。用还是不用,最终还是取决于你要解决的问题:如果需要严格可审计、可回放的确定性工作流,显式 DAG 框架更合适;如果要的是一个能应对开放性任务、快速上手的 Agent 运行时,Hermes 的这套设计哲学值得认真考虑。代码层面的架构分析就到这里。如果你对某一层有更深的疑问,欢迎评论区聊。
用了三个月Claude Code,我发现90%的人根本没用对
上周有个朋友问我,为什么他用cc跑项目总是感觉很卡,上下文一多就开始乱——我远程看了一眼,发现他连 /compact 是什么都不知道。这个问题其实很普遍。很多人装好Claude Code,直接就开始上手用,完全靠直觉,遇到问题就关掉重开。这没什么大问题,但会让你永远停在"能用"的阶段,跨不进去"好用"。我今天把自己天天在用的命令和快捷键整理出来,不是给你一张大全表看着爽,而是每个都说清楚什么时候用、为什么用。我用Claude Code的方式大概是这样:新项目进来,第一步 /init,生成 CLAUDE.md,把项目结构、技术栈、一些约定俗成的规范都写进去。不这么做的话,每次开新对话Claude都要重新摸你项目的底,浪费时间还容易出错。然后开始干活。干到上下文快满的时候 /compact 一下,继续。需要换个角度想问题,用 /clear 清空重来。这是我80%时间的工作节奏。这个命令会帮你在项目根目录生成一个 CLAUDE.md 文件。这个文件的作用是告诉Claude:"这个项目是什么,有哪些规矩,有哪些禁忌。"你可以在里面写:用什么框架、代码风格要求、哪些文件不要动、测试怎么跑……Claude每次启动会自动读这个文件。相当于你给它配了一个入职手册,不用每次都口头交代。实操建议:初始化完之后不要直接用,花10分钟把里面的内容改成你项目的实际情况。默认生成的内容是通用的,价值有限。cc的对话有上下文限制。一旦超出,模型开始"失忆",给出的回答质量会断崖式下降。/compact 做的事情是把当前对话压缩成一个摘要,然后用这个摘要继续对话。不是清空,是有损压缩——重要的内容会保留,细节会丢失。所以用的时机很重要:在上下文还没满、但已经干了一大段活之后用,而不是等到系统提示你快满了再用。那个时候很多有用的上下文已经开始被截断了。经验之谈:做一个相对完整的功能之后 /compact 一次,是比较好的节奏。/model 可以让你在对话中切换模型。我的用法:- 简单的任务(写注释、改格式、生成样板代码):haiku,快且便宜
- 中等难度(功能实现、debug、代码审查):sonnet,主力
- 真正硬的骨头(架构设计、复杂算法、看不懂的报错):opus,慢但准
任务分级用不同模型,这是独立开发者控制成本最直接的方式,可以根据你的需要配置不同的模型。/clear vs /resume — 重来和恢复/clear 清空整个对话,适合当前思路完全走偏、或者要开始一个新任务的时候。/resume 恢复上一次的对话。如果你关掉了终端,再打开cc想接着干活,/resume 是你要用的命令。这个命令打开的是那个 CLAUDE.md 文件(以及全局的记忆文件)。有个快捷方式我很常用:在对话中直接输入 # 你想记住的内容,Claude会把它写入记忆文件。比如你告诉Claude"我们这个项目用驼峰命名法",下次开新对话它还记得。这个功能很多人完全不知道。用好了,cc就有了真正意义上的"长期记忆"。如果你的项目不在当前目录,或者你要同时处理多个相关的项目,/add-dir 可以把额外的目录加进来。比如你在做一个前后端分离的项目,前端在 /frontend,后端在 /backend,可以同时把两个都加进来,Claude能跨目录理解上下文。如果你在用MCP(Model Context Protocol)扩展cc的能力,/mcp 是你管理这些服务器的地方。可以看到当前连了哪些,状态怎么样,有没有报错。不用MCP的话这个可以暂时跳过,但如果你想让cc直接操作数据库、调用外部API、访问文件系统——MCP是你以后绕不开的东西。这个不用多解释。/cost 显示当前这个对话花了多少token、折合多少钱。养成习惯定期看一眼,会让你对自己的使用方式有更清晰的感知,知道哪些操作是高成本的。上下文用了多少,还剩多少。有了这个可视化,你知道什么时候该 /compact 了,不用靠猜。在git commit之前跑一下 /review,让Claude帮你过一遍改动。不是万能的,但很多低级错误和潜在问题能在这一步被捞出来。这个命令在团队协作场景里特别有用,相当于多了一个不会累的代码审查员。另外:最常用的是指定某些代码review,特别是老工程。/security-review — 专门看安全问题和 /review 不同,/security-review 专注于安全层面:有没有硬编码的密钥、有没有SQL注入风险、有没有不安全的依赖……/pr-comments — 直接拉GitHub PR评论这个命令可以把GitHub上的PR评论拉到cc里,然后让Claude帮你处理。避免你在浏览器和终端之间反复切换。需要配置GitHub相关的权限,但配置好之后很顺。cc装得有问题?命令跑不动?MCP连不上?先 /doctor 一下,自动诊断安装环境,大部分常见问题能直接给出原因。/hooks 让你在特定的工具事件发生时触发自定义脚本。比如每次Claude写完文件,自动跑一次lint;每次运行测试失败,自动发一条通知。这是cc从"工具"变成"流程"的关键一步,但有一定上手成本,适合已经把基础玩熟了的人去探索。一键接受Claude提出的所有代码变更。不用逐个确认,不用手动复制粘贴。Claude跑偏了,或者你发现思路不对,按 ESC 立即中断当前执行。不用等它跑完再纠正,直接打断,重新给方向。这个习惯能帮你省掉很多等待时间。连按两次ESC,可以跳转到上一条消息重新编辑。如果你发现刚才的问法有问题,不用重新打,直接回去改。不记得命令全名?Cmd + K 打开命令面板,搜索你想用的命令。比翻文档快得多。让某个命令在后台跑,你可以继续做其他事情。跑耗时长的任务时很实用。在对话中直接 @ 某个文件,Claude就能看到这个文件的内容,不用你复制粘贴进来。多文件联动的时候特别好用:@src/auth.js 和 @src/user.js 一起引用,让Claude看着这两个文件帮你找问题。在cc对话里,!ls -la 直接执行shell命令,结果显示在对话里。不用切终端窗口。上面 /memory 部分提到过。在对话里 # 这个项目的数据库用PostgreSQL 15 这样写,Claude会把它记进 CLAUDE.md。直接把截图粘贴到cc里,Claude会分析图片内容。调试UI问题、看报错截图、分析流程图,都可以这样做。claude --dangerously-skip-permissions
这条命令的作用是跳过所有权限确认——Claude的每一步操作都不需要你点确认,直接执行。适合的场景:你对项目很熟,改动范围明确,而且代码有git版本控制兜底。在这个前提下,这条命令能大幅提升批量操作的效率。不适合的场景: 新项目、不熟悉的代码库、没有git的情况。出了问题没有退路。命令和快捷键学起来有点枯燥,但我想说的核心只有一点:真正让独立开发者效率飞起来的,往往就是这些看起来不起眼的小东西——知道什么时候 /compact,知道用 Shift+Tab 代替手动确认,知道用 @ 引用文件而不是复制粘贴。这些习惯一旦养成,节省的时间是真实的,积累起来很可观。先把 /compact + /model + Shift+Tab 这三个组合用熟。其他的,遇到需要的场景再去学,效果反而更好。
深度解析 Hermes-Agent:构建下一代模块化 AI Agent 的 教科书级 架构
最近翻了不少 Agent 框架的源码,LangChain、AutoGen、CrewAI……各有各的玩法,但大多数框架在工程化程度上都差点意思——要么过度抽象、要么耦合严重,真正上生产就开始踩坑。Hermes-Agent 是个例外。它的架构设计让我觉得这是一份少见的"教科书级"参考实现:清晰的层次划分、合理的设计决策、对生产环境问题的真实应对。我把核心部分拆解出来,跟大家聊聊这套架构到底好在哪里。这篇文章写给那些不满足于"调用 API、套 Prompt"的开发者——如果你想认真做一个可以在生产环境落地的 AI Agent,Hermes-Agent 的架构设计值得你花时间研究。
Hermes-Agent 是一个支持多平台部署的 AI Agent 框架。你可以把它理解成一个"Agent 操作系统":- 运行模式: CLI 交互式终端、Telegram/Discord/Slack 等 15+ 消息平台、批处理模式
- 工具系统: 网络搜索、终端执行、文件操作、浏览器自动化、视觉分析……
- 上下文管理: 自动压缩长对话,理论上支持无限长会话
- 成本优化: Prompt Caching、智能模型路由
规模上,整个项目 36+ Agent 内部模块、50+ 工具文件、300+ 测试文件,不算小。
好的架构一定是分层的,Hermes-Agent 把整体拆成三个核心层:这三层的依赖是单向的:上层依赖下层,下层对上层一无所知。听起来是废话,但很多框架就是在这里翻车的——工具文件里直接 import agent,agent 里又反向依赖 UI 层,最后改一处动全身。工具注册表是整个系统的地基,而且它是个模块级单例。# tools/registry.py — 无任何内部依赖
registry = ToolRegistry()
为什么要做成单例?因为所有工具文件在被导入时就完成注册:# tools/web_tools.py
from tools.registry import registry
def web_search(query: str) -> str:
# 实现逻辑...
return json.dumps({"results": [...]})
registry.register(
name="web_search",
toolset="web",
schema={...},
handler=lambda args, **kw: web_search(args.get("query", "")),
check_fn=lambda: bool(os.getenv("FIRECRAWL_API_KEY")),
requires_env=["FIRECRAWL_API_KEY"],
)
这个设计解决了一个经典问题:循环导入。工具文件只依赖注册表,注册表不依赖任何工具。model_tools.py 在初始化时统一导入所有工具模块,触发注册——干净、可预测。每个工具注册时都带着一个 check_fn,用来检查自身的运行条件(通常是检查环境变量)。这意味着你可以在同一套代码里部署到不同环境,缺少某个 API Key 的工具会自动从可用工具列表里摘掉,而不是在运行时报错。
核心引擎 AIAgent 管理整个对话的生命周期,最值得关注的是它的主循环设计。- 预处理 — 图片/文件处理、语音转文字、斜杠命令解析
- 消息构建 — 组装系统提示词、注入历史对话、加载记忆上下文
- 工具调用 → 执行工具,把结果作为新消息追加,回到第 3 步
- 上下文管理 — 检查 token 用量,决定是否压缩
- 循环或返回 — 工具执行完继续循环,最终结果保存会话后输出
关键参数是 max_iterations,默认 90。这个数字不是随便定的——大多数真实任务在 90 轮工具调用之内都能完成,同时也防止死循环把 API 费用打穿。
很多人不会注意这个细节,但它恰恰说明了这套框架在工程细节上的成熟度。问题是这样的:run_conversation() 是同步函数(为了简化调试和状态管理),但很多工具的内部实现是异步的(网络请求、浏览器操作……)。更复杂的是,框架同时支持 CLI(同步上下文)和 Gateway(已有运行中的事件循环,异步上下文)。这不是一个可以靠"全部改成 async"解决的问题,因为 CLI 和 Gateway 的运行环境从根本上就不同。Hermes-Agent 的解法是一个专门的桥接函数:def _run_async(coro):
try:
loop = asyncio.get_running_loop()
except RuntimeError:
loop = None
if loop and loop.is_running():
# 在 Gateway 异步上下文中——用线程池跑新的事件循环
with ThreadPoolExecutor(max_workers=1) as pool:
future = pool.submit(asyncio.run, coro)
return future.result(timeout=300)
# 在 CLI 同步上下文中——用持久事件循环
if threading.current_thread() isnot threading.main_thread():
worker_loop = _get_worker_loop()
return worker_loop.run_until_complete(coro)
tool_loop = _get_tool_loop()
return tool_loop.run_until_complete(coro)
这段代码用了"持久事件循环"的技巧——不是每次工具调用都新建一个事件循环(开销大),而是维护一个线程本地的持久循环。对异步上下文,则用线程池隔离出一个干净的运行环境。这种处理方式没有完美答案,但这是已知方案里工程权衡做得比较好的。
五、上下文压缩:让 Agent 支持"无限"长会话当对话 token 数达到上下文窗口的 50%(可配置),压缩器自动触发,流程如下:Step 1: 工具输出剪枝(低成本预处理) 把历史对话里的旧工具结果直接替换成占位文本 [Old tool output cleared...]。大多数情况下,工具的执行结果在用过一次之后就不需要保留原文了。Step 2: 保护首尾消息 头部 3 条消息(系统提示 + 首轮对话)和最近 N 条消息(按 token 预算决定)不参与压缩——首轮通常包含关键指令,最近对话是当前任务状态。Step 3: 中间消息 → 结构化摘要(LLM 调用)## Goal # 当前目标
## Progress # 进度(完成/进行中/阻塞)
## Key Decisions # 关键决策
## Resolved Questions
## Pending User Asks
## Relevant Files
## Remaining Work
Step 4: 增量更新 下次触发压缩时,新摘要是在旧摘要基础上增量更新的,不是全量重生成。这节省了 LLM 调用成本。这套设计的核心思路是:不保留所有细节,但保留结构化的任务状态。对于大多数任务型 Agent 来说,这个权衡是合理的。
这一块经常被忽视,但它是 Hermes-Agent 能真正落地的关键。
def _get_or_create_agent(self, session_key: str, ...):
cached = self._agent_cache.get(session_key)
if cached and cached[1] == current_config_signature:
return cached[0]
agent = AIAgent(...)
self._agent_cache[session_key] = (agent, current_config_signature)
return agent
为什么要缓存?因为 Anthropic 的 Prompt Caching 是基于前缀的——只要系统提示不变,重复的前缀部分不收费(仅收取 10% 读取费用)。如果每条消息都新建一个 Agent,系统提示每次都要重新计价,成本直接乘以消息数量。
current_config_signature 是当前配置的哈希值。用户改变模型、工具集等配置时,签名变化,Agent 重建;否则复用,维持 Prompt Caching 的效益。这不是锦上添花,对于活跃的多用户 Gateway 部署,这个设计能节省大量 API 成本。
回顾整套架构,有几个地方我觉得特别值得单独拎出来说:很多框架为了"现代感"全部 async,但调试 async 代码的复杂度远高于同步。Hermes-Agent 选择同步核心 + 异步桥接,在工程可维护性上做了更保守也更务实的选择。不需要维护一个中央的工具列表文件,工具文件只要被导入就自动注册。新增工具只需要两步:写工具文件、在 _discover_tools() 里加一行 import。每个工具都带可用性检查,而不是在运行时报错。这让同一份代码在不同配置下都能优雅降级。不是简单地截断历史对话,而是用 LLM 生成带固定格式的摘要。固定格式意味着摘要本身也可以被 Agent 可靠地"阅读",而不只是给人看的日志。
如果你在考虑自己实现一个 Agent 框架,Hermes-Agent 的架构给出了几个关键问题的参考答案:- 工具怎么管理? — 中央注册表 + 自注册,比手动维护列表可靠
- 多平台怎么接入? — 适配器模式,每个平台实现同一个基类接口
- API 成本怎么控制? — Agent 实例缓存 + Prompt Caching + 上下文压缩,三层都要做
- 同步还是异步? — 想清楚你的调试成本,然后再决定
当然,这套架构也有它的局限:适合任务型 Agent,不太适合需要极低延迟的实时交互场景;压缩策略会丢失细节,不适合需要完整历史回溯的场景。
其实写这篇文章,并不是想安利大家都去换这个框架。毕竟这世界上没有所谓的“银弹”,只有在特定业务场景下的取舍和妥协。我之所以觉得 Hermes-Agent 值得拿出来拆解,是因为它代表了一种“反盲从”的工程审美。在大家都忙着追逐 SOTA 模型、迷信万星项目的时候,有人能静下心来,为了解决一个同步异步的桥接问题去写持久化事件循环,为了省那点 API 费去死磕结构化摘要。很多时候,我们离做出一个真正好用的 AI 应用,差的不是那个最牛的 LLM,而是对底层工程细节的敬畏。如果你也正深陷在“框架看起来很美,落地起来稀碎”的坑里,建议你放下文档,去读读它的源码。有时候,答案不在那些高大上的 PPT 里,就在这些一行行扎实的代码逻辑里。
大模型应用全景图:一文读懂Prompt Engineering、Context Engineering与Harness Engineering
没有发布会,没有预热,就这么安静地上线了。但它在技术圈里传开的速度,比任何一次模型发布都快。原因是博客里有这样一组数据:3个工程师,5个月,产出了100万行生产级代码。没有一行是人手写的。他们通过大约1500个Pull Request完成了一款内部产品的构建和迭代,每人每天平均合并3.5个PR。沉默了几秒之后,很多人的第一反应是:他们用了什么特殊的模型?
过去两年,我们"学会用AI"这件事,其实经历了三个完全不同的阶段。很多人卡在某一个阶段里浑然不觉,还以为自己已经用得很溜了。第一个阶段:Prompt Engineering(2024年)这是大多数人最熟悉的阶段。核心问题只有一个:怎么措辞?你在ChatGPT里反复调整问题的表达方式,加上"请用专业语气"、"分三步回答我"、"不要废话直接给结论"这类修饰语。写出好提示词,回答质量就高;写得随意,回答就跑偏。整个交互模式是一问一答,你在乎的是那一次回答的质量。第二个阶段:Context Engineering(2025年)真正的功夫在于:在AI运行的过程中,在合适的时机输入合适的内容。先给它看相关文档,再给它看你的需求,再给它看历史案例,最后才让它动手——这样的效果,比一次性把所有要求堆在一个提示词里要好得多。2025年6月,前OpenAI联合创始人Andrej Karpathy发了一条推文,为这个概念正式命名:"工业级LLM应用的核心功夫,是上下文工程——精心填充上下文窗口,让模型在每一步都拿到恰好足够的信息。"这条推文在技术圈引爆了讨论。三个月后,Anthropic发布了系统性的Context Engineering方法论博文,这个概念从一条推文变成了完整的工程实践。第三个阶段:Harness Engineering(2026年)然而,即便把Context Engineering做到极致,很多复杂任务还是做不了。问答没问题,简单任务没问题。但要让AI独立完成一个完整功能的开发、测试、集成?要让它自主生产一份结构严谨、逻辑完整的深度内容?大概率半途而废,或者产出一堆看起来像那么回事、实则漏洞百出的东西。2026年2月,HashiCorp联合创始人Mitchell Hashimoto在他的博客里给出了答案,并正式命名了这个新概念——Harness Engineering。每当你发现Agent犯了一个错误,你就花时间工程化一个解决方案,让这个错误永远不再发生。注意,这里说的不是"写一行提示词让AI下次注意"。而是用代码、配置、自动化脚本,把约束永久固化下来。同月,OpenAI发布了那篇引爆技术圈的博文,用100万行代码的数据,证明了这套方法论的威力。
三个阶段的关键认知:它们是包含关系,不是替代关系。很多人看到"Harness Engineering"这个新词,第一反应是"Prompt Engineering过时了?"Philipp Schmid(Hugging Face工程师)用了一个很直观的类比:AI模型是CPU,上下文窗口是RAM,而Harness就是操作系统。你不会在没有操作系统的CPU上直接跑程序——同理,让AI在没有Harness的环境里"裸跑",效率和可靠性都会大打折扣。写好提示词的能力永远有用,只是仅凭提示词,已经不够应对真正复杂的任务了。
综合OpenAI、Anthropic以及大量一线团队的实践,Harness Engineering可以提炼为四大支柱。每一根都直接对应你使用AI时真实踩过的坑。简单来说:给Agent一份精炼的"项目行军指南",让它每次启动都自动读取。想象一个场景:你让AI帮你在一个Python项目里写代码。它不知道你用pytest还是unittest跑测试,不知道你偏好snake_case还是camelCase,不知道.env文件碰不得。你每次开新对话都得重新说一遍。总有一次你忘了,然后AI就真的改了那个不该碰的文件。解决方案是在项目根目录放一个配置文件——Anthropic体系叫CLAUDE.md,OpenAI体系叫AGENTS.md。AI每次启动自动读取,获取项目的技术栈、常用命令、编码规范和行为禁区。但这里有一个反直觉的核心原则:它应该是地图,而不是百科全书。OpenAI团队有过代价不菲的教训:他们曾尝试把所有信息塞进一个庞大的配置文件,失败了。上下文窗口是稀缺资源,一个500行的说明书反而让AI不知道哪些信息和当前任务相关。他们的黄金标准是100行左右,作为导航目录指向结构化的文档,AI按需检索具体内容。Hashimoto分享了一条维护法则,我觉得非常值得学习:配置文件里的每一条规则,都应该对应过去一个真实的AI错误。他的项目配置文件,"每一行都对应一个过去的Agent错误行为,而且几乎完全解决了所有这些问题"。这意味着你不需要一次写出"完美的"配置文件。从空白开始,每次AI犯错就补一条规则,让它越用越聪明。这是一种增量式学习机制,比任何事先设计都更贴近实际。
简单来说:用自动化工具把约束刻进执行流程,不依赖AI的"自觉性"。配置文件写的是"你应该这样做",是建议。而Hooks(钩子)执行的是"你必须这样做,否则操作被阻止",是法律。**CLAUDE.md是建议,Hooks是法律。**建议可以被忽略,法律不行。什么是Hooks?如果你用过Git,可能听说过Git Hooks——在git commit时自动触发的检查脚本。AI的Hooks是同样的概念:在AI执行某个操作之前或之后,自动触发一段检查程序。通过就继续,不通过就拦截,AI没有"选择忽略"的余地。场景一:安全防火墙。 AI准备执行一条清理命令,但路径写错了,变成了删除整台机器所有文件的灾难性操作。PreToolUse Hook在命令执行前触发,检测到危险模式,10毫秒内硬性拦截。人类来不及反应,机器已经挡住了。场景二:提交前自检。 AI写完代码准备提交,PreToolUse Hook检测到git commit命令,自动先跑一遍代码质量检查。发现问题就拦截并把错误报告反馈给AI,AI自动修复后再次尝试提交。整个过程无需人类介入。场景三:任务完成通知。 你让AI跑一个耗时15分钟的任务,然后去泡咖啡。任务完成时,Hook自动弹出桌面通知。你听到提示音回来查看结果。这里有一个很多人没想到的洞察:给AI更多约束,反而能提升它的产出质量。当你告诉AI"用任何你觉得合适的方式实现这个功能",它面对无限可能性,选择的方差极大。但当你约束它"必须用React组件、遵循项目的命名规范、通过Service层调用后端",它在收窄后的解空间里反而更容易找到正确答案。这和优秀团队的经验完全一致:有明确编码规范的团队,代码质量通常优于"自由发挥"的团队。约束不是限制创造力,而是把创造力引导到有价值的方向上。
简单来说:让AI在每一步都能自动获知"做得对不对",而不是做完所有事才发现全错了。Anthropic在博文里有一个极其精准的比喻:AI的每个新会话开始时没有之前的记忆,就像轮班的工程师没有交接记录。上午的工程师做了一半,下午换了另一个人——如果没有任何交接文档,下午的人可能重做上午的工作,也可能继续一个错误的方向。反馈循环就是确保每一位"轮班工程师"都知道:做到哪了,做得对不对,下一步该做什么。- 构建反馈:提交PR时,CI/CD自动跑测试和代码检查
- 评审反馈:功能完成后,独立评估者检查设计层面的遗漏
这四层不是"选一个就够"的关系,它们捕获的问题类型完全不同。缺少任何一层,就意味着某类问题会"静默通过",直到造成实际损害。最前沿的探索是Anthropic在今年3月提出的GAN式三Agent架构。受生成对抗网络(GAN)启发,他们设计了三个Agent协同工作:Planner负责把模糊需求扩展为可执行规格,Generator负责实现,Evaluator负责独立评估。为什么要独立评估?因为他们发现了一个根本性问题:当AI被要求评估自己的工作时,它会表现出不合理的自信和宽容——即使产出很平庸,自评也倾向于打高分。解决方案不是"让AI学会自我批评",而是把评估彻底交给独立的角色。正如他们在博文里写的:调校独立评估者的怀疑度,比让生成者对自己的工作保持批判性要容易得多。更有意思的是,他们在实验中发现:有了持续施压的独立评估者,Generator到第10轮迭代时主动放弃了之前9轮的设计方向,重新构想出一套完全不同的创意方案。好的反馈循环不只是防错工具,它还能激发创造力。 这是很多人没有预料到的。
简单来说:主动对抗AI代码生成带来的渐进式系统退化。这是最容易被忽视的一根支柱,但可能是Harness Engineering里最具原创性的洞察。传统软件开发的质量问题主要是bug——程序崩溃、逻辑错误、安全漏洞。但AI生成的代码有一种全新类型的质量问题:不是某一行代码写错了,而是整个代码库在缓慢退化。文档漂移:AI改了代码,但忘了更新注释。注释说返回{name, email},代码实际上已经加了role字段。三个月后,另一个AI依赖这条注释写了新功能,然后才发现不对——但到那时已经有十几个地方依赖了错误的假设。架构侵蚀:项目约定所有数据库查询必须通过Repository层。某次AI觉得这样多写两个方法太麻烦,直接在Controller层写了SQL查询。代码能跑,功能正常。但这个"先例"一旦出现,下一个AI也跟着绕过约束。几个月后,30%的数据库查询散落在各处,等你想换数据库的时候,才发现需要改的地方遍布全身。风格不一致:周一的AI用camelCase,周三的AI用snake_case,周五的又换回去了。三种风格在同一个项目里共存,每次调用API都得猜这个接口用的是哪种风格。这些问题单独看都不严重,不会让程序崩溃,不会触发报错。但它们的累积效应是致命的。这就是"熵"的本质——不是爆炸性的灾难,而是渐进式的腐烂。OpenAI对此有一个精炼的解法:把"品味"编码为规则。团队对代码质量的判断标准,不是写在文档里祈祷AI遵守,而是写成linter规则自动扫描。发现userName这种违规字段,linter直接报错并告诉AI怎么改——错误消息本身就是修复指南。人类的审美判断是珍贵而稀缺的,通过机械化,它的价值被无限放大了。这根支柱还有一个重要警告,来自Philipp Schmid,他称之为"Bitter Lesson":Harness必须设计成可删除的。今天需要复杂管线才能完成的任务,明天可能一个提示词就搞定了。Vercel删掉了80%的Agent工具,效果反而更好。LangChain一年内重构了三次架构。Manus团队6个月内重构了5次。血泪教训都指向同一个原则:从简单开始,为删除而构建。
2026年3月,LangChain做了一个控制变量实验,结果让很多人重新理解了"优化方向"这件事。他们在Terminal Bench 2.0基准测试上,模型完全不换,只调整了三个Harness变量:系统提示词、工具配置、中间件Hooks。结果:排名从30名开外跃升到Top 5,提升了13.7个百分点。作为对比,同期如果通过换一个更强的模型来提升成绩,通常能获得约6.8个百分点的提升。也就是说:优化Harness的效果,是换模型的两倍。这组数据彻底颠覆了"性能不够就换更大模型"的朴素直觉。对大多数团队来说,优化Harness的投入产出比,远高于追逐最新模型。产出质量 = 模型能力 × Harness设计水平模型能力是你暂时改变不了的,但Harness设计水平完全在你手里。
OpenAI Codex(3人团队):五大核心原则 + 六层分级架构约束 + 自动垃圾回收。核心启示:Harness不是锦上添花,是Agent-First开发模式的根基。没有精心设计的Harness,3个人不可能管住Agent产出100万行代码。Stripe Minions(企业级):工程师在Slack里给issue打一个表情,Minion自动接手,生成代码+测试+文档,经过CI/CD验证,提交PR,人类审查后合并。近500个MCP工具,每周1300多个PR,所有PR都有人工审查,但没有一行是人工写的。特别值得学习的是他们的Blueprint机制——AI动手前先生成实现计划,经人类批准后才开始执行。LangChain(开源团队):就是上面那个控制变量实验的主角。他们的独特贡献是Doom Loop检测中间件——当AI反复修改同一个文件却始终无法通过测试时,中间件自动介入,提示AI重新评估思路,而不是一直在同一个方向上打补丁。GStack by Garry Tan(个人开发者):Y Combinator总裁开源的Claude Code工作流,48小时内获得10000个GitHub Star。核心理念是"流程而非工具集"——28个角色按Sprint顺序运行,整个Harness全是纯Markdown文件,零代码依赖。60天内产出60万行代码,同时他还在全职管理YC。Peter Steinberger(个人,极端案例):月均6600次代码提交,代表了另一个极端——最小约束,最高信任。几乎不用复杂的Hook体系,靠极其精炼的配置文件和对项目的深度理解来引导AI。需要说明的是:这是极端案例,不建议直接模仿。Steinberger对项目有极深的理解,能快速判断AI产出是否正确。大多数人需要更强的约束和反馈循环才能放心地让AI工作。- 个人开发者 → GStack(流程清晰,上手门槛低,纯Markdown)
- 团队协作 → Stripe Minions(CI/CD集成,人工审查,MCP工具链)
- 学方法论 → LangChain(控制变量实验,数据驱动优化)
- 理解上限 → OpenAI Codex(Agent-First的天花板在哪里)
Mitchell Hashimoto这样描述自己现在的角色:我是软件项目的架构师。我仍然负责代码结构、数据流设计、状态管理。过去,厨师亲自做每一道菜。现在,厨师负责设计菜单、训练厨房团队、检查每道菜的出品质量。这不是降级,而是升级。它需要更高层次的系统思维——你需要同时理解:AI擅长什么,哪里会犯错,怎样的约束能最小化错误,怎样的反馈循环能让系统越用越好。复杂度并没有消失,只是从"写代码的复杂度"转移为"设计环境的复杂度"。而这个新的地方,更适合发挥人类在系统思维上的优势。
在所有这些令人兴奋的数字面前,有几点清醒是必要的。验证缺口:Harness擅长检查代码是否"合规"——风格、结构、类型。但对代码是否"正确"——功能逻辑是否符合业务预期——的验证仍然不够。Linter能抓住格式问题,但抓不住业务逻辑错误。这个缺口目前还没有成熟的解法。遗留代码困境:目前几乎所有成功案例都是从零开始的新项目。对于已有数万行遗留代码的系统,如何设计Harness使AI能在其中安全工作,还没有经过验证的方法论。这不是小问题,大多数公司面对的恰恰是存量系统。成熟度差异很大:软件开发场景已经大规模验证;内容生成有明显前景但还在探索;医疗、法律等高风险领域,验证缺口的问题会被放大到无法接受,暂时不适用。Harness Engineering这个概念正式命名才几个月,很多东西还在快速演化中。现在就说它已经解决了AI应用的所有问题,言之过早。但它提供的框架和方向,是目前最有说服力的答案。
如果你现在想把这些东西用起来,不需要一步到位搭建复杂的系统。最小可行的起点:在你最常用的项目里创建一个CLAUDE.md(或AGENTS.md)文件,写下三件事:项目用什么技术栈、哪些命令是常用的、哪些文件绝对不能碰。然后在使用过程中,每次AI犯错,就把那个错误背后的规则补进去。就这样。从一个100行以内的文件开始,随着使用不断积累。这是Hashimoto的方法,也是那些做出惊人产出的团队实际在做的事。真正的门槛从来不是技术,而是思维方式的转变——从"怎么写好一个提示词",到"怎么为AI搭建一个好的工作环境"。
参考资料:OpenAI Harness Engineering博文(2026年2月)/ Mitchell Hashimoto个人博客(2026年2月)/ Anthropic Context Engineering & Long-Running Agents系列博文(2025年9月-2026年3月)/ LangChain Terminal Bench 2.0实验报告(2026年3月)/ Martin Fowler团队Harness Engineering分析
搞个AI,居然把公司的 裤衩 都暴露了,问你怎么办?
上周和一个朋友聊天,他在某家集团公司负责AI落地项目。聊到一半,他发来一张截图,沉默了几秒,说:"你看,我们的智能问答系统……出事了。"截图上,一个销售部门的员工在内部知识库里问了一句:"最新的客户合同模板在哪里?"AI回答得非常热情,不仅给了合同模板,还顺带把三份尚未签署的客户报价单、一份竞品分析文件,以及一个季度的销售毛利数据,一并"贴心地"附上了。
这是绝大多数企业在搭建RAG知识库时,会踩的一个系统性的坑——权限控制,根本没做,或者做错了地方。
RAG(检索增强生成)系统的逻辑,用大白话解释就是:员工问问题 → 系统去知识库里检索相关文档 → 把检索到的内容喂给大模型 → 大模型总结回答系统去检索的时候,它根本不知道你有没有权限看这些文档。于是,那个销售员工的问题触发了语义相似性检索,系统找到了和"客户合同"高度相关的一堆文档,其中就包括那几份敏感数据,然后毫无障碍地交给了大模型去整理总结。大模型不知道这些数据是机密,它只负责把检索到的内容讲清楚。
员工登录系统的那一刻,系统就要知道一件事:这个人,是谁。- 他的安全密级(security_clearance)
这些信息,会被写入一个叫 JWT Token 的访问令牌里,随着每一次查询请求,一起带到系统后端。这是整个权限体系的基础。没有这一层,后面的防线都是空中楼阁。
第二层:检索层——"你能看什么"(这是最关键的一层)很多团队的做法是:先检索,再过滤——"反正先把相关内容都找出来,最后再判断哪些能给用户看。"第一,性能浪费。大量无权限的文档被召回,占用计算资源,拉低检索质量,最终影响回答的准确性。第二,存在泄露风险。过滤逻辑一旦出现哪怕一行代码的Bug,数据就直接裸奔。{
"tenant_id": "subsidiary_A",
"department": "finance",
"security_level": 3
}
员工查询时,系统根据他的 Token,自动构建过滤条件:只检索:属于该员工所在子公司 AND 部门匹配 AND 安全级别不超过该员工密级的文档
这样,检索引擎在执行向量搜索之前,就已经把无关的文档排除在外了。对于多子公司、多事业部这种"数据绝对不能互通"的场景,元数据过滤还不够稳,需要更硬的手段。利用向量数据库(比如Milvus)的分区机制,直接把子公司A的数据和子公司B的数据放进不同的物理分区。子公司A的员工查询,就只在A的分区里搜,物理上根本碰不到B的数据。实际工程建议: 大型集团用"按子公司分区 + 分区内元数据过滤"的混合方案——公司间用物理隔离,公司内用逻辑过滤控制部门和角色权限。两层叠加,才是真正稳的。
在把检索到的内容喂给大模型之前,应用层会做最后一次校验:这批文档片段,当前用户真的有权限看吗?如果发现有漏网之鱼,直接丢弃,不进入大模型的上下文。除此之外,还有一个动作:脱敏处理。 身份证号、手机号、薪资数字,即使通过了权限校验,也要在返回前做自动打码,防止因为大模型的"热情发挥"而被完整复述出来。
文档的元数据(标题、上传人、版本号等)通常存在 PostgreSQL 这样的关系数据库里。一个稳健的做法是开启 Row Level Security(行级安全策略)。它的作用是:即使应用层代码有漏洞,数据库本身也会根据当前用户的身份,自动过滤掉无权访问的数据行。应用层是第一道墙,数据库是最后的堡垒,两道墙都倒了才出事。
这不只是为了合规(GDPR等要求),也是追溯泄露源头的唯一手段。如果哪天真出了数据泄露事故,没有日志,就是无头案。
有些攻击不是技术层面的破解,而是利用合法账号"慢慢蚕食"数据。- 高频查询:同一账号1分钟内发起50次以上查询,可能是在跑脚本批量爬取数据
- 越权尝试:普通员工账号频繁触碰L3/L4文档的查询条件
触发规则后,可以自动冻结账号并通知安全团队,不用等到第二天早上开会才发现。
每次查询都去企业的LDAP或权限数据库里实时拉取权限信息,会带来50-100ms的额外延迟。一天几千次查询,体验会很差。解决思路是把权限信息缓存在JWT Token里,Token有效期设5-10分钟。但随之而来的问题是:员工离职或岗位调整时,旧Token还在有效期内怎么办?答案是维护一个Token黑名单,员工权限变更时,把其旧Token强制加入黑名单,立即失效。这样既保住了性能,也不会留下权限"空窗期"。
他们花了两周时间,把整套权限体系从头补上,重新灰度上线。"以前以为权限是锦上添花,现在觉得它是系统的地基。地基没打好,楼建得越高,摔得越惨。"企业AI落地的坑,很多不是模型不够聪明,而是工程上没想清楚。
你们公司的知识库,目前是怎么做权限控制的?欢迎留言聊聊,或者转给正在做企业AI项目的朋友看看。
AI 还在“猜”代码?一文读懂从考古式搜索到知识图谱的质变
先说一个让很多人头痛的场景,用 Cursor 或者 Claude Code 改一个函数,AI 很顺溜地给你写完了。你一合并,CI 挂了。报错信息告诉你:另外三个文件依赖了这个函数的返回类型,全崩了。你回去问 AI,它说"抱歉,我不知道这个函数还被其他地方调用了"。这不是 AI 不够聪明,而是它根本没办法知道——它只能看到你丢给它的上下文,对整个代码库的结构是盲目的。这就是当前所有 AI 编程工具的共同局限:缺乏对代码库结构的全局感知。
用一句话说:GitNexus 把你的代码库解析成一张代码知识图谱,然后把这张图的查询能力通过 MCP(Model Context Protocol)暴露给 AI 编辑器。所谓代码知识图谱,就是把代码里每一个函数、类、模块、接口变成图的节点,把它们之间的调用关系、引用关系、继承关系变成图的边。这样你就从"一堆文件"变成了"一张关系网"——每个函数在哪、被谁调用、依赖了谁、属于哪个执行流,全部显式存在图里。这件事的意义在于:AI 不再需要靠关键字去猜代码。以前你问灵码或者 Claude"这个函数是干什么的",它要去翻文件、猜上下文、估依赖关系,本质上是在做概率猜测。有了代码知识图谱,AI 直接查图就能拿到精确答案——谁调用了这个函数、调用链有几层、改了会影响哪些执行流,都是确定的结构化数据,不是推断出来的。有了这张关系网,AI 就可以在改代码之前先问一句:"这个函数上游有哪些调用者?改了之后会影响谁?"——一个查询,拿到完整答案。普通 RAG 是把代码文件切块、向量化,然后做语义搜索。它能找到"相关的文件",但不知道这些文件之间的依赖关系是什么。GitNexus 是把依赖关系本身存进图数据库,查询时直接遍历图,拿到的是结构化的调用链,而不是模糊的相似段落。
第一步,扫描文件结构。 走遍整个目录树,建立文件和文件夹的层级关系。第二步,用 Tree-sitter 做 AST 解析。 Tree-sitter 是一个增量式语法分析器,可以把源代码解析成抽象语法树(AST)。GitNexus 用它提取每个文件里的函数定义、类定义、接口、方法——不是靠正则匹配,而是真正理解语法结构。目前支持 13 种语言:TypeScript、Python、Go、Rust、Java、Kotlin、C#、PHP、Ruby、Swift、C、C++ 以及 JavaScript。第三步,做跨文件的引用解析。 这是最难的部分。比如文件 A 里有 import { validateUser } from './auth',那么 A 对 validateUser 的每一次调用都会被记录为一条 CALLS 边。类的继承关系记为 EXTENDS,接口实现记为 IMPLEMENTS。self/this 的接收者类型也会做推断,确保方法调用归属正确。第四步,社区发现(Community Detection)。 用 Leiden 算法对图做聚类,把功能上紧密相关的函数和类归为一个"社区"(cluster)。比如所有跟认证相关的代码会聚成一个 Auth 社区,所有跟数据库操作相关的会聚成一个 DB 社区。第五步,执行流追踪(Process Detection)。 从入口函数出发,沿着调用链追踪完整的执行路径。比如"登录流程"会被还原为一条从 handleLogin → validateUser → checkPassword → createSession 的完整步骤链。第六步,建混合搜索索引。 同时建 BM25(关键词检索)和向量语义索引,查询时用 RRF(Reciprocal Rank Fusion)融合两路结果,兼顾精确匹配和语义相似。所有数据存在 LadybugDB(一个嵌入式图数据库,支持向量和 Cypher 查询)里。索引存在项目根目录的 .gitnexus/ 文件夹内,全程本地,代码不离开你的机器。
cd your-project
npx gitnexus analyze
这条命令会:解析代码库、建知识图谱、生成 AGENTS.md 和 CLAUDE.md 上下文文件、在 .claude/skills/ 里写入 agent skill 文件,顺手帮你配好 Claude Code 的 hooks。它会自动检测你装了哪些编辑器,写好对应的全局 MCP 配置。claude mcp add gitnexus -- npx -y gitnexus@latest mcp
Cursor 用户在 ~/.cursor/mcp.json 里加:{
"mcpServers": {
"gitnexus": {
"command": "npx",
"args": ["-y", "gitnexus@latest", "mcp"]
}
}
}
通义灵码用户同样可以接入。 灵码支持标准的 MCP 协议,在灵码的 MCP 配置文件里加入下面这段就行:{
"mcpServers": {
"gitnexus": {
"command": "npx",
"args": ["-y", "gitnexus@latest", "mcp"]
}
}
}
如果网络有问题,也可这样配置,不需要每次去下载最新版本。{
"mcpServers": {
"gitnexus": {
"command": "npx",
"args": ["gitnexus", "mcp"]
}
}
}
配置位置在灵码的设置 → MCP 服务器管理,粘进去保存即可。MCP 协议是通用标准,配置格式跟 Cursor 完全一样,复制过去就能用。另外,gitnexus analyze 生成的 skill 文件默认写在 .claude/skills/ 目录下,这是给 Claude Code 用的格式。灵码有自己的 skill 机制,对应目录是 .lingma/。把 .claude/skills/ 里的文件复制一份到 .lingma/ 下,灵码就能读到这些模块级的上下文描述,回答你关于特定模块的问题时会更精准,不用每次靠它自己猜文件结构。# 把 skill 文件同步给灵码
cp -r .claude/skills .lingma/skills
配好之后,你的 AI 编辑器就多了 7 个工具可以调用。直接打开 gitnexus.vercel.app,把你的项目 ZIP 包拖进去,就能看到可交互的知识图谱,并且可以直接在里面跟 AI 对话。整个 Web UI 跑在浏览器里,Tree-sitter 和 LadybugDB 都编译成了 WASM,连向量索引也在浏览器里跑。代码不上传服务器,隐私有保障。缺点是大型仓库会受浏览器内存限制(大概 5000 个文件以内没问题)。如果你本地有 CLI 索引好的项目,可以跑 gitnexus serve,Web UI 会自动连接本地服务器,不用重新上传。git clone https://github.com/abhigyanpatwari/gitnexus.git
cd gitnexus/gitnexus-shared && npm install && npm run build
cd ../gitnexus-web && npm install
npm run dev
impact({ target: "UserService", direction: "upstream", minConfidence: 0.8 })
TARGET: Class UserService (src/services/user.ts)
UPSTREAM (what depends on this):
Depth1 (WILL BREAK):
handleLogin[CALLS 90%]-> src/api/auth.ts:45
handleRegister[CALLS 90%]-> src/api/auth.ts:78
UserController[CALLS 85%]-> src/controllers/user.ts:12
Depth2 (LIKELY AFFECTED):
authRouter[IMPORTS]-> src/routes/auth.ts
Depth 1 是直接调用者,Depth 2 是间接影响到的。每条关系还带置信度分数,让 AI 知道哪些是确定的、哪些是推断的。direction 可以换成 downstream,看这个函数依赖了谁,改了会不会引入新 bug。context({ name: "validateUser" })
返回这个函数被谁调用(incoming.calls)、调用了谁(outgoing.calls)、参与了哪些执行流(processes)、在第几步。相当于把函数的上下文全挖出来,AI 不用再靠猜了。3. query — 按语义搜索,结果按执行流分组query({ query: "authentication middleware" })
返回的结果不是简单的文件列表,而是按执行流(process)分组的符号清单。AI 拿到的是"登录流程里跟认证相关的函数有这些,分别在第几步",比一堆散装文件片段有用得多。4. detect_changes — 提交前的风险扫描detect_changes({ scope: "all" })
对比 git diff,把改动的每一行映射到受影响的函数和执行流,给出整体风险评级(low/medium/high)。这个工具特别适合在写完代码、提交之前让 AI 做一遍自查。rename({ symbol_name: "validateUser", new_name: "verifyUser", dry_run: true })
先用 dry_run: true 预览会改哪些文件、改几处,确认没问题再实际执行。图谱里的边会告诉它所有引用点,text_search 补充抓字符串硬编码的地方,改完基本不会漏。如果你熟悉 Cypher(Neo4j 用的图查询语言),可以直接写原始查询,灵活度最高:MATCH (c:Community {heuristicLabel: 'Authentication'})<-[:CodeRelation {type: 'MEMBER_OF'}]-(fn)
MATCH (caller)-[r:CodeRelation {type: 'CALLS'}]->(fn)
WHERE r.confidence > 0.8
RETURN caller.name, fn.name, r.confidence
ORDER BY r.confidence DESC
这条查询的意思是:找出所有调用认证社区里函数的调用者,只返回置信度 0.8 以上的,按置信度降序排。一个 MCP server 可以服务多个已索引的仓库,这个工具列出所有仓库,其他工具加 repo 参数指定用哪个。
GitNexus 还能从知识图谱生成 wiki,需要配一个 LLM API key:export OPENAI_API_KEY=sk-xxx
# 用默认模型(gpt-4o-mini)
gitnexus wiki
# 指定更强的模型
gitnexus wiki --model gpt-4o
# 用自定义 API(比如兼容 OpenAI 格式的本地模型)
gitnexus wiki --base-url https://your-api-endpoint/v1
生成的 wiki 不是靠爬文件注释拼出来的,而是先读图谱里的模块划分和调用关系,让 LLM 写出有架构感的文档,带模块说明、跨模块关系、Mermaid 关系图。
你刚加入一个新项目,代码几万行,没人给你讲架构。用 npx gitnexus analyze 跑一遍,然后让 AI 给你讲"这个项目有哪些主要模块,各自做什么,相互之间怎么调用"。AI 有了图谱数据,回答会比靠猜靠读文件准确得多。你要把一个核心 service 拆开。先用 impact 工具查清楚这个 service 被多少地方依赖、影响深度有多深,再决定拆法,避免盲目下刀。报错在 C 文件,但 bug 可能在 A 里埋下的。用 context 查 C 里出错的函数,看它被谁调用、调用链怎么传,快速定位真正的问题根源。写完一批改动,跑 detect_changes 扫一遍,看看有没有意外影响到别的流程,风险级别多高。比人工 review 快,也比 AI 盲猜靠谱。
# 索引当前目录的代码库
npx gitnexus analyze
# 强制重建索引(代码改动大时用)
npx gitnexus analyze --force
# 生成功能模块专属的 skill 文件(AI 能更精准地理解各模块)
npx gitnexus analyze --skills
# 开启向量嵌入(语义搜索更准,但慢一些)
npx gitnexus analyze --embeddings
# 查看所有已索引的仓库
gitnexus list
# 查看当前仓库的索引状态
gitnexus status
# 启动本地 HTTP server,供 Web UI 连接
gitnexus serve
# 清除当前仓库的索引
gitnexus clean
# 生成仓库文档
gitnexus wiki
Web UI 版本受浏览器内存限制,超大仓库(5000+ 文件)建议用 CLI 模式配合 gitnexus serve 来跑。向量嵌入默认关闭,因为会明显拖慢索引速度。如果你的搜索需求比较复杂,或者关键词不够精确,可以加 --embeddings 开启,语义搜索质量会提升不少。
AI 编程工具的瓶颈,不在于模型不够聪明,而在于模型看不到代码库的全貌。GitNexus 补的就是这块——用代码知识图谱给 AI 装上"结构透视眼",让它在改代码之前就知道牵一发动全身的是哪里。不管你用的是 Cursor、Claude Code,还是通义灵码,本质上都是在靠 AI 猜代码结构。接入 GitNexus 之后,猜的成分就去掉了——AI 拿到的是图谱里存好的精确关系,不再靠关键字比对和语义推断来摸索你的代码。如果你每天用这类工具写代码,值得花十分钟试一下。跑一遍 npx gitnexus analyze,然后让 AI 解释一个你最近改过的函数的影响范围,看看它给出的答案跟你自己估的有多少差距。
Text2SQL数据分析智能体:让自然语言成为数据分析的入口
在很多企业项目中,测试数据准备、验证和分析是一件既琐碎又高门槛的工作。
一个简单的查询,往往需要分析师编写复杂的SQL;一个数据验证任务,可能要花上半天去构造数据、执行比对、再人工核查。
但如果——只需一句自然语言指令,就能自动生成SQL、查询数据、验证结果、生成图表报告?
这正是Text2SQL数据分析智能体要解决的问题。
它让每一个人,不论是否懂SQL,都能高效、准确地与数据库交互,从数据中获得洞察。
一、Text2SQL数据分析智能体是啥?
1. 定义与定位
Text2SQL数据分析智能体是一种基于自然语言处理(NLP)和大语言模型(LLM)的智能系统,
它能自动将用户的自然语言查询(如“查一下上季度的销售额”)转化为可执行的SQL语句,并将结果以表格或图表形式返回。
在数据生命周期中,它的作用主要集中在:
测试阶段:自动生成和校验测试数据;
分析阶段:快速完成数据查询、聚合、比对;
报告阶段:自动输出分析结论与可视化图表。
2. 与传统方式的对比
方式 | 特点 | 问题 | Text2SQL优势 |
|---|
手工SQL | 精确、灵活 | 技术门槛高、编写慢、易出错 | 自动生成、语义准确、低门槛 |
BI工具 | 可视化操作方便 | 需要预设数据模型,临时查询不灵活 | 直接自然语言交互、无需建模 |
AI智能体 | 理解自然语言、生成SQL | —— | 兼具灵活性与智能化 |
简单来说,Text2SQL智能体把“写SQL”这件事变成了“说人话”。
3. 应用场景举例
自动化测试数据准备:输入“生成100条北京地区的用户数据,年龄20-40岁”,智能体自动生成SQL插入语句;
测试结果验证:输入“检查订单表和发票表金额是否一致”,系统自动比对数据;
临时分析查询:输入“上周销售额最高的五个产品”,自动返回结果并可生成图表;
客服场景:输入“昨天的投诉量是多少?”,系统即时查询并回答。
二、Text-to-SQL技术基础与挑战
1. 技术流程概览
Text2SQL技术的核心流程分为三步:
自然语言理解(NLU) —— 理解用户的语义与意图;
Schema理解 —— 理解数据库结构(表、字段、关系);
SQL生成 —— 将意图转化为合法、可执行的SQL。
例如:
用户输入:“查询上季度华东地区销售额前五的客户。”
系统执行流程是:
解析语义:识别时间范围(上季度)、地区(华东)、对象(客户)、指标(销售额);
查找Schema:定位“客户”表、“销售”表及关联关系;
生成SQL:
SELECT c.name, SUM(s.amount) as total_sales FROM customer c JOIN sales s ON c.id = s.customer_id WHERE s.region = '华东' AND s.date BETWEEN ... GROUP BY c.name ORDER BY total_sales DESC LIMIT 5;
2. 实现过程中的主要挑战
自然语言歧义性:如“本月销售额”是按下单时间还是发货时间?
复杂SQL结构:多表JOIN、子查询、嵌套GROUP BY;
Schema差异性:不同数据库字段命名不同;
通用性与自适应:面对未见过的Schema仍能生成正确SQL。
这些挑战决定了Text2SQL智能体不仅是一个NLP任务,更是语义理解 + 数据建模 + 程序生成的综合系统。
三、数据库Schema理解与表示
1. Schema信息的提取
要生成正确的SQL,系统必须“了解数据库的世界”。
Schema理解模块负责从数据库中提取以下信息:
表信息:表名、表用途;
字段信息:字段名、数据类型、描述;
关系信息:主外键关系;
索引与约束:如唯一性、非空约束;
元数据描述:开发者手动录入的字段说明。
在企业实践中,可以通过以下SQL自动提取Schema:
SELECT table_name, column_name, data_type, column_commentFROM information_schema.columnsWHERE table_schema = 'your_database';
2. Schema表示方式
为了让模型理解Schema,通常有三种常见的表示方式:
图结构(Graph)表示:用节点表示表,边表示关联关系;
文本描述(Text)表示:将Schema转为人类可读描述;
向量(Embedding)表示:将表名、字段名嵌入向量空间,建立语义关系。
这三种方式常结合使用,保证模型既理解结构,又能匹配语义。
3. Schema与自然语言对齐
核心目标是:让系统知道自然语言中的词,对应数据库中的哪一列。
例如:
“客户订单数” → 表 orders 中字段 customer_id “销售额” → 表 sales 中字段 amount
这种语义到Schema的映射通常通过相似度计算与命名实体识别实现。
在实际落地中,很多企业还会维护一份“业务词汇表”,用于手动校准关键字段对应关系,提高命中率。
四、自然语言理解与意图识别
1. 从语言到结构化语义
自然语言理解模块的目标,是把模糊的人类语言转化为结构化语义。
主要方法包括:
2. 用户意图分类
系统需要判断用户要执行哪种操作:
意图类型 | 示例 | 对应SQL |
|---|
查询数据 | 查询昨日订单总额 | SELECT |
构造数据 | 生成10条测试数据 | INSERT |
更新数据 | 修改产品价格 | UPDATE |
校验数据 | 检查数据一致性 | SELECT + 比对 |
3. 提升理解能力:Prompt + Fine-tuning
对于复杂场景,仅靠零样本Prompt很难覆盖所有语义。
企业可结合两种方式优化模型:
这使模型能理解复杂指令,例如:
“帮我查一下上月新注册但未下单的用户数。”
五、SQL生成引擎:从意图到SQL
1. 基于规则与模板的SQL生成
对于常见的查询模式(如求和、计数、过滤等),可以提前定义模板规则。
示例:
输入:统计上周销售额→ 模板:SELECT SUM(amount) FROM sales WHERE date BETWEEN {start} AND {end};
这种方式速度快、可控,但灵活性有限。
2. 基于LLM的生成机制
在复杂场景下,采用大模型生成SQL是关键。
实现步骤:
将自然语言、Schema信息共同嵌入Prompt;
模型输出SQL语句;
系统执行语法校验与Schema约束检查;
必要时回退到规则生成。
这种结合方式(LLM + 规则校验)既保留智能性,又确保可执行。
3. 处理复杂SQL
通过Prompt模板设计,可支持:
JOIN关联(跨表查询)
GROUP BY聚合
HAVING过滤
ORDER BY与LIMIT排序
嵌套子查询
例如:
“查询每个地区的平均销售额高于全国平均水平的客户数。” 系统生成:
SELECT region, COUNT(DISTINCT customer_id)FROM salesGROUP BY regionHAVING AVG(amount) > ( SELECT AVG(amount) FROM sales);
六、智能体在测试与数据任务中的应用
1. 自动化测试数据构造
输入:
“生成100条上海地区订单数据,金额随机,日期为本月。”
智能体自动生成插入SQL,并可通过参数控制生成规则(如数据分布、约束条件)。
通过集成Mock数据工具(如Faker),还能直接生成虚拟数据入库。
2. 自动化数据验证
输入:
“验证订单表和发票表中的金额是否一致。”
系统生成比对SQL,自动执行验证:
SELECT o.order_id, o.amount AS order_amt, i.amount AS invoice_amtFROM orders oJOIN invoice i ON o.order_id = i.order_idWHERE o.amount <> i.amount;
输出结果直接以表格展示,验证清晰、准确。
3. 多数据源支持与统一抽象层
在企业落地时,往往存在多种数据库(MySQL、Oracle、PostgreSQL、Hive等)。
智能体可通过方言适配层(Dialect Layer)统一不同SQL方言,自动切换执行引擎,真正做到一次输入,多源执行。
七、结果呈现与交互优化
1. 查询结果可视化
查询结果不仅返回数据表,还能自动生成图表:
折线图(趋势类数据);
柱状图(分组统计);
饼图(比例展示)。
并自动生成简短总结语句,如:
“本月销售额较上月增长12.8%,增长主要来自华东地区。”
2. 错误处理与智能反馈
执行失败时,智能体不会只返回SQL错误码,而是解释问题:
“字段amounts不存在,是否指amount?” “JOIN条件缺少主键字段,请确认表关联关系。”
用户点击修正建议即可自动修复。
3. 模型持续优化
系统可收集用户操作与反馈日志,自动训练强化模型。
例如,统计用户修正后的SQL,用于微调模型,提高生成准确率。
通过不断循环学习,智能体的表现越用越准。
八、总结
从“懂SQL”到“懂业务”,Text2SQL数据分析智能体的核心价值,不仅在于“让不会写SQL的人也能查数据”,更在于让业务分析真正回归业务本身。
当自然语言成为查询的接口,技术与业务的边界将被彻底打破。
在未来,测试人员、产品经理、业务分析师都能通过自然语言直接驱动数据库,这将让数据洞察的效率提升一个数量级。
一文看懂:如何才能使AI Agent 平台架构在业务线“跑起来”!
很多公司做Agent的过程,像极了“先买模型再想流程”的团队:先把大模型拉上来,用户一问,模型就开始“瞎扯”。但真正能与业务快速融合、稳定运行的并不多。几个月后,项目变成了“成本高、上线慢、效果不稳定”的demo堆栈。真正能把Agent做成业务产出的公司,有两点共同习惯:
先把管控和可运维做好,再上复杂模型(把“会做事”放在“会说话”之前);
把能力模块化、把数据资产化(知识、技能、模型、向量都要可管理、可追溯)。
本文从工程和产品的双重视角,基于一套成熟的Agent平台架构,讲清楚如何把“能力模块化、部署分布式、接入多渠道、以数据与模型为核心”落到实处。
一、为什么要用模块化 + 分布式的Agent平台?
一句话概括:业务千变万化,技术必须可拆、可扩、可运维。现实里,客服、问答、流程自动化、运维助手每个场景的需求和SLA差别很大。如果把所有能力堆在一张大系统里,既难以迭代,也难以保证稳定性。模块化把能力拆成“接入层(多渠道)→ 引擎层(Agent 服务)→ 管理层(发布/技能/知识)→ 算法层(大模型/RAG)→ 存储(模型/向量/业务库)→ 运维(MLOps)”这样的清晰层次;分布式则保证每一层可以弹性扩缩、独立部署与隔离故障。图中清晰展示的正是这种理念:前端多样化接入,后端能力服务化,数据与模型统一托管。
二、分层拆解:每一层该负责什么
1) 多渠道接入(IM / 微信小程序 / WebChat)
职责:面向用户的第一触点,负责会话建立、会话管理与基础鉴权。
落地要点:
采用统一的 WebSocket 或长连接网关,让不同渠道走同一条会话通道,便于会话状态共享与追踪。
在接入层做必要的策略隔离(不同渠道的消息规范与速率控制),避免单点流量突发影响核心引擎。
设计好消息格式和事件体系(如:用户输入、系统指令、会话元信息),让下游Agent引擎能无缝消费。
2) Agent 服务引擎(实时通信 + 执行层)
职责:运行Agent实例,处理意图识别、任务规划、对话管理、技能调用。
落地要点:
采用微服务/容器化部署(K8s),确保横向扩展与故障自动恢复。
服务内置轻量任务规划器(Task Planner),支持把复杂业务拆成多个技能(Skill)串联执行。
引入“发布管理”,区分配置面(管理端)和运行时(引擎),发布流程需支持回滚与灰度。
3) Agent 管理平台(发布管理/技能/知识库/提示词工程)
职责:可视化运营层,支持内容/能力的管理与快速迭代。
落地要点:
技能管理:把业务动作(查询订单、拉取工单、发起退款)做成可组合的技能库,业务方可以拖拽或通过API调用。
知识库管理+RAG:知识库要支持向量化、版本管理、权限控制;RAG服务与向量库(ES)对接,实现上下文检索。
提示词工程(Prompt Engineering):提供可复用的Prompt模板、变量注入与安全白名单,避免随意拼接导致模型输出风险。
意图管理:建立高质量意图集合与测试用例,定期回测,避免冷启动带来的识别误差。
4) 算法平台(大模型推理服务 + RAG 服务)
职责:提供可调用的推理能力与检索增强服务。
落地要点:
推理服务采用模型服务化(Model Server),与 MLOps 对接,实现模型上线/回滚/灰度。
RAG 服务需要低延迟的向量检索与高质的检索策略(混合检索、重排序),并与知识库同步。
对成本敏感场景,可采用多模型策略:小模型做意图/槽位,大模型做生成/复杂推理。
5) 模型库 / 向量库(数据与模型资产)
职责:统一托管模型、索引与企业数据。
落地要点:
6) MLOps(模型运维与治理)
职责:模型监控、性能回归检测、CI/CD 到推理端、资源管理。
落地要点:
三、关键能力与非功能要求(从图里提炼的设计词)
灵活可扩展:模块化实现能力拆分,依赖容器化与弹性伸缩。
安全加密通讯:前端到引擎、引擎到后端的所有通道使用 TLS/加密,并实现鉴权与权限隔离。
实时反馈系统:支持会话级别的回执、交互埋点与快速纠偏(人工接入/策略回退)。
高可用与容错:服务化部署、API网关限流、熔断与降级策略。
审计与合规:知识库变更记录、模型版本控制与问答溯源链路保存。
四、文件与交付物:为什么要同时支持“文档、图表、代码”?
在把Agent能力交付给业务时,单靠API或一个页面是不够的。图中强调了既有LCDP、MIS平台的对接,又有数据库与模型库,这意味着交付需同时包含:
文档:产品/运营手册、接入文档、能力说明、提示词库使用规范。
图表:流程图、调用链时序图、SLA与性能曲线,便于运维与业务侧评估。
代码:SDK、示例、自动化部署脚本、技能模板,方便工程化落地与二次开发。
这三者合一,能让业务侧从“会用”到“会管理”再到“会迭代”。
五、场景实战举例
下面以“微信小程序客服+知识库问答+工单触发”为例,给出落地步骤:
接入与会话打通:在微信小程序侧嵌入WebChat组件,统一走WebSocket网关,完成用户鉴权。
意图与知识对接:Agent 管理中配置“产品咨询”“售后工单”两个意图;知识库导入FAQ并向量化入库(ES)。
技能编排:把“问答检索(RAG)→ 若无法命中则触发工单技能”做成任务流水,发布到Agent服务引擎。
推理与检索策略:优先使用RAG检索命中高置信度答案,低置信度时调用小模型做意图确认,再决定是否发起工单。
上线与灰度:通过发布管理进行灰度推送(先10%的流量),观察响应时间、检索命中率与人工接入率。
迭代:根据在线日志和用户反馈优化提示词、补充知识库、微调模型或替换检索策略。
六、实施顺序与优先级建议(避免常见误区)
先落“管控能力”再上大模型:优先把知识库、意图管理、技能库、发布流程搭好,再引入大模型做增强。
别把全部问题都交给生成模型:用检索(RAG)+ 生成混合策略,保证可控性与可审计性。
运维与监控不可或缺:上线前设好SLO/SLA、监控项与报警策略,别等用户投诉才开始看日志。
业务侧参与:把业务方当作共建者,授权其操作技能/知识的灰度发布权限,缩短迭代闭环。
七、总结
把技术能力变成业务价值的最后一公里。把“前端多渠道、Agent 引擎、管理平台、算法平台、模型与向量库、MLOps”画成一张结构化的地图,核心要义也很明确:能力要模块化,数据与模型必须统一治理,运维与发布机制要到位,前端接入要统一而灵活。只有这样,AI Agent 才能从“实验室的魔法”变成“业务线的生产力”。
如果你正在筹建或改造Agent平台,可先从以下三件事入手:
建立统一的接入与会话网关(WebSocket + API 网关);
搭建可视化的Agent管理台(技能、知识、发布、提示词);
把检索(向量库+RAG)作为首席防线,确保结果可追溯与可控。
最后一句话:把「灵活可扩展」、「安全加密通讯」和「实时反馈」落实到工程实践里,才能真正让AI Agent替业务“做事”,而不是只会“讲道理”。
想打造自己的 OpenClaw?从零构建一个可记忆、可扩展、可追踪的本地 AI Agent
我受够了那些像“黑盒”一样的 AI 助手:你不知道它到底记住了你多少秘密,更不知道它在调用工具时后台流转了什么数据。这种“盲目信任”的代价,往往是牺牲了透明度与自主权,还有就是有的企业禁止部署使用openclaw。这就是我折腾出 AgentClaw 的初衷。从 OpenClaw 到 Hermes-Agent,我一直在思考如何让 Agent 真正落地到本地。现在,我整理出了这个基本雏形:代码量精简到核心逻辑仅约 500 行 Python,但它能让你实现真正的“数据主权”——记忆是桌面上随手可改的 Markdown,技能是文件夹里拖进即用的说明书。跑完这篇教程,你得到的将不再是一个云端租借的对话框,而是一个你完全可控、真正属于自己的 AI 大脑。
在开始写代码之前,我想先花几分钟解释整个系统的工作方式。这不是废话,架构没搞明白,后面写代码的时候会一直懵。最上面是前端,用 Next.js 做的对话界面,可选,没有它也能用 API 跑起来。中间是 FastAPI 后端,跑在本地 8002 端口,负责处理请求、读写文件、把事件推给前端。最底下是 Agent 运行时,用 LangChain 构建,这是真正干活的地方。对大多数人来说,最陌生的可能是 Agent 运行时这一层。简单说就是:它拿到你的问题,决定用哪个工具,调用工具,拿到结果,再决定下一步,直到给出最终回答。整个过程是一个循环,不是一次性的。整个系统里最关键的设计,是 System Prompt 的构成方式。每次对话开始,后端会把 6 个本地文件拼成一个完整的 System Prompt 扔给 Agent:SKILLS_SNAPSHOT.md ← 告诉 Agent「你会什么」
SOUL.md ← 性格和语气设定
IDENTITY.md ← 自我认知(它知道自己在哪里运行)
USER.md ← 你是谁,你的背景信息
AGENTS.md ← 行为准则,包含技能调用协议
MEMORY.md ← 长期记忆,你告诉它的一切
这 6 个文件全部是本地 Markdown,用 VS Code 或者记事本随时可以打开改。这就是所谓「透明可控」的根基——Agent 的「大脑」不是云端某台服务器里的黑盒,而是你桌面上几个文本文件。
很多人第一反应是:给 Agent 加个技能,不就是写个 Python 函数吗?这当然可以,但问题是每加一个功能就要改后端代码,而且如果你有几十个技能,全部描述都塞进 System Prompt,Token 会爆。AgentClaw 的做法不一样。技能不是函数,是说明书。每个技能是一个文件夹,里面放一个 SKILL.md,描述「什么情况下用这个技能」、「分几步做」、「调哪个工具」。System Prompt 里只放技能的名字和一句描述(Level 1,每个技能大约 30 个 Token),Agent 看到用户问了个相关问题,先去把这个技能的说明书读进来(Level 2,read_file 工具),然后照着说明书用底层工具执行(Level 3)。用户:「帮我查北京今天天气」
↓
Agent 扫 SKILLS_SNAPSHOT → 找到 get_weather 技能
↓
调用 read_file("get_weather/SKILL.md")
↓
读到:「用 fetch_url 访问 https://wttr.in/Beijing?format=j1,解析 JSON...」
↓
调用 fetch_url(url)
↓
解析数据 → 返回「北京:晴,22°C,湿度 45%」
好处是:想加一个新技能,只需要建一个文件夹、写一个 SKILL.md,重启服务,Agent 就自动获得了这个能力。不用改任何后端代码。
除了技能系统,Agent 出厂自带 6 个底层工具:前四个是基础能力,这篇文章都会实现。后两个(RAG 检索和浏览器自动化),先上最简单能运行的AgentClaw。
前置条件不多:Python 3.10 以上,如果你要跑前端再加一个 Node.js 18+。mkdir agentclaw && cd agentclaw
mkdir -p backend/{api,graph,tools,workspace,skills,memory,sessions}
cd backend
pip install fastapi uvicorn \
langchain langchain-community langchain-experimental langchain-openai \
html2text python-frontmatter python-dotenv pydantic
配置模型。在 backend/ 下建一个 .env:# 用 DeepSeek(便宜,工具调用支持不错)
OPENAI_BASE_URL=https://api.deepseek.com/v1
OPENAI_API_KEY=your-deepseek-key
MODEL_NAME=deepseek-chat
# 或者 OpenAI
# OPENAI_API_KEY=sk-...
# MODEL_NAME=gpt-5.4
# 或者直连 Claude(指令遵循最稳定)
# ANTHROPIC_API_KEY=sk-ant-...
# MODEL_NAME=claude-sonnet-4-6
模型选哪个?开发调试期间用 DeepSeek 就好,够便宜,工具调用也稳。生产环境或者对稳定性要求高的场景,claude-sonnet-4-6 是目前表现最稳的。gpt-5.4 也不错,就是比 DeepSeek 贵不少。agentclaw/
└── backend/
├── .env
├── app.py
├── api/
│ └── chat.py
├── graph/
│ ├── agent.py
│ └── prompt_builder.py
├── tools/
│ ├── read_file_tool.py
│ ├── fetch_url_tool.py
│ ├── terminal_tool.py
│ └── python_repl_tool.py
├── workspace/ ← SOUL / IDENTITY / USER / AGENTS.md
├── memory/ ← MEMORY.md
└── skills/ ← 技能文件夹,一个技能一个子目录
先把 6 个 System Prompt 文件建出来。这步很多人会跳过,直接去写代码,结果 Agent 行为乱七八糟,最后才发现是这里没配好。backend/workspace/AGENTS.md——这是最重要的一个,必须写清楚:# AgentClaw 行为准则
## 技能调用协议(SKILL PROTOCOL)
你拥有一个技能列表(见 SKILLS_SNAPSHOT),其中列出了你可以使用的能力及对应的文件路径。
**当用户请求的任务匹配某个技能时,你必须严格遵守以下步骤,不能跳过:**
1. 第一步行动永远是调用 `read_file` 工具,读取该技能 location 路径下的 SKILL.md
2. 仔细阅读文件中的步骤和示例
3. 根据文件指示,使用对应的 Core Tools(terminal / python_repl / fetch_url)执行任务
**绝对禁止**:在没有读取 SKILL.md 的情况下,猜测技能的用法或直接执行操作。
## 记忆协议
当用户告知你重要的个人信息、偏好或背景时,询问是否需要记录。
## Canvas 输出协议
当用户请求创建图表、网页、仪表盘等可视化内容时,将完整 HTML 包裹在
`<openclaw-canvas>` 标签中输出。HTML 必须自包含(所有 CSS/JS 写在文件内)。
为什么要这么强调「必须先读文件」?因为大模型很聪明,它经常「猜」到了怎么做并直接干,绕过了读 SKILL.md 这一步。这在简单任务上没问题,但对于复杂技能(比如操作 Word 文档、调特定 API),绕过说明书几乎必然出错。所以要用命令式语气,把这个约束写死。# backend/workspace/SOUL.md
你是 AgentClaw,一个运行在用户本地的 AI 助手。
你的核心特质:诚实、透明、高效。
执行操作时,你会主动告知用户你在做什么,不做任何隐瞒。
# backend/workspace/IDENTITY.md
你由用户部署在本地计算机上运行,所有数据存储在用户自己的文件系统中。
你的技能目录:backend/skills/
你的长期记忆:backend/memory/MEMORY.md
你的配置文件:backend/workspace/
# backend/workspace/USER.md
# 关于用户
(请填写你的个人信息,Agent 会据此了解你)
姓名:
职业:
技术栈:
常用语言:中文
其他偏好:
# backend/memory/MEMORY.md
# 长期记忆
(初始为空,Agent 会在你告知重要信息后写入此处)
backend/tools/read_file_tool.py这是整个技能系统的眼睛,必须加路径限制,否则 Agent 有可能读到你机器上的任意文件。import os
from langchain_core.tools import tool
from langchain_community.tools.file_management import ReadFileTool
# root_dir 必须用绝对路径,相对路径在某些场景下会出问题
_BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
_skills_reader = ReadFileTool(root_dir=os.path.join(_BASE_DIR, "skills"))
_workspace_reader = ReadFileTool(root_dir=os.path.join(_BASE_DIR, "workspace"))
_memory_reader = ReadFileTool(root_dir=os.path.join(_BASE_DIR, "memory"))
@tool
def read_file(file_path: str) -> str:
"""
读取本地文件内容。用于读取技能定义文件(SKILL.md)或工作区配置。
路径规则:
- 技能文件: "get_weather/SKILL.md"(相对 skills/ 目录)
- 工作区文件: "workspace/AGENTS.md"(加 workspace/ 前缀)
- 记忆文件: "memory/MEMORY.md"(加 memory/ 前缀)
"""
# 防止路径穿越攻击
if".."in file_path:
return"Error: 不允许使用 .. 访问上级目录。"
try:
if file_path.startswith("workspace/"):
return _workspace_reader.invoke({"file_path": file_path[len("workspace/"):]})
elif file_path.startswith("memory/"):
return _memory_reader.invoke({"file_path": file_path[len("memory/"):]})
else:
return _skills_reader.invoke({"file_path": file_path})
except Exception as e:
return f"Error: {str(e)}"
backend/tools/fetch_url_tool.py原生的 RequestsGetTool 会返回原始 HTML,几千行的 <div> 和 <script> 扔给模型,Token 哗哗地烧。用 html2text 转成 Markdown,能节省 60-70% 的 Token。import html2text
from langchain_core.tools import tool
from langchain_community.tools import RequestsGetTool
from langchain_community.utilities import TextRequestsWrapper
_requests = RequestsGetTool(
requests_wrapper=TextRequestsWrapper(),
allow_dangerous_requests=True
)
_h2t = html2text.HTML2Text()
_h2t.ignore_links = False
_h2t.ignore_images = True
_h2t.body_width = 0# 不自动换行
@tool
def fetch_url(url: str) -> str:
"""
发起 HTTP GET 请求,获取指定 URL 的内容。
HTML 页面会自动转换为 Markdown 格式以节省 Token。
内容限制 3000 字符。
"""
try:
raw = _requests.invoke({"url": url})
if raw and ("<html"in raw[:500].lower() or"<body"in raw[:500].lower()):
result = _h2t.handle(raw)
else:
result = raw
return result[:3000]
except Exception as e:
return f"Error fetching {url}: {str(e)}"
backend/tools/terminal_tool.pyShell 工具是把双刃剑,加黑名单是最低限度的安全措施。生产环境建议放到 Docker 容器里跑。import re
from langchain_core.tools import tool
from langchain_community.tools import ShellTool
_shell = ShellTool()
# 高危命令正则黑名单
_BLACKLIST = [
r"rm\s+-rf",
r"\bsudo\b",
r"chmod\s+777",
r">\s*/dev/",
r"\bmkfs\b",
r"\bdd\b.+if=",
r"(curl|wget).+\|\s*(ba)?sh",
r":\(\)\{.*\}", # fork bomb
]
@tool
def terminal(command: str) -> str:
"""
在受限的安全沙箱中执行 Shell 命令。
高危命令(rm -rf、sudo 等)会被拦截。
命令输出限制 2000 字符。
"""
for pattern in _BLACKLIST:
if re.search(pattern, command, re.IGNORECASE):
returnf"拒绝执行:命令匹配高危规则 [{pattern}]"
try:
result = _shell.invoke({"commands": [command]})
return str(result)[:2000]
except Exception as e:
return f"Error: {str(e)}"
backend/tools/python_repl_tool.pyfrom langchain_core.tools import tool
from langchain_experimental.tools import PythonREPLTool
_repl = PythonREPLTool()
@tool
def python_repl(code: str) -> str:
"""
执行 Python 代码并返回结果。
适用于数学计算、数据处理、文件操作、生成图表等任务。
变量在同一会话内保持,可以分步执行。
"""
try:
result = _repl.invoke({"query": code})
return str(result)[:3000]
except Exception as e:
return f"Error: {str(e)}"
注意 PythonREPLTool 在 langchain_experimental 包里,忘了装的话启动会报 ImportError。
这个模块在 Agent 启动时运行,扫描 skills/ 目录,把每个技能的名字和描述提取出来,生成一份「技能菜单」注入 System Prompt。backend/tools/skills_scanner.pyimport os
import frontmatter # pip install python-frontmatter
def generate_skills_snapshot(skills_dir: str = None) -> str:
"""
扫描技能目录,生成 XML 格式的技能快照。
只提取 name 和 description,不把完整文档都塞进来。
"""
if skills_dir isNone:
base = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
skills_dir = os.path.join(base, "skills")
ifnot os.path.exists(skills_dir):
return"<available_skills></available_skills>"
entries = []
for skill_name in sorted(os.listdir(skills_dir)):
skill_md = os.path.join(skills_dir, skill_name, "SKILL.md")
ifnot os.path.isfile(skill_md):
continue
try:
post = frontmatter.load(skill_md)
name = post.get("name", skill_name)
description = post.get("description", "详见技能文件")
except Exception:
name = skill_name
description = "详见技能文件"
entries.append(
f" <skill>\n"
f" <name>{name}</name>\n"
f" <description>{description}</description>\n"
f" <location>./{skill_name}/SKILL.md</location>\n"
f" </skill>"
)
inner = "\n".join(entries) if entries else" <!-- 暂无技能 -->"
return f"<available_skills>\n{inner}\n</available_skills>"
为什么用 XML 格式而不是 JSON 或纯文本?Claude 系列的模型对 XML 结构的路由准确率明显更高——这是 Anthropic 自己在提示词工程文档里提的,实测确实有差异。
backend/graph/prompt_builder.pyimport os
from tools.skills_scanner import generate_skills_snapshot
def _read(path: str, max_chars: int = 20000) -> str:
ifnot os.path.exists(path):
return""
try:
with open(path, encoding="utf-8") as f:
content = f.read()
if len(content) > max_chars:
return content[:max_chars] + "\n\n...[内容过长,已截断]"
return content
except Exception:
return""
def build_system_prompt() -> str:
"""
动态拼接 6 个部分,构建完整 System Prompt。
如果某个文件不存在,对应部分留空,不报错。
"""
base = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
parts = [
# Part 1: 技能快照(动态生成,不从文件读)
"# 你的能力清单\n\n" + generate_skills_snapshot(),
# Part 2-6: 工作区文件
_read(os.path.join(base, "workspace", "SOUL.md")),
_read(os.path.join(base, "workspace", "IDENTITY.md")),
_read(os.path.join(base, "workspace", "USER.md")),
_read(os.path.join(base, "workspace", "AGENTS.md")),
_read(os.path.join(base, "memory", "MEMORY.md")),
]
prompt = "\n\n---\n\n".join(p for p in parts if p.strip())
# 总长度保护:超 40000 字符时截断(主要是 MEMORY.md 可能很长)
if len(prompt) > 40000:
prompt = prompt[:40000] + "\n\n...[System Prompt 已截断]"
return prompt
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from tools.read_file_tool import read_file
from tools.fetch_url_tool import fetch_url
from tools.terminal_tool import terminal
from tools.python_repl_tool import python_repl
from graph.prompt_builder import build_system_prompt
load_dotenv()
CORE_TOOLS = [read_file, fetch_url, terminal, python_repl]
def create_agent_executor() -> AgentExecutor:
llm = ChatOpenAI(
model = os.getenv("MODEL_NAME", "gpt-4o"),
temperature= 0,
streaming = True,
api_key = os.getenv("OPENAI_API_KEY"),
base_url = os.getenv("OPENAI_BASE_URL") orNone,
)
system_prompt = build_system_prompt()
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
MessagesPlaceholder("chat_history", optional=True),
("human", "{input}"),
MessagesPlaceholder("agent_scratchpad"),
])
agent = create_tool_calling_agent(llm, CORE_TOOLS, prompt)
return AgentExecutor(
agent = agent,
tools = CORE_TOOLS,
verbose = True,
max_iterations = 12,
handle_parsing_errors = True,
return_intermediate_steps = True,
)
max_iterations=12 是个经验值。设太小,复杂任务做到一半会提前停;设太大,出了 bug 的时候 Agent 会在那里循环调工具,Token 烧个不停。12 对大多数任务来说够用。
Step 6:FastAPI 入口与 SSE 流式输出这是最关键的接口,负责把 Agent 的执行过程实时推送给前端。import json
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from graph.agent import create_agent_executor
app = FastAPI(title="AgentClaw", version="1.0.0")
app.add_middleware(
CORSMiddleware,
allow_origins=["http://localhost:3000", "http://localhost:3001"],
allow_methods=["*"],
allow_headers=["*"],
)
class ChatRequest(BaseModel):
message: str
session_id: str = "default"
# 简单的内存会话历史,重启后清空
# 生产环境改成读写 sessions/{id}.json
_histories: dict = {}
@app.post("/api/chat")
asyncdef chat(req: ChatRequest):
asyncdef stream():
executor = create_agent_executor()
history = _histories.get(req.session_id, [])
full_output = ""
try:
asyncfor event in executor.astream_events(
{"input": req.message, "chat_history": history},
version="v2"
):
kind = event.get("event", "")
if kind == "on_chat_model_stream":
chunk = event["data"]["chunk"].content
if chunk:
full_output += chunk
# 检测是否包含 Canvas HTML
if (
"<openclaw-canvas>"in full_output
and"</openclaw-canvas>"in full_output
):
s = full_output.find("<openclaw-canvas>")
e = full_output.find("</openclaw-canvas>") + len("</openclaw-canvas>")
yieldf"event: canvas\ndata: {json.dumps({'html': full_output[s:e]})}\n\n"
else:
yieldf"event: token\ndata: {json.dumps({'text': chunk})}\n\n"
elif kind == "on_tool_start":
payload = {
"tool": event["name"],
"input": str(event["data"].get("input", ""))[:300],
}
yieldf"event: tool_start\ndata: {json.dumps(payload)}\n\n"
elif kind == "on_tool_end":
payload = {
"tool": event["name"],
"output": str(event["data"].get("output", ""))[:300],
}
yieldf"event: tool_end\ndata: {json.dumps(payload)}\n\n"
# 更新会话历史(最多保留 20 轮)
history.append({"role": "human", "content": req.message})
history.append({"role": "assistant", "content": full_output})
_histories[req.session_id] = history[-40:]
yieldf"event: done\ndata: {json.dumps({'ok': True})}\n\n"
except Exception as e:
yieldf"event: error\ndata: {json.dumps({'error': str(e)})}\n\n"
return StreamingResponse(
stream(),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"X-Accel-Buffering": "no", # 关掉 Nginx 缓冲,否则流式输出会卡住
},
)
@app.get("/api/health")
def health():
return {"status": "ok"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8002, reload=True)
X-Accel-Buffering: no 这个头如果忘了加,在 Nginx 后面部署时 SSE 会攒够一批数据才推,出来的效果不是流式,是一段一段蹦出来的。本地开发看不出来,部署上去才发现,找半天 bug。
mkdir -p backend/skills/get_weather
backend/skills/get_weather/SKILL.md---
name: get_weather
description: 获取指定城市的实时天气信息。当用户询问天气、气温、降雨、风速等信息时使用此技能。
version: 1.0.0
---
# 天气查询
## Usage
当用户询问任何城市或地区的天气、温度、降水情况时,使用此技能。
## Steps
1. 从用户消息中提取城市名称
2. 如果是中文城市名,转换为对应英文(如「北京」→「Beijing」)
3. 使用 `fetch_url` 访问以下接口:
https://wttr.in/{城市英文名}?format=j14. 从返回的 JSON 中提取:
- `current_condition[0].temp_C`:当前温度(°C)
- `current_condition[0].weatherDesc[0].value`:天气状况
- `current_condition[0].humidity`:湿度(%)
- `current_condition[0].windspeedKmph`:风速(km/h)
5. 用自然语言回复用户,格式参考示例
## Examples
**User**:北京今天天气怎么样?
**Assistant**:
(调用 fetch_url: https://wttr.in/Beijing?format=j1)
北京当前天气:晴,气温 22°C,湿度 45%,风速 15 km/h。
## Considerations
- 如果 API 返回错误,尝试用不同的英文拼写重试一次
- 不存在的城市名会返回空数据,告知用户并建议换一种写法
看到 Application startup complete 就说明跑起来了。
curl -X POST http://localhost:8002/api/chat \
-H "Content-Type: application/json" \
-d '{"message": "帮我查一下北京的天气", "session_id": "test"}' \
--no-buffer
event: tool_start
data: {"tool": "read_file", "input": "get_weather/SKILL.md"}
event: tool_end
data: {"tool": "read_file", "output": "---\nname: get_weather\n..."}
event: tool_start
data: {"tool": "fetch_url", "input": "https://wttr.in/Beijing?format=j1"}
event: tool_end
data: {"tool": "fetch_url", "output": "{\"current_condition\":[{\"temp_C\":\"22\"..."}
event: token
data: {"text": "北京当前天气:"}
event: token
data: {"text": "晴,气温 22°C,湿度 48%,风速 12 km/h。"}
event: done
data: {"ok": true}
注意看 tool_start 那两条。第一个工具调用是 read_file——它先去读了技能说明书。第二个才是 fetch_url——照着说明书去拉数据。这个顺序是正确的,说明 AGENTS.md 里的技能调用协议生效了。如果你看到 Agent 直接调了 fetch_url 而跳过了 read_file,说明 AGENTS.md 写得不够强硬,或者模型太「聪明」觉得自己知道怎么做。可以在 AGENTS.md 里再加一句:**注意:即使你认为自己已经知道如何完成任务,也必须先读取 SKILL.md。这是不可违背的规定。**
现在试试扩展能力。假设我们想让 Agent 会查汇率:mkdir backend/skills/exchange_rate
新建 backend/skills/exchange_rate/SKILL.md:---
name: exchange_rate
description: 查询两种货币之间的实时汇率。用户询问汇率、换算时使用。
version: 1.0.0
---
# 汇率查询
## Usage
当用户询问货币汇率或需要换算金额时使用。
## Steps
1. 从用户消息中提取源货币和目标货币(如 USD、CNY、EUR、JPY)
2. 使用 `fetch_url` 访问:
https://open.er-api.com/v6/latest/{源货币}3. 从返回 JSON 的 `rates` 字段中找到目标货币的汇率
4. 如果用户提供了金额,计算换算结果
5. 回复当前汇率及换算金额(注明数据来源和时间)
## Examples
**User**:现在 1 美元能换多少人民币?
**Assistant**:
(调用 fetch_url: https://open.er-api.com/v6/latest/USD)
当前汇率:1 USD ≈ 7.24 CNY(数据来源 open.er-api.com,实时更新)
保存,重启服务。再发一条消息:「100 美元等于多少人民币?」Agent 会自动扫到新技能,读说明书,调 API,给你换算结果。全程不改后端一行代码。这就是技能系统最实用的地方——你只需要知道某个 API 怎么用,写一份说明书,Agent 就学会了。
现在 Agent 已经能查天气、查汇率了,但每次对话结束它就什么都忘了。这里要解决的就是长期记忆。原理很直接:在 AGENTS.md 的「记忆协议」里,告诉 Agent 什么情况下把信息写入 MEMORY.md。Agent 读了这个指令,当你说「我是做 Python 后端开发的」,它就会调 python_repl 或 terminal 把这条信息追加进去。你可以在 USER.md 里先填一部分固定信息,剩下的让 Agent 在对话中自动学习:# backend/workspace/USER.md
# 关于我
姓名:[你的名字]
职业:后端开发工程师
技术栈:Python、FastAPI、PostgreSQL
时区:UTC+8
偏好:
- 回答用中文
- 代码风格:PEP8,尽量加类型注解
- 不喜欢废话,直接给结论和代码
# 长期记忆
## 关于用户
- 职业:后端开发工程师,主要用 Python
- 偏好:简洁代码,讨厌过度注释,PEP8 风格
- 时区:UTC+8
## 项目信息
- 2026-05-01:正在开发 AgentClaw,一个本地 AI Agent 框架
- 2026-05-09:AgentClaw 后端已跑通,下一步做前端
## 用户偏好
- 技术问题直接给代码,不要先解释背景
- 回答语言:中文
每次启动 Agent,它都会把这个文件读进 System Prompt,「想起」你是谁、你在做什么。这才是真正的长期记忆。
Agent stopped due to max iterations通常是 AGENTS.md 写得太模糊,Agent 在循环调工具找不到出路。先看 verbose=True 打出来的日志,看它在循环干什么,然后在对应的 SKILL.md 或 AGENTS.md 里加更明确的指引。ReadFileTool 的 root_dir 必须用绝对路径。用 os.path.abspath() 计算,不要手写字符串。另外注意工作目录——从哪个目录启动 python app.py,相对路径的基准就是哪里。加两个响应头:Cache-Control: no-cache 和 X-Accel-Buffering: no。代码里已经有了,如果你用了其他反向代理,查一下它对应的禁用缓冲的配置。换更强的模型。DeepSeek 在大多数情况下够用,但碰上复杂的多步任务有时会「偷懒」。Claude 3.5 Sonnet 对指令的遵循最严格,出现这类问题首选换它。langchain_experimental ImportError单独装一下:pip install langchain-experimental,这个包在主包里没有,需要显式安装。
backend/requirements.txt:fastapi>=0.111.0
uvicorn[standard]>=0.30.0
langchain>=0.2.0
langchain-community>=0.2.0
langchain-experimental>=0.0.62
langchain-openai>=0.1.0
langgraph>=0.1.0
html2text>=2024.2.26
python-frontmatter>=1.1.0
python-dotenv>=1.0.0
pydantic>=2.7.0
这篇文章的代码跑起来之后,你有了一个可用的本地 Agent 后端:支持流式输出、支持技能扩展、有基础的长期记忆。前端——如果你想要对话界面,用 Next.js 14 起一个项目,连接 /api/chat 的 SSE 接口就行。前端还能做 Canvas 面板(把 Agent 生成的 HTML 渲染出来)、Memory 编辑页(直接改 MEMORY.md)、技能管理页。知识库 RAG——用 LlamaIndex 给 Agent 加一个 search_knowledge 工具,扫描本地 PDF/Markdown 文件建索引,这样 Agent 就能从你的笔记和文档里检索信息。浏览器自动化——browser-use 库配合 Playwright,让 Agent 真正能操控浏览器,填表单、截图、爬需要登录的页面。这个后续单独写一篇。会话持久化——现在会话历史只存在内存里,重启就没了。把它写进 sessions/{id}.json,就能保留完整对话历史。
Anthropic 官方有一个技能仓库 github.com/anthropics/skills,里面有写 Word 文档、操作表格、生成图表等现成技能,格式和这篇文章的 SKILL.md 完全兼容,可以直接拿来用。社区还有 agentskills.io 和 github.com/VoltAgent/awesome-agent-skills,里面有各种现成技能。
Harness Engineering 四大支柱,让 AI Agent 从 人工智障 变 神队友
让 AI 帮你写代码,它交出来的东西乍一看没毛病,跑起来也没报错。你觉得差不多了,合进主分支,上线。三天后,同事来找你:"诶,这个接口的错误格式怎么和别的不一样?" 你翻开代码一看——AI 自己造了一套 {"err": {"msg": "xxx"}} 的格式,和项目里其他接口的 {"error": "xxx"} 完全不一样。你回头去看 AI 的对话记录,发现你当时根本没说"错误格式要统一"。凭什么它要知道呢?又或者你让它清理临时文件,它把路径搞混了,差点执行了一条删库的命令。好在你眼疾手快叫停了——但下次呢?这类问题几乎每个重度使用 AI 编程的人都遇到过。大多数人的第一反应是:换个更强的模型?
2026 年 3 月,LangChain 团队在 Terminal Bench 2.0 基准测试上做了一个控制变量实验。他们想搞清楚一件事:同样的模型,改善"运行环境"能带来多大的提升?这个结论在行业里引发了不小的震动。它直接指向一个很多人还没意识到的问题:大多数 AI 编程的瓶颈,不在模型,在于你怎么用它。这套方法论,有一个正式的名字——Harness Engineering(驾驭工程)。它是 OpenAI、Anthropic、ThoughtWorks 等顶级团队在大量实践中沉淀出来的工程化体系,专门解决 AI Agent 在真实项目中"幻觉频发、越用越乱"的问题。核心思路用一句话说:模型决定 AI 的天花板,Harness 决定 AI 能不能稳定飞到那个高度。类比一下就清楚了:模型是赛车手,Harness 是赛道规则、维修站和安全护栏。再厉害的赛车手,上了没有护栏的烂路,也跑不快,甚至会翻车。Harness Engineering 有四根核心支柱。我们一根一根来拆。
每个项目都有大量"不言自明"的规矩——用 Testify 还是标准库跑测试、接口命名走 RESTful 还是 gRPC、.env 文件不能动、数据库连接必须走连接池。这些规矩在老员工之间是常识,从来不需要说。但 AI 每次开新会话,都是完全的空白状态。它不记得上次你告诉它什么,也不知道你们项目有哪些"隐性约定"。结果就是:你今天告诉它"别硬编码 DB 连接串",明天开新会话,它照样硬编码。解决方案并不复杂——在项目根目录放一个结构化的配置文件。Anthropic 体系叫 CLAUDE.md,OpenAI 体系叫 AGENTS.md。Agent 每次启动时自动读取,拿到项目的技术栈、常用命令、编码规范和行为禁区。你可以把它理解成"给 AI 写的新人入职第一天必读文档"——不是厚厚的百科全书,而是几条关键信息:这个项目用什么语言、测试怎么跑、哪些目录不能动、遇到数据库迁移先干什么。OpenAI 的 Codex 团队踩过这个坑。他们尝试过把所有信息塞进一个巨大的配置文件,结果失败了——上下文窗口是稀缺资源,500 行的说明书把真正有用的代码都挤出去了,AI 反而不知道哪些信息和当前任务相关。他们总结出来的黄金标准是:主文件 < 100 行,作为"目录",按需跳转子文档。AGENTS.md(~100行)→ 导航地图
├── docs/architecture.md → 架构设计
├── docs/conventions.md → 编码规范
└── 核心禁区和行为边界 → 关键约束
开源项目 Ghostty 的作者 Mitchell Hashimoto 分享过一个很实用的维护方法——他的配置文件里,每一行规则都对应过去一个 AI 犯过的真实错误。AI 犯错 → 分析根因 → 写成规则 → 加入配置 → 下次永不再犯
不是一开始就写出"完美的"配置文件,而是在实际使用中不断积累。这意味着你的 CLAUDE.md 会随着项目推进越来越"聪明",覆盖越来越多的边界情况。还有一个很多人不知道的细节——Claude Code 支持三层配置文件同时生效:- 全局层(~/.claude/CLAUDE.md):对你所有项目生效,适合放个人偏好——喜欢用什么语言回复、习惯什么代码风格
- 项目层(./CLAUDE.md):提交到 Git,团队共享,放技术栈、命令规范、约束边界
- 个人层(./.claude/local.md):不提交 Git,只对你自己生效,放在这个项目里你个人的特殊偏好
三层在 Agent 启动时自动合并,优先级是个人 > 项目 > 全局。这个设计和软件工程里"配置继承与覆盖"的模式完全一致——全局给默认值,项目覆盖团队约定,个人再覆盖个人偏好。用好这三层之后,还有三个误区要避开:写得越长越好(错,< 100 行是黄金标准);把 AI 本来就知道的常识也写进去(浪费上下文,只写项目特有的信息);写完就扔从不更新(应当像 Hashimoto 一样,每次犯错就补一条)。
CLAUDE.md 解决了"AI 不知道规矩"的问题,但还有一个更麻烦的问题:AI 知道规矩,但不一定遵守。你在 CLAUDE.md 里写了"禁止在 Handler 层直接查数据库",AI 在赶一个紧急功能的时候,发现走 Repository 层要多写两个方法——它走了捷径,直接 db.Raw("SELECT * FROM users").Scan(&users)。代码能跑,功能正常。CLAUDE.md 是建议,Hooks 是法律。建议可以忽略,法律不行。在 Hooks 之外,OpenAI 在 Codex 项目里走得更远——他们设计了一套六层分级约束体系,用自动化工具在每一层强制执行架构规则:Types → Config → Repo → Service → Runtime → UI
↑ ↑ ↑ ↑ ↑ ↑
每层只能依赖上层,严禁反向依赖
违反 → 结构测试自动报错 → Agent 被阻止
这不是一个检查清单,而是一套自动执行的"法律体系"。当 AI 试图在 UI 层直接调用 Types 层的内部实现(跳过了中间几层抽象),结构测试立即失败,告诉 AI:"违反分层规则,请通过 Service 层调用。"没有任何商量余地。如果你用过 Git,可能知道 Git Hooks——在 git commit 之前自动触发检查脚本。AI Agent 的 Hooks 是同样的概念:在 Agent 执行操作的前后,自动触发一段检查程序。通过就继续,不通过就拦截。AI 没有"选择忽略"的余地。这里有一个容易踩坑的细节:拦截操作的退出码必须是 2,不是 1。这个设计刻意区分了两种情况——退出码 1 代表"Hook 脚本自身出了问题"(被系统忽略,不影响主流程),退出码 2 才代表"Hook 有意拦截这个操作"。很多人写错退出码,以为自己加了防护,其实什么都没拦住。场景一:安全防火墙。 你让 AI 清理临时文件。它准备执行 rm -rf /tmp/project/*,没问题。但如果它把路径写错成了 rm -rf /,一个 PreToolUse Hook 会在 AI 执行命令之前被触发,检测到危险模式,立刻阻止——整个过程不到 10 毫秒,比人类的反应速度快得多。场景二:提交前质检。 AI 写完一段代码准备 git commit,Hook 检测到这个操作,自动先跑代码质量检查工具。发现有未处理的错误、空指针风险?拦截 commit,把检查报告反馈给 AI。AI 拿到报告自动修复,再次尝试提交——这次过了,放行。全程无需人类介入。场景三:任务完成通知。 你让 AI 跑一个需要 15 分钟的全量集成测试,然后去泡咖啡了。任务完成时,一个 Hook 自动触发桌面弹窗:"Claude Code 任务已完成"。这个 Hook 不拦截任何操作,它的唯一目的是改善开发者体验。普通 Hook 靠字符串匹配——但如果 AI 写了一段"功能等价"的危险代码怎么办?比如 shutil.rmtree('/') 和 rm -rf / 效果一样,但前者根本不包含 rm 这个关键词,字符串匹配抓不住。更高阶的做法是 Prompt Hook——不运行检查脚本,而是调用另一个 AI 做语义理解:- shutil.rmtree('/') ?理解代码语义,识别为递归删除根目录,发出警告
- logger.Info("Request headers: %v", r.Header) ?识别出 r.Header 可能含有 Authorization Token,判定为凭证泄露风险
- AI 把 API 返回格式从 {"data": [...]} 改成了 {"items": [...], "total": 100}?代码本身完全正确,字符串匹配毫无反应,但 Prompt Hook 能判断出:这是一个破坏性变更(breaking change),所有依赖这个字段名的客户端会直接崩溃——建议保持向后兼容或发新版本
最佳实践是双层防线:command Hook 处理速度快、零成本,用来过滤 99% 的已知危险模式;Prompt Hook 能力强但有延迟和 API 成本,专门兜住那些"看起来没问题但实际有隐患"的漏网之鱼。两者不是替代关系,而是互补的两道筛子。很多人以为给 AI 更多自由度,它能做更多事。OpenAI 的实践结论恰好相反——当你告诉 AI "用任何你觉得合适的方式实现这个功能",它面对无限可能性,选择的方差极大。但当你约束它"必须走 Service 层、遵循命名规范、接口必须有文档注解、测试覆盖率不低于 80%",它在这个收窄后的解空间里反而更容易找到正确答案。这和团队管理的经验类似:有明确编码规范的团队,代码质量通常优于"自由发挥"的团队。约束不是限制创造力,而是把创造力引导到有价值的方向。OpenAI 还在 linter 设计上加了一个精妙之处:自定义 linter 的错误消息同时也是修复指南。 AI 违反了某条规则,linter 不只说"错了",还告诉它怎么改——这等于把学习能力嵌进了约束体系。用约束的时候,有三个坑要避开:一是约束太多太细,AI 每一步都被拦截,效率反而下降,只约束真正危险或真正重要的行为;二是退出码搞错,用 exit 1 想拦截操作实际上什么都没拦(记住是 exit 2);三是只约束不解释,拦截了 AI 却不告诉它为什么被拦、该怎么修,好的约束应该同时是教学工具。
Anthropic 在他们的工程博客里用过一个很精准的比喻:Agent 每次新会话"开始时没有之前的记忆"——就像没有交接记录的轮班工程师。你想象一下:上午做了一半的工作,下午换了另一个工程师接手,没有任何交接文档。下午那个人怎么知道做到哪了?可能重做了上午已经完成的部分,可能继续了一个已经被证明不对的方向。反馈循环就是那份交接文档——确保 AI 在每一步都知道"做到哪了"、"做得对不对"、"下一步该做什么"。用"实现一个用户注册 API"来感受四层各自在哪里介入——即时反馈(写代码时):密码明文存储?直接写日志泄露 Token?代码格式不符合规范?这些问题应该在 AI 写代码的当下就被捕获,不是等到提交之后。构建反馈(提交时):单元测试跑不过、接口文档没写、邮件格式没有校验——这些是功能层面的缺陷,在构建阶段报出来。运行时反馈(上线后):并发高了之后响应时间变长、内存在某些情况下会泄漏——这类性能问题只有在真实负载下才能被发现。评审反馈(独立审查):没有限流,可能被暴力破解;注册成功后应该发一封确认邮件,AI 没想到——这类设计层面的遗漏,需要独立的审查者才能抓住。四层缺了任何一层,就意味着某类问题会"静默通过",直到造成实际损害。Anthropic 的两阶段会话协议:解决"失忆"问题Anthropic 在长时运行 Agent 的实践中,设计了一套专门解决"重启后不知道做到哪了"的协议。Phase 1,由 Initializer Agent 完成一次性的基础设施搭建,产出两个关键制品:init.sh(启动开发服务器的脚本)和 progress.txt(进度记录文件)。Phase 2,Coding Agent 接手,但每次启动新会话都要遵循一个固定的五步协议:1. pwd → 确认自己在哪
2. git log + progress.txt → 了解做到哪了
3. 选最高优先级的未完成功能 → 决定做什么
4. init.sh → 启动开发服务器
5. 跑一遍端到端测试 → 确认基线正常,再开始写代码
这个协议的精妙之处在于:Agent 不需要记住上一个会话做了什么,因为 git log 和 progress.txt 已经记录了一切。每次重启都能无缝接手,就像有了完整交接记录的轮班工程师。LangChain 在实践中发现了一个常见的 AI 故障模式,他们叫它 Doom Loop(死循环):AI 反复修改同一个文件,始终无法通过测试,陷入"编辑→失败→编辑→失败"的无限循环。举个具体例子:AI 要修复一个并发竞态条件。第一次加了 sync.Mutex,测试失败(死锁)。第二次改用 sync.RWMutex,还是失败。第三次加了 defer mu.Unlock(),又失败……它始终在"手动加锁"这个框架里打转,跳不出去。LangChain 的解决方案是一个中间件:当某个文件被编辑第 6 次仍未通过时,自动注入提示——"你已经修改这个文件 6 次了。考虑重新评估你的方法,也许应该用 sync.Map 或 channel 重构,而不是继续调整手动加锁的方式。"设计精妙的地方在于:不是强制 AI 停下来,而是给它一个"退一步看全局"的提示,让它自己决定是否改变策略。Anthropic 在 2026 年 3 月的最新工程实践中,把反馈循环推进到了一个新的高度。他们发现了一个根本性问题:让 AI 评估自己的工作,它会给自己打高分。 LLM 天然有"自我感觉良好"的偏见——即使产出很平庸,自评也倾向于宽容。解决方案不是"让 AI 学会自我批评"(这很难),而是干脆把评估交给独立的 AI。他们受 GAN(生成对抗网络)启发,设计了三 Agent 协作架构:Planner 把需求扩展为完整产品规格,Generator 按 Sprint 迭代实现功能,Evaluator 用客观标准独立打分。Anthropic 的原话说得很直接:"调校独立评估者的怀疑度,比让生成者对自己的工作保持批判性要容易得多。" 有了持续施压的独立评估者,Generator 才有动力做出真正优秀的设计,而不只是"能跑通测试就行"。
这是四根支柱里最容易被忽视的一根,但也可能是最有原创性的洞察。传统软件开发的质量问题主要是 bug——程序崩溃、逻辑错误、安全漏洞。这些问题有明确的报错信息,容易被发现。AI 生成的代码有一种截然不同的质量问题——不是某一行代码有错,而是整个代码库在缓慢退化,没有报错,不会崩溃,但每天都在悄悄变得更难维护。文档漂移。 函数 GetUser(id) 的注释写着"返回 {Name, Email}"。三个月后,AI 给它加了 Avatar 和 Role 字段,但没更新注释。又过了两个月,另一个 AI 依赖旧注释写了权限逻辑——忽略了 Role 字段,导致所有用户都被当成普通用户。半年后才被发现,到那时已有 12 个地方依赖了错误的假设。架构侵蚀。 项目约定"所有数据库查询必须通过 Repository 层"。AI 在实现一个紧急功能时嫌麻烦,直接在 Handler 层写了 db.Raw("SELECT * FROM users").Scan(&users)。代码能跑。下一个 AI 看到这个"先例",照着来。几个月后,30% 的数据库查询都绕过了规范层。等你要把数据库从 MySQL 迁到 PostgreSQL 的时候,才发现需要改的地方遍布各处。风格不一致。 周一的 AI 会话用了 {"error": "xxx"} 格式,周三用了 {"message": "xxx", "code": 400},周五又用了 {"err": {"msg": "xxx"}}。三种格式在同一个项目里共存,前端开发者每次调 API 都要猜今天用的是哪种。这三种问题每一个单独看都不严重,不会触发报错。但它们的累积效应是致命的——代码库变得越来越难以理解和修改,新加入的 AI 甚至人类开发者的理解成本越来越高。这就是"熵"的本质:不是爆炸性的灾难,而是渐进式的腐烂。OpenAI Codex 团队提出了一个精妙的类比:把代码熵的管理当作编程语言的垃圾回收(GC)来做——不是等技术债积累到爆发才一次性清理,而是持续运行、定期回收。他们的核心做法是:把团队的编码审美,编码为 linter 规则。比如,团队约定"所有 API 错误响应必须用统一的 ErrorResponse 结构体"。不是在 CLAUDE.md 里写"请统一错误格式"然后祈祷 AI 遵守,而是写一条 linter 规则,自动扫描所有 HTTP 响应体。一旦发现裸返回 {"error": "xxx"} 这种非标准格式,linter 直接报错,并告诉 AI:"错误:错误响应格式不符合规范,请使用 ErrorResponse{Code: ..., Message: ...}(详见 docs/api-conventions.md)"。注意这里的设计——错误消息本身就是修复指南。AI 不需要去翻文档就知道该怎么改。配套的还有专门的"清理 Agent"周期性运行,每天凌晨自动扫一遍:检查所有函数的注释是否与实际参数和返回值匹配(文档漂移检测)、检查是否有 Handler 层直接调用数据库的代码(架构侵蚀检测),生成"代码健康度日报"推送给团队。发现问题立即修复,不放进"以后再说"的 backlog——因为"以后"永远不会来。用 OpenAI 的话说:"品味捕获一次,强制执行无限次。"你只需要把对代码质量的判断标准编码为规则一次,机器就会持续不断地按照这个标准执行检查。人类的品味是珍贵而稀缺的——通过机械化,它的价值被无限放大了。这里有一条很多人要付出代价才能学到的教训,值得提前说清楚:原因很简单——今天需要复杂管线来完成的任务,明天可能一个提示词就搞定了。AI 能力的进化速度远超大多数人的预期。数据说话:Manus 团队在 6 个月内重构了 Harness 5 次,每次都是为了删掉过时的复杂逻辑;Vercel 删除了 80% 的 Agent 工具之后,效果反而更好;LangChain 一年内重架构 3 次。这些血泪教训都指向同一个设计原则:从简单开始,保持轻量,随时准备删掉你今天认为"很聪明"的设计。2025 年初,很多团队花了三周开发了复杂的"分步骤 JSON 解析器"来确保 AI 结构化输出。到了年底,模型原生就支持 JSON Mode 了。那个解析器瞬间变成了需要清理的遗留代码。如果它和十几个模块深度耦合,删除成本比开发成本还高。
同期通过换更强模型来提升成绩,通常能获得约 +6.8pp。也就是说,改善 Harness 的效果是换模型的整整两倍,而且不需要额外的模型费用。实验里还有一个有意思的发现,LangChain 把它叫做 Reasoning Sandwich:把推理预算拉到最高档(xhigh)时,AI 反而因为推理时间太长导致超时,成绩跌到 53.9%;调回"高"档(high)时,成绩是 63.6%。过度推理不如适度推理加上好的 Harness。 "让 AI 想得越久越好"这个直觉,也是个迷思。
Mitchell Hashimoto 这样描述自己现在的角色:"我是软件项目的架构师。代码结构、数据流设计、状态管理,仍然是我的责任。"但具体的代码编写,越来越多地交给了 AI。用一个更直白的类比:过去的工程师像厨师,亲手掌勺每道菜;现在的工程师像米其林主厨,设计菜谱、校准火候、验收出品——真正的价值在于系统,而不是某一道菜。这需要更高层次的思维方式:AI 擅长什么、哪里会犯错、怎样的约束能最小化错误、怎样的反馈循环能让系统越用越好。这些问题,比"怎么写这段代码"难多了,也重要多了。
在兴奋之余,有两个尖锐的质疑值得保持清醒,它们来自 Martin Fowler 团队:验证缺口。 Harness 擅长检查代码"合不合规"——风格、结构、类型。但对代码"业务逻辑是否正确"的验证仍然不够。Linter 能抓住格式问题,但抓不住"这个限流逻辑根本不适合这个业务场景"。遗留代码困境。 目前的成功案例几乎都是从零开始的新项目。对于已有数万行遗留代码的项目,如何让 AI 在其中安全工作,还没有成熟的方法论。还有一点需要说清楚:Harness Engineering 没有让软件开发变简单,它只是把复杂度从一个地方搬到了另一个地方。 "写代码的复杂度"转移为"设计环境的复杂度"。只不过,这个新的地方更适合人类发挥系统思维的优势。
- 在项目根目录建一个 CLAUDE.md,只写这个项目特有的、AI 猜不到的信息(控制在 100 行以内)
- 加一个 PreToolUse Hook 拦截危险命令,记得退出码用 2 而不是 1
- 让测试失败信息更具体——不只是"失败了",要告诉 AI 哪个用例、哪行断言、实际输出是什么
下次评估一个 AI 编程工具或团队的 AI 实践,换一个问题来问——不是"用了哪个模型",而是:"你们设计了什么约束机制?有没有独立的反馈和验证?"模型可以花钱买,Harness 需要你自己建。后者才是真正值钱的地方。
参考资料:LangChain《Improving Deep Agents with Harness Engineering》(2026.03)、Anthropic Agent 工程实践博客、Martin Fowler Blog: Harness Engineering、OpenAI Codex 工程实践分享、Mitchell Hashimoto 关于 Claude Code 使用方法的公开分享
Hermes Agent 深度解析:为什么它能“越用越懂你”?
15w+ Stars。每天 200+ 条 Issue。一个社区自发整理的"橙皮书"。这不是某家大厂发布会的配套声量,是一个叫 Hermes Agent 的开源项目,在 2026 年 2 月横空出世后,自己滚起来的。我最开始没太当回事。开源 Agent 项目每个月都有几个,GitHub Trending 刷一刷,热闹三天就散。但这个不一样——它在 Trending 上待了整整两周,然后安静下来,却没有消失。那些 Star 还在持续增加,社区里的讨论越来越具体、越来越技术,不像追风,倒像是真的在用。
花了半个小时跟 AI 把项目背景讲清楚,下次打开,又要从头来一遍。你告诉它你不喜欢代码里加过多注释,它点头答应,下一个任务又给你加了一堆。你教它用某种格式输出结果,有效一次,第二天失效。这不是你的问题,也不是模型不够聪明。是结构性的:绝大多数 Agent 的设计,本质上是无状态的。它们没有学习的地方——每次对话结束,经验就清空。用三个月和用三天,没有区别。
Hermes Agent 由 Nous Research 开发,2026 年 2 月正式开源。Nous Research 这个名字,做 AI 的人不陌生。他们是开源社区里最重要的微调研究组织之一,Hermes 语言模型系列(Hermes 1 → 2 → 2 Pro → 3)在开发者圈子里有很高的口碑——尤其是工具调用能力和指令遵循性上,长期是开源模型的标杆之一。Hermes Agent 是他们把这些年积累的东西,往前走了一步:从语言模型,到一个能跑在你服务器上、持续运行、持续学习的智能体系统。官方对它的定位很直接:"An autonomous agent that lives on your server, remembers what it learns, and gets more capable the longer it runs."——住在你服务器上,记住它学到的东西,跑得越久,能力越强。
大多数 Agent 的工作流程是:接收指令 → 调用工具 → 返回结果。这个循环里没有学习,没有沉淀,能力是水平线。每完成一批任务,Hermes 会触发一次自我评估:这次执行有没有走弯路?有没有调用了根本没用的工具?中间有没有报错、然后用低效的方式绕过去?评估结果不会丢掉。如果这次找到了一个好的解法,它会自动把这个解法整理成一份技能文件(Skill),写进 ~/.hermes/skills/ 目录下,格式是 Markdown,遵循 agentskills.io 标准——人可读,也可以手动编辑或删除。下次遇到类似任务,Hermes 会先检索本地技能库,看有没有现成的解法可以复用,而不是从零开始摸索。有一个社区里流传的案例:第一周处理同类任务需要 25 次工具调用,第六周缩短到 8–10 次。减少的那些调用,是它自己省掉的——因为它记住了哪些步骤是多余的。这个机制背后的技术是 DSPy + GEPA(Genetic Evolution of Prompt Architectures,ICLR 2026 Oral)。它不是在训练模型,而是在自动进化技能描述、工具说明和系统提示词。每次优化的运行成本在 2–10 美元,不需要 GPU。很多 Agent 的"记忆",不过是把对话历史存成一个文本,下次塞进上下文。这个方案在任务简单时还行,任务一复杂,Token 爆了,或者找不到关键信息。第一层,短期记忆。 管理当前对话的上下文,支持自动压缩。渐进式披露的设计——技能文件默认只加载摘要,需要用到再展开完整内容,不会一次性把 Token 撑爆。第二层,情景记忆。 用 SQLite + FTS5 全文索引存储历史交互。关键是,它不是直接把旧对话塞进新对话——而是先用 LLM 做摘要,再注入。这样既能找到"上次那件事是怎么处理的",又不会让上下文失控膨胀。第三层,持久化核心记忆。USER.md 和 MEMORY.md 两个文件,记录你的偏好、常用环境、项目背景。这些信息跨会话保留,哪怕重启、换设备也在。第四层,程序性技能记忆。 就是前面说的 Skill 文件。新任务进来,先搜这里。第五层,Honcho 用户建模(可选)。 这层比较有意思——它集成了 Honcho,通过辩证推理机制,在你和它的长期交互中,逐渐推导出你的工作风格和思维模式,形成用户画像。你不需要显式配置,它自己在跑。
这个问题被问得很多。两个项目都火,有时候社区里争得挺激烈。OpenClaw 的核心是"连接"。 它像一个万能网关,接入几百个工具和服务,把各种能力整合进来。它的强项是广度——你需要一个能调用什么都能调的系统,OpenClaw 很顺手。Hermes 的核心是"进化"。 它不是要接最多的工具,而是要把你用过的工具用得越来越好,把重复的工作路径固化成技能,把你的偏好沉淀成记忆。它的强项是深度——你需要一个真正了解你工作方式的系统,Hermes 更适合。自进化能力。 Hermes 原生支持技能自动生成和迭代,这是架构层面的设计;OpenClaw 的技能依赖人工编写或从社区下载,没有自动进化机制。记忆机制。 Hermes 有主动的周期性记忆保存,前面讲的五层都是系统内建的;OpenClaw 主要依靠模型自主判断要不要记,容易丢失。安全性。 Hermes 内建了容器隔离、MCP 凭证过滤、Tirith 预执行扫描等多层防线,v0.5.0 还做了一次完整的供应链审计;OpenClaw 的插件生态复杂,历史上出现过安全隐患,这是已知的缺陷。本地模型支持。 Hermes 对 Ollama 的支持更原生,配置也更灵活;这对想在本地跑模型、不依赖云端 API 的开发者来说,是实质性的差别。结论不是谁更好,而是场景不同。 单次任务、需要调用大量外部工具,OpenClaw 没有问题。规律性的、重复性的、需要长期积累的复杂工作,Hermes 会越来越顺手。
开发者场景是 Hermes 目前最成熟的用法。让它跑在你的服务器上,持续做 Code Review、生成接口文档、处理 Bug 单——这些任务高度重复,正好是学习回路能发挥价值的地方。跑了一个月之后,它对你的项目结构、命名习惯、常见问题的熟悉程度,会明显超过一个刚接手的新同事。个人效率场景也有意思。在 Telegram 上给它发消息,它在云端的 VPS 上执行——不依赖你的电脑,不占你的本地算力,脱机也能跑定时任务。有人用它做每日简报:定时抓取几个数据源,整理成固定格式,早上推送到手机。跑了几周之后,它已经学会了你喜欢的格式和关注的维度,不需要再反复说明。知识沉淀场景是被低估的一个。把它接入团队的文档系统,每次技术讨论结束让它整理成结构化的笔记,积累下来就是一个真正活的知识库——不是那种写了就没人看的 Confluence,而是下次遇到类似问题时会被检索到、被复用的东西。
Linux / macOS / WSL2 都支持,一行命令安装:curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
Android 通过 Termux 也支持,Windows 原生暂不支持。模型这边,支持 Nous Portal(400+ 模型,含免费的 MiMo v2 Pro)、OpenRouter(200+ 模型)、OpenAI、Anthropic、Google AI Studio,以及本地的 Ollama。切换模型不需要改代码,/model 命令就行,现在还支持在对话过程中实时切换。六种执行后端:本地、Docker、SSH、Daytona、Singularity、Modal。其中 Daytona 和 Modal 支持无服务器持久化——Agent 的环境闲置时自动休眠,有任务时唤醒,5 美元 VPS 就能跑,空闲时几乎不产生费用。
冷启动成本真实存在。 刚开始用的前两周,Hermes 和其他 Agent 没有太大区别。技能库是空的,用户画像是空的,学习回路还没有积累足够的数据。如果你只用它处理一次性任务,感受不到它的优势。它的价值在时间里,不在第一天。技能文件需要你去审查。 自动生成的技能不总是对的。有时候它会把一个"绕过错误"的笨方法固化成技能,如果你不检查,这个坏习惯会一直沿用下去。这不是设计缺陷,但确实需要用户承担一部分管理责任。复杂推理仍是短板。 这不是 Hermes Agent 独有的问题——它依赖的底层模型决定了推理上限。在需要多步数学推导或高度抽象逻辑的任务上,和 DeepSeek-R1 这类专项推理模型相比,差距还在。社区维护模式的可持续性是未知数。 Nous Research 没有商业产品支撑这个项目,靠的是社区驱动。目前贡献者超过 1900 人,活跃度很高——但这种模式能否在几年后保持,很难预判。
我见过太多"颠覆性"的 AI 工具,发布一周,讨论三天,然后慢慢消失在书签里。Hermes 让我觉得不太一样的地方,不是功能列表有多长,而是它在解决一个真实的、结构性的问题:我们跟 AI 工具的关系,不应该是每次都从零开始的陌生人。大多数工具把"智能"当成一个固定的参数——出厂设置,终身不变。Hermes 想把"智能"变成一个变量,随着你使用的时间,随着它积累的经验,缓慢但持续地增长。你用它的第一天,它什么都不知道你。你用它的第一年,它比任何同事都更了解你的工作方式。这是一种不同的竞争逻辑——不比谁开局更强,比谁越用越值。文章看完了,你觉得你要开发智能体,有哪些可以抄作业的?
一人公司到底怎么操作的?YC CEO 开源的 GStack,给了一个很具体的答案
一个人,能不能借助 AI,做出一家真正有规模的公司?这个问题在几年前听起来还像科幻。但到了 2026 年,它已经变成了创业圈里一个越来越严肃的话题。Sam Altman 曾经在一个科技 CEO 群聊里设过一个赌局:第一家“一人十亿美元公司”会在哪一年出现?Anthropic CEO Dario Amodei 在 2025 年 Code with Claude 大会上被问到类似问题时,给出了一个相当激进的判断:2026 年,概率 70% 到 80%。他认为最可能率先跑出来的领域,包括量化交易、开发者工具、自动化客服。2025 年 6 月,以色列开发者 Maor Shlomo 独自创建的 AI 应用平台 Base44,被 Wix 以 8000 万美元现金收购。这个项目上线只有 6 个月,用户超过 25 万,月净利润达到 18.9 万美元。这件事真正值得关注的地方,不只是“AI 提高了个人效率”,而是它暗示了一种新的组织形态:一个人不再只是使用 AI 工具,而是在指挥一组分工明确的 AI Agent。换句话说,他不是“一个人写代码”,而是“一个人管理一支虚拟团队”。这类模式现在有一个常见说法:Agent Swarm,智能体蜂群。而 YC CEO Garry Tan 开源的 GStack,正是目前最有代表性的样本之一。
过去一年,很多人已经证明了 AI Agent “能做事”。但 2026 年真正重要的问题变成了:怎么让 Agent 稳定、可靠、可复用地做事?The model is commodity. The harness is moat. 模型会越来越像基础商品,真正的护城河在 Harness。这里的 Harness,可以理解为 AI Agent 的“操作系统”和“管理框架”。如果大模型是发动机,Harness 就是整辆车:方向盘、刹车、仪表盘、安全带、导航系统。发动机再强,没有这些东西,也很难稳定上路。这也是为什么最近很多 Agent 项目的提升,并不是靠换更大的模型,而是靠重新设计流程、工具、权限和角色边界。比如 LangChain 在 Terminal Bench 2.0 里,没有更换模型,只是改善 Harness,就把成绩从第 30 名推到了前 5 名。Vercel 也做过一个很有意思的实验:他们删掉了 80% 的可用工具,结果 Agent 的响应更快、token 消耗更少、成功率反而更高。给他明确岗位、明确边界、明确交付物,产出反而更稳定。GStack 的核心,就是把这套管理逻辑搬进了 AI 协作里。
02 |GStack 是什么?一套 Markdown 写成的“虚拟公司”2026 年 3 月中旬,Y Combinator CEO Garry Tan 开源了自己使用 Claude Code 的完整工作配置。它的增长速度很快:上线 48 小时突破 1 万 Star,不到一周超过 3.3 万 Star。截至 2026 年 5 月中旬,Star 数已经接近 10 万,Fork 超过 1.4 万。GStack 没有复杂的框架代码,也没有什么神秘算法。它的核心是一组 Markdown 文件。每个文件定义一个 Agent 的角色、边界、工作方式和输出格式。你可以把它理解成一家虚拟公司的岗位手册。- /office-hours:像 YC 合伙人一样挑战你的产品假设;
- /plan-ceo-review:站在 CEO 视角审视产品方向;
- /plan-eng-review:从工程负责人角度锁定架构和测试矩阵;
- /plan-design-review:检查设计质量,识别常见的“AI 味”界面;
- /review:专门寻找“CI 能过,但上线会炸”的问题;
- /qa:打开真实 Chromium 浏览器,逐页点击测试;
- /cso:按 OWASP Top 10 和 STRIDE 模型做安全审计;
- /land-and-deploy:合并 PR、部署生产、做健康检查;
- /retro:做周度复盘,总结产出、测试趋势和改进项。
你输入 /review,就像请一位偏执的高级工程师专门挑刺。它不是让一个 AI 什么都做,而是把 AI 拆成一组有明确职责的“虚拟员工”。
GStack 之所以受到关注,也和 Garry Tan 本人的经历有关。他不是一个只会讲概念的投资人,而是长期写代码、做产品、创过业、投过公司的技术型 CEO。- Palantir 早期员工,参与金融分析产品开发,也设计过 Palantir 的 logo;
- 联合创办 Posterous,后来被 Twitter 收购;
- 曾任 YC 合伙人,参与开发 Bookface 和 Demo Day 网站;
- 联合创办 Initialized Capital,投资过 Coinbase、Instacart、Flexport 等公司;
- 2023 年起担任 Y Combinator 总裁兼 CEO。
所以,GStack 不是一个“Prompt 爱好者”的玩具项目,而更像是一个工程师型 CEO 把自己日常工作流产品化之后的结果。Garry Tan 在 README 里提到,过去 60 天,他兼职完成了 3 个生产服务、40 多个已发布功能,同时还在全职运营 YC。他还用“逻辑代码变更行数”衡量自己的产出,称 2026 年的产出速度大约是 2013 年的 810 倍。这个数字当然可以讨论,尤其是 AI 生成代码很容易放大 LOC 指标。但 Garry 后来也专门写了文章回应争议,并把口径从早期更粗糙的“代码行数”改成了“逻辑代码变更行数”。这说明他真正想表达的并不是“我写了多少行代码”,而是:
GStack 看起来是一套工具,但真正有价值的是它背后的工作哲学。问题在于,这种对话很像让一个人同时做产品经理、架构师、设计师、工程师、测试、运维和安全负责人。GStack 的做法是:每个 Skill 只做一类事。比如 /review 的定位非常窄,它不是泛泛地“帮我看看代码”,而是专门找那些“CI 能过,但生产环境可能出问题”的 bug。AI 的能力越强,越需要边界。否则它很容易“热心过度”,什么都想帮,最后反而降低质量。
GStack 里有一个很有意思的说法:Boil the Lake,把湖烧开。一个模块做到 100% 测试覆盖、完整处理边界条件、补齐错误路径,这叫“湖”,是可以烧开的。但如果你说要从零重写整个系统,那就是“海”,很可能不值得传统软件开发里,我们经常在 80 分方案和 100 分方案之间选 80 分,因为从 80 到 100 的成本太高。补测试、补边界条件、补错误处理,这些过去容易被砍掉的工作,现在边际成本大幅下降。于是,“够用就行”的默认选项,开始变得不那么合理。
GStack 还有一条原则:Search Before Building,先搜索,再构建。很多人一遇到问题,就想从第一性原理开始设计一套自己的方案。但在真实世界里,大多数问题已经被别人踩过坑。第一层,是久经验证的成熟方案。能用就优先用,不要轻易发明轮子。第二层,是新兴但快速流行的方案。可以参考,但要保持判断。第三层,才是第一性原理。当现有做法都不适合时,再基于具体问题做原创推理。GStack 不是鼓励 AI 一上来就生成代码,而是先让 Agent 帮你理解上下文、挑战假设、确认架构,再进入实现。
如果把 GStack 当成一家公司来看,它的工作流大致是这样的:先用 /office-hours 挑战产品假设,确认你要解决的是真问题,而不是自嗨功能。通过 /plan-ceo-review、/plan-eng-review、/plan-design-review 分别从产品、工程、设计角度审查方案,形成范围决策、架构图和测试矩阵。在前面文档足够清楚之后,再让 Claude Code 进入编码阶段。用 /review 找潜在生产事故,用设计审查检查界面质量。用 /qa 打开真实浏览器逐页点击,用 /cso 做安全审计。用 /ship 同步主分支、跑测试、开 PR,再用 /land-and-deploy 合并、部署、检查线上状态。用 /retro 做复盘,用 /learn 把这次学到的模式、坑和架构决策写入长期记忆。这套流程最关键的地方在于:它不是一次性的“让 AI 帮我写点东西”,而是一个完整闭环。从发现问题,到制定方案,到实现,到审查,到上线,到复盘,每一步都有对应角色负责。
GStack 后续版本里有几个新增能力,进一步把它从“Prompt 集合”推向“Agent 操作系统”。AI 工具最常见的痛点之一,是每次对话都像第一次见面。你之前做过什么决定、踩过什么坑、项目里有哪些约定,它都不知道。于是你不得不反复解释背景。它可以理解为给 Agent 准备的持久知识库。项目的架构决策、代码模式、历史问题、复盘结论,都可以沉淀进去。GStack 目前提供几种初始化方式:本地 PGLite、接入已有 Supabase,或者通过 Supabase 自动配置。- read-write:Agent 可以读取,也可以写入新经验;
- read-only:Agent 只能读取,不能写入;
这对做多个客户项目的人尤其重要。因为记忆一旦跨项目污染,风险很高。2. /pair-agent:不同厂商的 Agent 开始协作它允许你在使用 Claude Code 构建功能的同时,让其他 Agent,比如 Codex、OpenClaw 或 Hermes,从另一个角度审查同一个网站。你输入 /pair-agent,选择目标 Agent。 GStack 打开共享浏览器窗口,并生成配置指令。 这背后的重点不是“多开几个 AI”,而是跨厂商 Agent 之间开始有了协作接口。为了避免混乱,GStack 也设计了 scoped token、tab 隔离、频率限制、域名白名单和活动归因。3. Review Routing:自动判断该谁审查还有一个很实用的能力,叫 Review Routing。修一个基础设施 bug,不一定需要 CEO 审查。 GStack 会自动追踪当前变更已经跑过哪些审查,还缺哪些审查,并在 /ship 前给出 Review Readiness Dashboard。因为真实的软件质量,往往不是靠某一次天才发挥,而是靠流程里少漏几个关键环节。
07 | GStack 和直接用 Claude Code,有什么不同?直接用 Claude Code,当然也可以写代码。这很依赖提问者本人的经验。如果你没想到要问,AI 也不一定主动补齐。GStack 的不同在于,它把很多优秀工程团队的默认动作预先固化了下来:所以,GStack 不是让 Claude Code “更聪明”,而是让它“更像一支训练过的团队”。
08 | SKILL.md:GStack 的基本单元GStack 里最基础的东西,是一个个 SKILL.md 文件。很多人以为 AI 工作流的核心是复杂代码。GStack 证明,很多时候真正关键的是:你能不能把工作定义清楚。一个好的 SKILL.md,本质上就是一份岗位说明书。它告诉 AI:你不是万能助手,你现在是 QA、是安全官、是工程负责人、是产品顾问。你只需要在这个角色里,把该做的事情做到位。哪怕你不使用整套 GStack,也可以从今天开始,为自己的 AI 工作流设计几个固定角色。
总结 | 一人公司不是一个人单干,而是一个人管理一群 Agent恰恰相反,它的核心只是一组 Markdown 文件。它给我们的启发不是“以后所有公司都只需要一个人”,这个判断太激进,也太简单。AI 会让高水平个体拥有过去一个小团队才具备的能力。一个人可以让测试、安全、文档、部署这些过去容易被忽略的环节,变成默认动作。Sam Altman 的赌局、Dario Amodei 的预测、Base44 的退出,都在指向同一个趋势:而 GStack 的价值,就是把这个趋势写成了一套可以参考、可以复制、可以改造的工作流。
装上 draw.io Skill,让 AI 帮你画流程图、架构图,画完还能继续改
上周有个朋友问我,你的那些架构图和流程图是怎么画的,看着挺整洁的。他问怎么配。我说你装个skill就行。他问什么是skill。
我做技术的,免不了要画各种图——流程图、产品架构图、系统架构图、时序图……以前的方式是:打开draw.io,一个节点一个节点地拖,一条线一条线地连,调样式,调对齐,调颜色。一张稍微复杂点的图,半小时没了。后来试过让AI直接生成图,结果它给我输出一堆文字描述,或者Mermaid代码,贴进去还要各种调整,也麻烦。现在的方式是:把draw.io接上AI,说一句话,图就出来了,而且出来之后还能直接在draw.io里继续编辑。
官网直接下:https://www.drawio.com/桌面版,免费,Windows/Mac都有,选择你合适的下载。这个skill本质上是一个配置文件,告诉AI怎么生成draw.io能识别的XML格式。把下面这个地址给你用的AI工具(Claude、通义灵码等都行),让它读取并安装:https://github.com/jgraph/drawio-mcp/blob/main/skill-cli/drawio/SKILL.md
装好之后,AI就知道怎么输出draw.io格式的图了。
我直接跟AI说:帮我画一张完整的电信运营商开户流程图。AI想了几秒,开始构思。它把整个流程拆成了三条泳道——客户、营业员、系统——然后把每个环节分配到对应的泳道里:- 客户这边:进门选号、出示身份证、签协议、缴费、领卡
- 营业员这边:引导、收件、现场拍照、提交审核、收款、发卡、给回执
- 系统这边:一证五号检查(同一身份证最多开几个号)、黑名单核查、公安系统实名核验、写卡激活
还有异常分支——核验不过的话,流程走向"拒绝开户",单独一条路径。生成完,直接在draw.io里打开,布局、颜色、箭头,一步到位,我基本没改什么。更绝的是这个。我找了一张AI智能体技术分层架构图的截图,发给AI,说:参考这张图,帮我画一张。AI识别出图片结构:左侧是核心理念支撑,右侧是应用领域,中间分了四层(感知与理解、认知与决策、执行与交互、协作与系统),底部是模型基础和部署平台。然后它把整个坐标体系、嵌套容器、每一层的配色方案全部计算好,生成了一个XML文件。打开之后,跟参考图的结构基本一致,细节上有出入的地方,我自己在draw.io里拖两下就改好了。以前这种图我可能要画两三个小时,现在大概十分钟,AI出图加上自己微调。
我用过纯AI生图(输出图片),也用过AI写Mermaid代码。纯图片的问题是没法改,颜色、文字、布局,想动一个地方就得重新生成,还不一定生成对。Mermaid代码的问题是,复杂图它搞不定,而且样式控制非常有限。draw.io + AI skill这个组合的优势是:AI生成,人工兜底。AI把骨架搭好,你来处理细节。draw.io本身的编辑能力很强,想改什么都方便。这是一个真正能用在工作流里的方案,而不是玩具。
- AI生成的图,第一次可能不完美,可以继续追问:"把第三层的颜色改成蓝色系"、"在XX节点后面加一个判断分支",它能理解上下文继续修改。
- 图特别复杂的时候,AI可能需要分步生成,先出框架,再补细节。
- draw.io支持导出PNG、SVG、PDF,生成的图质量够用。
就这些。如果你也经常要画图,可以试试这个组合,比你想象的顺手。
当所有 AI IDE 都在卷代码生成,Qoder 1.0 做了一件完全不同的事
最近几个月,我和身边不少开发者聊,大家都有一种奇怪的感觉——我自己最近在做一个 RAG 项目,文档解析 + 向量化 + 检索召回 + 重排序,加上对接公司内部的知识库,中等复杂度,不算大但也不简单。用过去那套 AI IDE 的工作方式来推进,真的很折磨——得时刻盯着它跑,生怕它把向量存储那块的接口写偏。一个任务开着,另一个任务没地方放。写完代码质量全靠自己审,Review 被驳回,返工。最关键的是,项目进行到第三周,它还不知道我们用的是 LangChain 1.0 而不是 0.3,接口已经改了,它还在用老写法。这不是某一款工具的问题。这是整个 AI IDE 赛道的结构性问题。所有人都在卷代码生成能力,没人认真想过:代码生成之后的事,到底谁来负责?
我翻了一下最近几个月的行业数据,有个数字挺能说明问题:AI 辅助编程工具的采用率在过去一年翻了一倍,超过 60% 的专业开发者日常都在用至少一款 AI 编程助手。从 2023 年的代码补全,到 2024 年的对话编辑,到 2025 年的多轮交互,再到今天——AI 编程工具的能力已经进入"自主 Agent + 多 Agent 并行"的阶段。原因其实很简单:工具能力上去了,但工作方式没变。你还是在用一个"更强的 AI 助手"的思路,去管一个已经有能力自主跑任务的 Agent。这中间有一层根本的错配。Qoder 1.0,大概就是从这个角度重新想了一遍这件事。
二、它不是 AI IDE,是"智能体自主开发工作台"Qoder 在国内开发者圈子里有一定知名度,之前的版本是一款走上下文工程路线的 AI IDE。但这次 1.0 的升级,产品定位变了。他们自己的说法是:Qoder 1.0 不再是一个 AI IDE,而是一个自主开发工作台。- Editor(编辑器):传统的 IDE 体验,和AI 结对编程的地方,该有的都有。
- Quest 全新视图:全新独立的开发控制台,指挥 Agent 团队交付软件的地方
这个区分本身就很说明问题:写代码是一件事,管理 AI 交付是另一件事,它们不应该挤在同一个界面里互相干扰。核心理念就一句话:Quest On, Hands off。
我第一次切换到 Quest 全新视图的时候,有点愣了一下。更像是一个任务管理台,或者说,一个专门为软件交付设计的"指挥室"。三栏布局,每一栏各司其职:- 左栏:导航和管理。新建 Quest、不同项目的 Workspace 切换、知识库和 Agent 配置都在这里
- 中栏:会话流。这里有个设计细节我觉得做得对——它用了很强的折叠策略,Agent 执行过程被折叠起来,你看到的是结果,而不是一大堆过程输出
- 右栏:产物区。Summary 交付清单、参考引用面板、代码变更视图、浏览器预览、终端、文件,全部集中在这里
传统 AI IDE 的问题在于,AI 的输出和你的工作流混在一起,找结果要往上翻会话记录,很割裂。Quest 的三栏布局把这个问题从界面层解掉了:左边管任务,中间看过程,右边看产物,逻辑清晰。
以前用 AI IDE,不管哪款,都有一个隐性负担:你得一直在那儿看着。Agent 在跑,你在等,偶尔它卡住或者跑偏,你要介入,然后继续等。这种体验,与其说是"AI 帮你干活",不如说是"你在帮 AI 干活"。Qoder 1.0 的多任务工作区把这个逻辑翻过来了。我拿 RAG 项目举个具体例子。那天我手头同时有三件事要推进:- 文档解析模块:需要支持 PDF、Word、Markdown 三种格式的入库,解析逻辑不一样
- 检索召回优化:原来是单路 Dense Retrieval,要改成 Hybrid Search,加上 BM25 稀疏检索
以前这三件事只能串行——等第一个做完,再开第二个,因为 AI IDE 里同时开多个对话会完全乱掉,上下文互相污染。在 Qoder 里,我新建了三个 Quest,每个对应一个任务,分别描述需求,让它们同时跑起来。左栏能看到三个 Quest 的状态各自独立推进。我在等文档解析模块的时候,顺手去看了一眼 API 层的进度,发现它在流式输出那里用了一个不太对的写法,介入纠正了一下,然后继续放手。这种感觉确实不一样——不是"等 AI 写完",是"在几个任务之间做调度"。每个 Quest 就是一个独立的任务单元,有自己的生命周期状态:运行中 / 等待确认 / 已完成。多个 Workspace 也能自由切换,我另一个项目的 Agent 在跑的时候,RAG 这边完全不受影响。开发者真正需要做的,变成了:快速判断当前哪个任务需要我介入,其他的让 Agent 继续跑。
五、Summary 交付清单:从"它说它做了什么"到"我能检查它做了什么"Quest 右栏有一个叫 Summary 的东西,是我用下来觉得最值得单独说的设计。还是 RAG 项目的例子。Hybrid Search 那个 Quest 跑完之后,我没有去翻会话记录,直接打开右栏的 Summary。- Progress:任务被拆成了 5 步——分析现有检索架构、引入 BM25 依赖、实现稀疏检索器、合并融合逻辑(RRF 算法)、更新检索接口。5 步全部打了对勾。
- Artifacts:生成了一份设计文档,说明了为什么选 RRF 而不是 linear combination,以及召回权重的初始配置建议
- Changed Files:改动了 5 个文件——requirements.txt、config.py、bm25_retriever.py、vector_store.py、file_watcher.py,每个文件点进去都有 Diff 视图
我在 Diff 里发现它在 bm25_retriever.py 里加了一个参数 sparse_weight=0.3,hardcode 进去了,我觉得应该提到配置文件里。这种问题,如果是翻聊天记录根本发现不了,藏在一大堆过程输出里。但在 Diff 视图里一眼就看到了。这个设计解决的是一个很现实的问题:以前 Agent 跑完,你怎么验收?只能往上翻聊天记录,看它自己说做了什么。但"它说它做了什么"和"它真的交付了什么",是两件事。Summary 提供的是可检查的交付物,而不是一段自述。
说完工作台的形态,再说说里面的 Agent 是怎么工作的。Qoder 1.0 引入了一个叫"专家团(Experts)"的概念。简单说,就是把单个 Agent 扛全场,变成一支有分工的 AI 团队。我拿 RAG 项目里一个具体任务来说:给检索链路加用户查询改写(Query Rewriting)模块。这是一个中等复杂度的需求,涉及 prompt 设计、接口改动、测试用例,放给单个 Agent 跑经常会有顾此失彼的情况。在专家团模式下,我把需求丢进去之后,能看到几个 Agent 开始各自认领任务:- 调研员 派遣Researcher Alex 调查当前检索链路的实现细节,完成后将基于结果设计查询改写模块。
- 全栈工程师 派遣 Coding 工程师 Lee 实现查询改写模块。
- 测试工程师 派遣 QA Chris 进行代码验证,测试有问题再返回全栈工程师进行修改,全栈工程师修改完成再进行测试。
这是我觉得专家团模式真正有价值的地方——不是"多几个 Agent 更快",而是不同角色盯不同维度,系统性地减少漏洞。除了内置的研发专家团,还有一个更进一步的能力:自定义业务专家。RAG 项目有一些特定的团队规范,比如:所有向量化操作必须支持批处理,接口返回格式要带 source_doc_id 字段方便溯源,日志里要记录召回耗时。这些规范散在 Wiki 里,以前每次都要手动告诉 AI。现在我把这些规范整理成一个自定义专家的 SKILL,叫"RAG 质检员",让它在每次 Code Review 时自动对照这份规范检查。配置完之后,它就成了专家团的一员,参与后续所有 RAG 相关任务的质检环节。一个做金融系统的团队,可以把合规检查规则写进专家的 SKILL 里;一个做医疗的团队,可以创建一个懂 HL7/FHIR 协议的专家 Agent。这不是固定的 Agent 列表,是一套可以按需扩展的 AI 团队机制。
这个功能不是最显眼的,但我认为是最能体现长期价值的。AI 编程工具有一个几乎所有人都吐槽过的问题:每次聊天都失忆。我在 RAG 项目上最有感触的一次:项目进行到第三周,我让 AI 帮我写一个新的 Reranker 接入模块。它写出来的代码能跑,但用了 LangChain 0.1 的 API,RetrievalQA.from_chain_type() 那套,我们早就迁到 0.2 的 LCEL 写法了。返工,重写。Qoder 1.0 的知识引擎就在解这件事。它分两块:记忆(Memory):记住你的偏好、规范、历史决策。我第一次跑完文档解析模块之后,它记住了我们用 pdfplumber 而不是 PyMuPDF,也记住了我们的 chunk size 设定是 512 tokens 带 64 tokens 的 overlap。下次再开新 Quest,这些背景它自己就带上了,不用我重新说。项目知识(Knowledge):这个更厚实。用了一段时间之后,我打开 Knowledge 面板,看到它自动归纳出了三类知识:- 架构知识:比如"向量存储走 VectorStoreManager,不要直接调 Chroma client"、"检索链路的入口是 SearchPipeline.run()"——这些是在代码库里摸索才能搞清楚的东西,它自己梳理出来了
- 编码规范:比如"所有检索接口返回值必须包含 source_doc_id"、"日志里要记录召回耗时,用 logger.info 而不是 print"——这些是我们团队的约定,之前它不知道,现在在里面了
- 技术栈知识:LangChain 版本、我们用的 Embedding 模型(text-embedding-3-small)、向量库选型(Chroma)、重排序模型(bge-reranker-v2-m3)
验证效果的时候挺直观的:我让它在现有基础上加一个多路召回合并去重的逻辑,右侧 Summary 摘要区能看到"已引用"的知识条目,包括它自己调用了架构知识里的 SearchPipeline 入口,以及编码规范里的返回格式要求。写出来的代码直接符合我们的规范,没有返工。这个"引用了哪些知识"的可见性,我觉得挺重要。不是黑盒地"它好像变聪明了",而是能看到它用了什么上下文来做判断。官方给出了一组内部实测数据(3天 Top 5 类目统计,供参考):Token 降低 40% 这个数字,对于用量大的团队来说,其实直接影响成本。代码保留率提升 11%,我理解就是它写出来的代码不用大改直接可以用的比例变高了——这个感知最直接。
正在用 Cursor / Windsurf 但体验不满意的开发者——如果你的主要痛点是界面割裂、Agent 难管、多项目切换麻烦,Quest 全新视图是一个很不同的思路,值得花一个下午试试。觉得现在 $20/月不划算的开发者——Qoder 有社区版(完全免费),配合 BYOK(自带 API Key,比如百炼、Kimi、智谱的 Coding Plan)就能使用 Quest 全新视图里的 Agent。零成本入场,不用翻墙,不用绑海外信用卡。之前试过 Qoder 老版本的用户——这次 1.0 不是小更新。Quest 从一个"模式"升级成了全新独立视图,整个产品形态变了,如果你之前流失是因为觉得功能不够,这次值得回来看看。还没上手 AI IDE 的观望者——国产工具、中文界面、支付宝付款、国内网络直连,社区版免费用,入门门槛是所有同类工具里最低的之一。
我最近看到一个说法,大意是:AI 编程工具的上半场,比的是谁能生成更好的代码;下半场,比的是谁能更可靠地交付软件。Quest 全新视图、专家团流水线、工程知识引擎,这三件事加在一起,指向的是同一个方向:让开发者真正放手,而不是换一种方式盯着 AI 干活。能不能做到,还需要更多时间和用户量来验证。但方向上,我觉得是对的。下载 Qoder 1.0,右上角切换 Quest,自己感受一下。社区版完全免费,BYOK 接上自己的 API Key,就能用上 Quest 全新视图。
AI Agent 新范式:会记忆、会调度、会进化的 Hermes Agent 全解析
我有个朋友,是一名独立开发者,同时跑着三个项目。他从去年开始用 AI 助手辅助写代码,用了大半年,每天早上打开对话框的第一件事,还是粘贴一段固定的上下文说明:"我的项目是 Rust + Axum,使用 SQLx 操作 PostgreSQL,代码风格用 Tab 缩进,120 字符换行,不要用 sudo 运行 Docker……"他跟我说,这件事让他每天都有一种奇妙的挫败感——用了这么久,AI 对他的了解,还停留在"第一次见面"的水平。这不是个例。这几乎是所有人使用 AI 助手的共同体验。原因说穿了也简单:大多数 AI 工具是无状态的。你关掉对话窗口,它就忘了你。任务完成了,经验清零了。每一次交互都是从零开始,它不记得你,不了解你,更谈不上"越用越顺手"。这背后有一个更深层的问题:我们一直在把 AI Agent 当作工具在用,但工具是不会成长的。2026 年 2 月 25 日,Nous Research 发布了 Hermes Agent。这个项目在 GitHub 上突破了 15.6 万+ Star(5月中)。热度背后,是一批真实用户从其他 Agent 迁移过来之后发出的那种感叹——"这才是我想要的 Agent 该有的样子"。这篇文章不是产品评测,我想做的是借助 Hermes Agent 的架构设计,聊清楚一件事:一个真正成熟的智能体系统,到底应该长什么样子?
在拆解 Hermes 之前,先退一步想清楚一个问题:现有的 Agent 到底差在哪里?我把常见的问题归纳成三点,姑且叫它 Agent 的"三原罪"。第一罪:无状态。 每次对话从零开始,没有跨会话的记忆,关掉窗口就失忆。第二罪:无积累。 即便完成了复杂的任务,那段经验也不会变成它下次可以直接调用的"方法"。它只是执行,不会从执行中学习。第三罪:无自主。 它只能等你触发。你不来,它不动。没有能力主动去做那些不需要你每次都手动发起的重复性工作。这三点加在一起,造成了一种根本性的体验缺失:你用的时间越长,感受到的进步越少。那么,一个真正成熟的 Agent 应该满足什么条件?我认为可以用三个维度来衡量一个 Agent 的架构成熟度:记忆的深度、调度的广度、进化的能力。记忆的深度,决定了它是否真正了解你;调度的广度,决定了它能否主动帮你工作;进化的能力,决定了它会不会越用越懂你。Hermes Agent 的整套架构,其实就是围绕这三件事展开的。
Hermes Agent 的架构分为六层,从上到下依次是:用户接入层、核心引擎层、消息平台层、工具层、基础设施层、LLM 提供商层。光看这个分层,你可能觉得和其他框架差不多。但每一层背后的设计决策,才是真正值得拿出来说的地方。Hermes 支持七种接入方式:命令行 CLI、终端 TUI、IDE 插件、API 服务、消息网关、批量运行、定时任务。这不是为了"功能丰富"而堆功能。背后是一个明确的设计主张:Agent 不应该被绑在某个入口,它应该活在你已经在用的地方。你在终端工作,它陪你在终端;你习惯用 Telegram 发消息,它就住在你的 Telegram 里;你需要它在你睡觉的时候跑一个批量任务,它自己知道怎么做。更关键的是,接入层与核心引擎完全解耦。无论你从哪个入口进来,走的都是同一条核心处理管道。这种设计才能让 Agent 真正做到"平台无关"——换个入口,不影响任何行为逻辑。这是 Hermes 架构里最重要的一层,也是它和大多数其他 Agent 框架拉开差距的地方。Hermes 的核心是 AIAgent Loop,而不是网关控制面。这是一个刻意的设计选择——学习循环是第一优先级的架构关切。Prompt 组装器:不是让人手写 Prompt,而是系统自动将记忆、技能、工具描述、上下文,按照优先级动态拼装成每次调用的完整输入。Prompt 工程应该是系统行为,而不是人工艺术。比例阈值压缩:当上下文超出模型的窗口限制时,自动按照信息密度和重要性进行压缩。这解决了长任务中的"上下文溢出"问题,让 Agent 能处理真正复杂的长流程任务。工具注册与调度:工具不是硬编码进去的,而是通过注册机制动态加载。Agent 在运行时根据任务需要,自主决定调用哪个工具、按什么顺序调用。工具是一等公民,不是硬编码的函数。会话存储(SQLite + FTS5):所有对话历史存入本地 SQLite 数据库,并建立 FTS5 全文索引。这让 Agent 能够在几个月后的对话里,精确检索出你三个月前讨论过的某个细节。模型适配层:对上层屏蔽具体的 LLM 实现,任何 OpenAI 兼容的接口都能接入。换模型只需一行命令,不改业务逻辑。Hermes 支持 20 多个消息平台,包括 Telegram、Discord、Slack、WhatsApp、飞书、钉钉、微信、QQ 机器人等。但比"支持多少平台"更重要的,是它处理消息的方式。大多数 Agent 框架里,消息平台是外挂在核心逻辑外面的"接口层"。而在 Hermes 里,网关是同一个循环的一部分。一条消息可以触发技能创建,一个定时任务的输出也通过同一套网关路由回来,跨平台的会话连续性因此得以真正实现——不是拼凑出来的,是架构上原生支持的。这个区别在实际使用中非常明显:你在 Telegram 发消息让它开始一个任务,它在服务器上执行,完成后再通过同一个 Telegram 把结果发回给你。整个过程是一个完整的闭环,而不是三个独立的系统碰巧连在一起。工具层包含六大类:终端执行(支持 8 种后端)、文件操作、网络搜索、浏览器控制、子代理、MCP 集成,以及记忆工具。这里值得关注的,不是工具的数量,而是工具注册与调度分离的设计思想。工具不是在启动时就固定好的,而是通过注册中心动态管理的。Agent 在执行任务时,会根据当前任务的语义,自动发现并调用合适的工具。这让系统具备了真正的可扩展性——加一个新工具,不需要修改核心逻辑。可插拔记忆、技能系统、插件系统,构成了 Hermes 的基础设施底座。"可插拔"这个词很关键。Hermes 内置了 8 个记忆后端,包括 Honcho、Mem0、Hindsight、Supermemory 等,可以根据场景选择不同的记忆方案。本地记忆不够用的时候,无缝接入云端语义记忆服务。这里体现的是一个重要的架构原则:基础设施与业务逻辑分离,才能让系统在不同规模和场景下都能运转。对于国内用户,Hermes 原生支持 DeepSeek、通义千问(Qwen)、GLM 智谱、MiniMax、KIM 等国产模型,同时也支持 OpenRouter 上的 200+ 模型。切换模型只需要一条命令:hermes model,不需要改任何代码,不被任何平台锁定。这背后的架构原则是:模型适配层应该是抽象接口,而非具体依赖。你用什么模型,是部署配置的问题,不应该渗透到应用逻辑里。
记忆是区分一个"能用的工具"和一个"真正的助手"的核心能力。但记忆这件事,远比听起来复杂。问一个关键的问题:什么样的信息,应该以什么样的方式被记住?不同类型的信息,有完全不同的访问模式。你的编码偏好,每次会话都需要用到,应该常驻在上下文里;三个月前某次讨论的技术决策,偶尔需要检索;某个复杂任务的执行方法,需要能被复用和改进。把这三种信息都塞进同一个"记忆数据库"里,要么太贵(每次都全量注入),要么太慢(每次都要检索),要么太死(只记事实,不记方法)。两个文件:MEMORY.md(约 800 Token)和 USER.md(约 500 Token)。这两个文件的内容,会被注入到每一次会话的系统 Prompt 里,Agent 永远能直接访问,不需要检索。MEMORY.md 存的是关于环境和项目的事实性知识,比如:- 这台机器运行 Ubuntu 22.04,装了 Docker 和 Podman
- 项目用 Tab 缩进,120 字符换行,Google 风格注释
- 数据库已在 2026 年 1 月从 MySQL 迁移到 PostgreSQL
USER.md 存的是用户的工作风格和偏好:习惯的工作时间、沟通方式、常用工具、决策倾向。这一层的设计哲学:最高频使用的信息,应该零延迟可达。把它放进系统 Prompt,就是最直接的实现方式。技能(Skill)是 Hermes 里最有创意的设计,放到下一章单独讲。但从记忆的角度来说,技能文件扮演的是程序性记忆的角色——它记住的不是事实,而是方法。"上次你帮我做竞品价格分析,是怎么做的?"——这个问题,事实性记忆回答不了,技能文件可以。第三层:历史检索——SQLite + FTS5(冷记忆)所有对话历史存入 SQLite,通过 FTS5 建立全文索引。这让 Agent 能够精确检索几个月前的对话内容。检索不是直接返回原始文本,而是经过 LLM 摘要处理,提取出与当前任务相关的信息片段再注入上下文。这三层加起来,构成了一个按照访问频率和信息密度分层的知识体系:常用的放热层,偶尔用的放冷层,方法论放中间。架构方法论:记忆不是一个数据库,而是一个有温度分层的知识系统。设计记忆架构时,要先想清楚不同类型信息的访问模式,再决定存在哪一层。
大多数 Agent 完成任务之后,那次任务的经验就消失了。下次遇到同样的问题,它还是从零开始思考。这不是记忆的问题,而是经验转化的问题——它没有能力把一次成功的执行过程,变成下次可以直接调用的方法。Hermes 的解法叫做程序性记忆,载体是技能(Skill)文件。第一步,完成一个复杂任务。比如你让它"调研竞品定价并生成对比表格"。第二步,任务完成后,Agent 分析自己的执行步骤,识别出其中可以复用的模式——搜索策略、数据提取方式、表格结构、交叉验证方法。第三步,将这个工作流写成一份 Markdown 技能文件,包含任务描述、触发条件、执行步骤、注意事项。第四步,下次遇到类似任务,直接加载这个技能文件,在已有步骤的基础上执行,并根据结果进一步优化技能内容。第五步,每完成 15 个任务,Agent 做一次整体复盘——分析哪些任务成功、哪些失败、成功的原因是什么、失败的模式是什么——然后更新相应的技能文件。这个循环的关键创新,是它把**"做过"转化成了"会做"**。事实性记忆记住了"发生了什么",程序性记忆记住了"怎么做到的"。# 竞品价格调研技能
触发条件:需要分析竞品定价或市场价格对比时
执行步骤:
1. 明确竞品范围(直接竞品 vs 间接竞品)
2. 搜索策略:优先官网,辅以第三方评测
3. 数据标准化:统一货币、计费周期、功能维度
4. 交叉验证:至少两个来源确认关键数据
5. 输出格式:Markdown 表格 + 文字摘要
注意事项:
- 注明数据获取日期,价格信息时效性强
- 免费套餐与付费套餐分开列
这个文件,你可以打开,可以阅读,可以手动编辑,可以导出给其他 Agent 使用。它是开放的、透明的、可迁移的。这是一个听起来很低的技术门槛,但它是所有前代框架都没能跨过的门槛——那些框架的记忆是黑盒,你不知道它"学到"了什么,也没法验证它的学习是否正确。从 v0.12 版本开始,Hermes 引入了一个自主 Curator 机制:通过 Cron 定期对整个技能库进行评分和整合——合并功能重叠的技能,淘汰低效的技能,提炼出更通用的版本。这意味着技能库不只是被动地积累,而是会主动优化自身。这是 Agent 走向真正自治的一个关键能力节点。架构方法论:技能即代码,经验即资产。一个成熟的 Agent 系统,应该能把成功的执行过程沉淀为可复用、可审计、可迁移的程序性知识。
如果说记忆和进化解决的是"了解你"的问题,那么调度解决的是"主动帮你"的问题。想象一个场景:每天早上 8 点,你的 Agent 自动汇总昨天的 GitHub 提交,检查 CI 是否全部通过,把需要你关注的问题整理好,在你打开 Telegram 的时候已经发给你了。你不需要启动它,不需要发指令,它自己就做了。传统的定时任务(Cron + Shell 脚本)有一个根本性的缺陷:它执行了,但不知道发生了什么。Token 过期了,任务失败了,你三周后才发现 GitHub 仓库一直没有更新。系统不会告诉你,日志也许有,但谁会每天看日志?更重要的是,传统 Cron 是孤立的——它不知道你的偏好,不了解你的项目,不能根据执行结果调整策略。它只是一个定时触发的 Shell 命令。Hermes 里的定时任务,是第一公民的 Agent 任务,不是碰巧调用 AI 的 Shell 脚本。当调度时间到来,触发的是完整的 Agent Loop——带着完整的记忆和技能访问权限,用和交互式会话完全相同的处理管道来执行任务,只是触发方式从"收到消息"变成了"时钟信号"。执行完成后,结果通过 Gateway 路由到你指定的平台——可以是 Telegram、Slack、Email,或者写入文件。更关键的是,任务结束后,Agent 会更新 MEMORY.md,记录任务状态、执行结果、遇到的问题。如果任务失败——比如 GitHub Token 过期——它不会静默失败,而是在你下次打开对话的时候主动告诉你:"昨晚的备份任务失败了,原因是认证 Token 已过期,需要更新。"这就是调度与 Agent 核心共享上下文的价值:它知道上下文,才能做出超越简单执行的判断。Hermes 还做了一件很有意思的事:你不需要写 Cron 表达式。你只需要说:"每天晚上 12 点,把今天的代码变更推送到 GitHub。"Hermes 自己解析这句话,创建对应的技能文件,设置好 Cron 任务,告诉你配置完成了。这不只是用户体验的改善。它背后的意思是:自动化的门槛,不应该是你需要掌握 Cron 表达式和 YAML 配置,而是你能不能清楚地描述你想要什么。架构方法论:调度层不应该是一个独立的子系统,而应该是 Agent 核心循环的自然延伸。调度任务能访问记忆,能触发技能,能通过网关回报结果——这才是完整的调度能力。
讲到这里,我想把 Hermes 的具体实现抽象出来,整理成几条我认为对智能体架构设计有普适价值的原则。这些原则不只适用于 Hermes,如果你在设计任何形式的 AI Agent 系统,这些思路都值得认真想一想。原则一:接入无关性。 好的 Agent 架构,核心逻辑不应该依赖任何特定的接入入口。接入层与引擎层的解耦,是实现跨平台、跨场景能力的前提。原则二:记忆分层化。 按照访问频率和信息密度,将记忆分为热(系统 Prompt 常驻)、温(技能文件按需加载)、冷(历史检索按需召回)三层。不同温度的信息,用不同的存储和访问机制。原则三:经验程序化。 Agent 应该能将成功的工作流,自动转化为可复用、可审计的程序性记忆。技能文件是载体,学习循环是机制,关键是让"做过的事"变成"会做的事"。原则四:调度一体化。 定时任务不是外挂功能,应该是 Agent 核心循环的自然延伸。调度任务能访问记忆、能触发技能、能感知失败、能主动汇报,才具备真正的自治价值。原则五:模型解耦化。 LLM 调用应该通过抽象层隔离,任何业务逻辑都不应该直接依赖具体的模型 API。模型切换应该是配置问题,不是代码问题。原则六:技能开放化。 技能的格式应该是开放的、跨平台的。一个在 Hermes 里积累的技能库,应该能迁移到其他支持同一标准的 Agent 上使用——这是真正有价值的"数字资产"。
学习循环(记忆 + 技能 + 用户建模)是真正有创意的设计,大多数竞争框架甚至没有尝试实现跨会话的持续改进。技能生态已经积累了 600+ 个社区技能,你不需要从零开始训练你的 Agent。六种终端后端(本地、Docker、SSH、Daytona、Singularity、Modal)给了部署上真正的灵活性。记忆文件的 Token 上限较小(MEMORY.md 约 800 Token),信息量大的场景会有瓶颈。技能快照有滞后问题——技能文件的更新不是实时的,在高频迭代的场景下,技能内容可能落后于实际行为。Cron 任务的 Prompt 开销在大量定时任务的场景下不容忽视。安全层面,有几个尚未完全解决的问题需要认真对待:技能投毒攻击(恶意构造的技能文件可以影响 Agent 行为)、MCP 供应链风险(第三方 MCP 服务的可信度难以验证)、主机凭证暴露(Agent 有终端执行权限,配置不当存在凭证泄露风险)。独立开发者、研究人员、重度使用 AI 助手的个人用户。特别是那些有稳定工作流、需要 Agent 长期积累上下文、希望 Agent 能主动帮你跑重复性任务的人。需要多人协作审批流程的团队工作流,需要强审计追踪的合规场景,以及对技能文件来源没有严格把控能力的团队。
Stanford HAI 2026 年 AI 指数报告里有一句话,让我印象很深:Agent 的价值不再仅来自模型本身,而是来自记忆、工作流恢复、工具编排和可重复执行能力。这句话换一种说法是:好的 Agent,不只是一个会回答问题的 LLM,而是一个有记忆、有积累、有自主性的系统。Hermes Agent 的架构,是对这种判断的一次具体实践。它不是最完美的方案,但它提出了一套清晰的思路——记忆要分层,经验要程序化,调度要一体化,技能要开放。我们正处在 Agent 从"会用的工具"进化为"真正的助手"的过渡期。在这个阶段,架构设计的选择,往往比模型能力本身更重要。如果你要为自己的工作场景设计一个 Agent,你会优先解决记忆、调度、进化三个维度中的哪一个?为什么?
本文参考资料:NousResearch/hermes-agent(GitHub)· Turing Post《Hermes vs OpenClaw》· Stanford HAI AI Index 2026 · Hermes Agent 官方文档
一文搞懂:Token、Prompt、Context、Memory,为什么它们决定了Agent的效果?
两个同事,同时在用 ChatGPT 写一份产品分析报告。B 同学输入的是:「你是一名有 10 年经验的 SaaS 产品经理,现在需要帮我分析一款面向中小企业的 CRM 工具。重点围绕用户留存问题展开,输出格式为:问题定义 → 数据推断 → 可能原因 → 改进建议,每个部分不超过 150 字。」同一个模型,同一个时间,两个人拿到的结果,差了不止一个量级。A 同学拿到了一段废话连篇的通用套话,B 同学拿到了一份可以直接汇报的分析框架。这件事说明了一个很基本的道理:大模型的上限由模型本身决定,但你能拿到多少,由你的输入决定。很多人觉得 AI 用起来效果一般,第一反应是"这个模型不行"。但真实的问题往往不在模型,而在于他们根本没想清楚自己在输入什么、输入了多少、输入对了没有。本文想系统讲清楚大模型输入层的几个核心概念:Token、Context、Prompt 体系、Memory。不是为了讲概念而讲,是因为只要你在用 AI 做事,这几件事搞不清楚,就永远在低效摸索。一、Token:模型看到的不是"字",而是"碎片"很多人以为模型是一个字一个字读进去的,就像人看文章一样。模型处理的基本单位是 Token,而 Token 既不是字,也不是词,是一种介于字和词之间的语言碎片。英文句子 "Understanding" 在 GPT 的分词系统里会被切成 Under + stand + ing 三个 Token。中文相对特殊,大致每 1.5 到 2 个汉字对应 1 个 Token——也就是说,中文的 Token 效率天然低于英文,同样的内容用中文写,消耗的 Token 更多。每个模型都有一个最大处理窗口,比如 128K Token、200K Token,超出这个范围的内容模型根本看不到。这意味着你跟模型聊得越久,越早期的对话就越可能被丢掉。调用 API 是按 Token 计费的,输入多少、输出多少都要算。一个写得冗长啰嗦的 Prompt,可能比精炼版本多消耗 3 倍 Token。规模一大,这个成本差距相当可观。所以"话说太多"和"话说太少"都是问题。太多浪费 Token,占用有限的上下文空间;太少信息不足,模型只能靠猜。理解 Token,本质上是理解模型的"视力范围"和"计费逻辑"。二、Context:模型的工作台,不是记忆,而是视野很多人有一个根深蒂固的误解:以为 AI 有记忆,就像跟一个人聊天一样,说过的事它都记得。每次模型处理你的请求,它其实是在看一份完整的"文件"——这份文件里装着所有它当前能看到的内容,这整个东西叫做 Context(上下文)。- System Prompt:开发者或产品预设的系统指令,相当于模型的"岗位说明"
- 工具结果:如果模型调用了搜索、代码执行等工具,返回的结果也装在这里
模型每次回答,都是基于这整份"文件"来推理的,而不是"想起了之前聊过什么"。这个区别很重要,因为它解释了两类常见的 AI 失效现象:上下文污染:对话里掺入了矛盾信息、无关内容,或者你中途改变了需求但没有明确说明,模型开始混乱,给出前后不一致的回答。上下文截断:对话轮次太多,最早的内容超出了 Token 窗口,模型"看不到"了。你以为它记得,其实它已经忘了——不是故意的,是物理上看不见了。理解了这个机制,就知道为什么有时候"多说两句背景"会让效果好很多——不是在哄模型,是在给它补全工作台上缺失的信息。管好 Context 的核心原则是:让每一个出现在视野里的 Token 都是有价值的。 无关的历史对话,没用的废话,都会稀释真正重要信息的权重。Prompt 这个词现在被说滥了,但真正理解它的人并不多。很多人以为 Prompt 是一种"技巧",好像背几个模板就能立竿见影。我更倾向于把它理解成一种信息组织能力——你有多大能力把一件事说清楚,Prompt 就能写多好。Prompt 不是玄学,它有结构,有层次,有工程化的方法论。- 约束:不能做什么,有什么限制,比如字数、语气、禁止使用某些词
缺了哪一个,模型都要靠猜。而模型猜出来的东西,往往不是你真正想要的。第一类是过于模糊。"帮我写一篇文章",文章是什么主题?面向谁?多少字?什么风格?模型只能给你一个最通用的东西。第二类是信息缺失。"帮我回复这封邮件",但没说你和对方是什么关系、邮件内容是什么、你想达到什么目的。第三类是格式失控。没有说清楚输出格式,模型可能给你一大段散文,可能给你一个 Markdown 表格,可能给你一堆 JSON,猜。3.2 System Prompt:藏在对话背后的总指挥如果你只是自己用用 AI,User Prompt 就够了。但如果你在做一个 AI 产品,或者管理一个团队在用 AI,System Prompt 就变得至关重要。System Prompt 是在对话开始之前写入 Context 的系统指令,用户通常看不见它,但它对模型的影响往往大于用户的每一条输入。- 角色定义:这个 AI 是谁,有什么专业背景,用什么语气说话
- 规则设定:可以做什么,不能做什么,遇到哪些情况要如何处理
- 边界划定:比如客服场景里不允许谈竞争对手,内容审核场景里不允许输出某类内容
一个设计得好的 System Prompt,可以让一个通用模型变成一个垂直领域的专家助手;而一个没有 System Prompt 的 AI 产品,就相当于让一个新员工不经过任何培训直接上岗。User Prompt 管的是"这一次做什么",System Prompt 管的是"一直以来是谁"。两者分工不同,缺一不可。3.3 Prompt Template:从手工操作到工程化会写 Prompt 只是第一步,让 Prompt 可以规模化使用,才是工程化的关键。Prompt Template(提示词模板) 的本质,是把一个好 Prompt 里固定不变的部分抽象成结构,把每次需要变化的部分留成变量。举个例子,一个客服场景的 Prompt 模板可能长这样:你是{品牌名称}的客服代表,语气{语气要求}。
用户问题类型:{问题类型}
用户原始提问:{用户输入}
请参考以下知识库内容作答:{知识库片段}
输出格式:先道歉/表示理解,再给出解决方案,控制在 100 字以内。
每次对话进来,只需要把变量填进去,一个经过精心设计的 Prompt 就能稳定运行,而不是每次都临时发挥。- 销售话术:根据不同客户类型和阶段,动态填充个性化信息
- 内容生成:批量生产同类内容,比如批量写商品描述、批量生成周报摘要
从手写 Prompt 到 Prompt Template,是从个人技巧到团队工程化的关键跨越。四、Memory:突破 Context 的边界,让模型记住你前面讲过,Context 是有上限的,而且每次对话结束,Context 就清空了,下次又是白板一张。这就带来了一个问题:如果你想让 AI 助手越用越懂你,怎么办?Memory 和 Context 的核心区别在于:Context 是被动的,装什么是当下决定的;Memory 是主动管理的,有人(或系统)在有意识地挑选、存储、调用信息。短期记忆:在一次会话内有效。比如你跟 AI 说"我叫小李,做市场的",这个信息在这次对话里一直有效,但下次打开新对话就消失了。长期记忆:跨会话持久保存。你说过的偏好、你处理过的事情、你的背景信息,被系统记录下来,下次对话时自动带入 Context。好的个性化 AI 助手,核心竞争力往往在这里。值得一提的是,RAG(检索增强生成) 本质上也是一种"外挂记忆"——不是把所有知识都塞进 Context,而是在需要的时候检索出相关片段再放进来。这是目前最主流的解决"知识太多、Context 装不下"这个矛盾的工程方案。Memory 的出现,让 AI 从"每次都陌生"变成了"越用越懂你",这是从工具到助手的关键一步。把前面所有内容放在一起,大模型输入层的完整结构大概是这样的:Token → 成本与长度的硬约束,一切的基础单位
Context → 模型当前的信息视野,装着它能看到的一切
├ System Prompt → 全局角色与规则,定义模型"是谁"
└ 对话历史 → 当前会话的信息流,动态更新
Prompt 体系 → 意图传递的组织方式,决定模型"做什么"
├ User Prompt → 单次任务的信息结构
└ Template → 工程化复用,从个人到团队
Memory → 跨越 Context 边界的持续积累,让模型"记住你"
很多人在想"怎么让 AI 更聪明",但这个问题问错了方向。模型本身的智能,不是你能控制的。你能控制的,是它看到了什么。把 Token 管好,是成本意识;把 Context 管好,是信息密度意识;把 Prompt 写好,是表达结构意识;把 Memory 设计好,是系统思维。这些不是 AI 专家的专属技能,是每一个想用好 AI 的人,迟早都要补上的基本功。
一文搞懂:从 Token 到 Agent,大模型应用到底是怎么跑起来的?
你打开某个 AI 助手,输入一句话:"帮我查一下今天北京的天气,然后起草一封邮件发给我的客户,告诉他下午的会议因为天气原因改到线上。"没多久,AI 回复了一封措辞得体的邮件,还顺便把天气信息嵌在了里面。如果你已经用 AI 工具一段时间了,你大概知道几个关键词:Token、Prompt、Agent、MCP……但你会发现,越学越乱——这些词哪里来的?彼此什么关系?为什么有人说 Prompt 工程是核心,又有人说 Agent 才是未来?问题出在学习方式上。大多数人是"工具驱动"的:看到什么工具热就学什么,却没有一条底层逻辑把这些概念串起来。就像学厨,光背菜谱,不知道为什么要先热锅后放油。这篇文章想做一件事:给你一张地图,沿着"模型如何读懂你 → 如何思考 → 如何行动 → 如何连接更大的世界"这条主线,把所有概念放进它该在的位置。
一、模型怎么"读懂"你的输入?Token + Prompt你在输入框打下"你好",在你眼里这是两个汉字。但模型收到的不是这两个字,而是经过切分处理的编码片段,也就是 Token。Token 是什么?简单说,是模型处理语言的最小单元。它既不是字,也不是词,而是介于两者之间的"语言碎片"——具体怎么切,取决于模型训练时采用的分词方式。中文和英文的 Token 效率差异很大。"hello" 通常是 1 个 Token,而"你好"可能需要 2 个甚至更多。这不是歧视,是语言结构决定的。也正因如此,同样一段话,用中文和英文输入,消耗的 Token 数量可能相差一倍。Token 为什么重要? 它直接影响三件事:成本(按 Token 计费)、速度(Token 越多处理越慢)、以及上下文长度限制——每个模型能"同时看到"的 Token 数量是有上限的,这个上限就是常说的"上下文窗口"。一旦超出,模型就开始"忘事"。很多人把 Prompt 当成"提问",以为就是在聊天框里打字。但实际上,Prompt 更像是你和模型签的一份合同——规定了模型在这次交互里的角色、行为边界和任务目标。System Prompt 是"规则层",在用户看不见的地方运行。它告诉模型"你是谁、你能做什么、你应该怎么回答"——比如"你是一名专业的法律顾问,回答时要保持严谨,不能给出具体法律意见"。这一层由应用开发者控制,用户通常感知不到。User Prompt 是"任务层",就是你实际输入的内容,"帮我写一封道歉信"之类的。两层叠加,模型才知道"在什么框架下、完成什么任务"。更进一步,当一个应用需要批量处理任务时,Prompt Template 就出现了——把 Prompt 里变化的部分抽出来变成变量,固定的部分保留。比如:请将以下 {{语言}} 内容翻译成 {{目标语言}},风格保持 {{正式/口语}}。
内容:{{内容}}
这样 Prompt 就从一次性的句子变成了可复用、可工程化的资产。这是 Prompt Engineering 真正的意义所在——不是写出一句"魔法咒语",而是把提示词变成可靠的生产资料。
LLM(Large Language Model,大语言模型)是整个应用的心脏。它负责三件事:理解你说了什么、推理应该怎么回应、生成文本输出。第一个:模型越大越好。事实上,不同规模和类型的模型适合完全不同的任务场景。处理长文档摘要,选一个上下文窗口长的模型;做代码补全,专门微调过的代码模型往往比通用大模型更稳定;如果你只是做简单的文本分类,用一个轻量模型不仅便宜,响应还更快。不是选最贵的,是选最合适的。第二个:模型能力是固定的。其实模型的表现高度依赖你怎么用它——给什么信息、下什么指令、用什么方式组织输入。这引出了下一个关键概念。每次模型处理一个任务,它能"看到"的所有内容,统称为 Context(上下文)。Context 里包含什么?几乎所有东西:你输入的 Prompt、对话历史、你上传的文档、工具返回的结果……这些信息在一次请求里打包送进模型,模型在这个范围内完成推理和生成。Context 有一个硬约束:它的容量是有限的(就是上面说的 Token 上限)。这意味着,如果你和 AI 聊了很久,早期的对话内容会被"挤出去",模型就开始"失忆"。这不是 bug,是设计限制。Context 的质量直接决定输出质量。 同一个问题,给模型一段干净、结构清晰的背景信息,和给一堆混乱的聊天记录,模型的回答可以天差地别。Context 管理,是大模型应用开发里最容易被低估的工程问题。LLM 和 Context 的关系,就像厨师和备料台的关系:厨师(LLM)的技术决定了上限,但备料台(Context)上放什么、放多少、怎么摆放,直接影响最终这道菜能做到什么水平。
三、模型怎么"行动"?Tool + Function Calling如果你只用 LLM 的"原生能力",它能做很多事——写文章、分析文本、回答问题。但它有两个根本局限:一是知识有截止日期。模型训练完成之后,它的知识就冻结了。你问它今天的天气、最新的股价、刚发布的新闻——它不知道。二是没有"手"。模型只能生成文本,它没办法真的去发一封邮件、查一个数据库、提交一个表单。它能告诉你"你应该发一封这样的邮件",但它自己发不了。Tool(工具)的出现,解决的正是这两个问题。给模型装上"手脚"——让它能查实时数据、执行操作、访问外部系统。Function Calling:模型调用工具的标准语言Tool 是概念,Function Calling 是具体机制。简单说,Function Calling 允许你预先定义一批"工具函数",并告诉模型每个工具能做什么、需要什么参数。模型在推理过程中,如果判断需要某个工具,就会输出一个结构化的调用指令,而不是普通文本。举个例子,你告诉模型:有一个工具叫 get_weather,接受城市名称,返回天气数据。当你问"北京今天热不热",模型不会瞎猜,而是输出一条调用指令。你的应用捕获这条指令,真正去调用天气 API,拿回结果,再把结果塞回 Context,让模型继续推理。这个闭环是大模型应用从"聊天机器人"变成"能干事的助手"的关键跨越。没有 Tool,AI 应用只是个复杂的输入输出框;有了 Tool,它才开始有真正的业务价值。
四、模型怎么"自主干复杂的事"?Skills + Workflow + Agent工具调用解决了单步执行问题。但现实里,很多任务不是一步能完成的。"帮我分析这份竞品报告,然后生成一份 PPT 大纲,发给产品团队征求意见"——这是一连串有依赖关系的步骤。这就需要更高层的组织方式。Skill(技能)是对一组能力的打包封装——通常是 Prompt + 特定 Tool + 调用逻辑的组合,解决一个特定的子任务。比如"摘要技能":内置了处理长文档的 Prompt 策略,知道什么时候需要分段处理,输出格式固定为三段式结构。这个技能可以被任何需要摘要功能的流程调用,不用每次重新设计。Skills 是构建复杂 AI 应用的基础零件。有了标准化的零件,才能搭出稳定的系统。当多个 Skill 需要按顺序、按条件依次执行,就需要 Workflow(工作流)来做编排。Workflow 的核心价值是可预测性。你定义了"先做 A,再做 B,如果 B 的结果满足条件 X 就走分支 C,否则走分支 D"——整个流程是确定的,可以测试、可以调试、出了问题知道在哪个节点排查。Workflow 适合那些步骤相对固定、对稳定性要求高的生产环境任务。它不够灵活,但足够可靠。Agent 是这条链路里最令人兴奋也最被过度包装的概念。Agent 和普通 LLM 调用的本质区别只有一个字:自主性。普通 LLM 是你说一步它走一步;Agent 是你给它一个目标,它自己决定走哪几步、用哪些工具、遇到问题怎么调整。但 Agent 并不是越自主越好。 自主性意味着不确定性。当前的 Agent 在处理模糊目标、多步依赖、需要精确执行的任务时,仍然容易"跑偏"或"过度行动"。很多被包装成 Agent 的产品,其实只是预设了很多分支的 Workflow。这不是贬义——对于生产环境来说,一个稳定的 Workflow 往往比一个自由的 Agent 更有价值。用一个比喻收尾:Skills 是零件,Workflow 是流水线,Agent 是工厂里那个能自主调度流水线的管理员。你需要什么,取决于你的任务有多复杂、对稳定性要求有多高。
随着 Agent 能力越来越强,一个新的问题浮出水面:每个 Agent、每个框架,都用自己的方式去连接外部工具和数据源。你在 A 框架里写了一个连接 GitHub 的工具,换到 B 框架就得重写。你给某个 Agent 接入了数据库,换一个 Agent 又得重新适配一遍。每个团队都在重复造轮子,生态极度碎片化。MCP,全称 Model Context Protocol,是由 Anthropic 在 2024 年底提出的开放协议。它想解决的问题很直接:定义一套标准接口,让任何 AI 应用都能用同一种方式连接任何工具和数据源。类比一下 USB 接口的出现。在 USB 之前,每种设备有自己的接口,鼠标、键盘、打印机各用各的线。USB 统一标准之后,设备和电脑不再需要一一适配,只要都支持 USB,就能互联。MCP Client 跑在 AI 应用侧(比如你的 Agent),负责发出请求——"我需要访问 GitHub 上的某个仓库"。MCP Server 跑在工具或数据源侧,负责响应请求——"收到,这是你要的数据"。Server 可以是连接 GitHub 的、连接数据库的、连接本地文件系统的……只要双方都遵循 MCP 协议,Client 不需要知道 Server 内部怎么实现,Server 也不需要知道 Client 是什么框架写的。MCP 目前已经得到了相当多主流 AI 工具和平台的支持,社区里的 MCP Server 数量也在快速增长——从 Google Drive、Slack、数据库,到各种开发者工具,几乎都有人在写 MCP Server。当然,MCP 还在快速演化阶段,不是所有场景都已经有完善的支持,安全边界、权限管理等问题也还在探索中。但它背后的逻辑是对的:AI 应用需要一个连接层的标准,而不是各自为政的适配地狱。这是 AI 应用从"单点工具"走向"生态系统"的必经之路。
读到这里,你已经走完了整条链路。现在用一句话把它们串起来:大模型应用 = 让模型读懂输入(Token + Prompt)× 在上下文中思考(LLM + Context)× 用工具行动(Tool / Function Calling)× 以Agent 身份自主执行(Skills → Workflow → Agent)× 通过协议连接外部世界(MCP)每一层都不是孤立的,都是在前一层的基础上增加了新的能力维度。这就是为什么理解底层逻辑比记住工具名更重要——工具会换,但这条链路的逻辑不会。大模型应用不是魔法,它是一套有逻辑的工程体系。搞清楚这条主线,再去看任何新工具、新框架,你都会知道它在这张地图的哪个位置,解决的是哪一层的问题。
一文读懂 Agent Skills:原理、机制、架构、代码与 AI 工程化落地全解析
你有没有遇到过这种情况:写了一个函数,需要补充单元测试。你打开 AI 助手,发了一句话过去。AI 给了你几个测试用例。但你看了一眼,发现边界条件根本没有覆盖,Jest 框架也没用,覆盖率更是没有任何说明。你只好重新发一条:"要用 Jest 框架,要覆盖边界情况,要生成覆盖率报告……"或者这个场景:团队里积累了几十个 Markdown 文档,格式乱、目录缺、链接死。你告诉 AI "帮我整理一下这些文档",AI 只是改了改标题格式,其他什么都没动。你想要的是统一格式、提取关键信息、生成目录、验证链接——这些它压根不知道。问题不是 AI 不聪明。问题是:它没有一套稳定的、可复用的能力链来完成这类任务。每次都要重新解释,每次执行结果都不一样,每次都是一次性的。这才是真正的痛点。Agent Skills 要解决的,就是这个问题。
Skill 是一个可被 Agent 在运行时发现、理解、调用和组合的能力模块。这句话里有四个动词——发现、理解、调用、组合——缺少任何一个,它都不能叫 Skill。用一个生活场景来理解:你手机里装了几十个 App。当你想导航的时候,不需要自己写路线规划算法,直接打开地图 App 就好。App 帮你把"导航这件事"封装好了——如何定位、如何规划、如何播报,全在里面。- Agent 是那部手机,负责理解你的意图并调度能力
- Skill 是那个 App,给 Agent 增加一项可调用的能力
再讲一个更贴近工程场景的类比是:你刚入职一家公司。你智商很高,学东西快,但完全不懂这家公司的业务。老板让你"处理一下这批退款并生成财务报告"。但如果书架上有一本《退款处理与财务报告生成 SOP》,你只需要按照手册里的步骤,用公司的工具(电脑、系统账号)一步步执行,结果就会是对的。它给 Agent 发的不是命令,而是一张图书馆借阅证——不是强迫它背下整个图书馆,而是让它在需要的时候去查。
很多人第一反应是:Skill 不就是一个很长的 Prompt 吗?写详细点,不就行了?Prompt 需要用户主动提供。你每次要用,就得自己把 Prompt 粘贴进去。Skill 不一样,Agent 可以根据你的任务描述,自动匹配到合适的 Skill,你不需要知道它叫什么名字。Prompt 本质上是"告诉 AI 做什么",但执行过程是 AI 自由发挥的。Skill 内部有结构化的 Workflow,每一步要做什么、怎么做、不能做什么,全都有明确规定。Prompt 是一次性的,散落在对话历史里,下次遇到同样的任务,你还得从头写。Skill 是独立的模块,一次定义,到处复用,还能持续迭代优化。用 Prompt 的方式补充单元测试,你需要写:"帮我给这个函数补充单元测试,要用 Jest 框架,要覆盖边界情况,要检查覆盖率,要……"——每次都要重复,容易遗漏,结果不稳定。用 Skill 的方式,你只需要说"帮我补充单元测试",Agent 识别到这是一个测试相关任务,自动加载 test-driven-development Skill,按照里面定义好的流程执行:理解代码 → 设计测试场景 → 编写测试代码 → 验证覆盖率。
上面说的是表层体验。从工程架构的角度看,Agent Skills 解决的是三个更深层的问题。很多团队的第一反应是:把所有业务规则、操作流程、边界条件全写进系统提示词。结果是上下文越来越长,几千 Token 变成几万 Token。这不只是钱的问题。当提示词超过模型能高质量处理的范围,会出现一个现象叫"注意力丢失(Lost in the Middle)"——中间部分的指令,模型大概率会忽略。越长的 Prompt,指令遵循能力越差。现在的 Agent 系统通常配了很多工具:能执行代码、能读写文件、能调 API。但拥有工具,不等于知道如何专业地使用工具。给 Agent 一个能执行 SQL 查询的工具,它能查。但它知道针对你这张五百万行的宽表应该怎么写查询吗?知道如何做多步关联验证吗?知道数据异常了该怎么回退吗?这些"操作智慧",工具给不了,必须单独注入。生产环境有一个基本要求:相同输入,相同输出。但依赖动态生成的提示词,系统行为会有大量随机性。今天跑正确,明天换个措辞就跑歪了。工程化系统需要确定性。需要把专家的隐性知识,转换成模型可以稳定执行的标准操作流程。这三个痛点,指向同一个缺失:缺少一种"可插拔的领域专家大脑"机制。 Agent Skills 填的就是这个空。
这是一个很多人想搞清楚的问题:我说一句话,Agent 是怎么判断要不要调用 Skill,调用哪个的?第一步:识别任务类型。 Agent 先判断你的请求是什么性质的任务——测试相关?文档处理?代码审查?这一步相当于分类。第二步:判断是否需要 Skill。 不是所有任务都需要 Skill。"Python 是什么语言"这种问题,直接回答就好,不需要任何流程。判断标准是:这个任务是否需要结构化的多步骤执行?是否有明确的验证标准?第三步:语义匹配。 如果判断需要 Skill,Agent 会在所有可用 Skill 的描述(description)里做语义搜索,找到最匹配的那一个。第四步:注入并执行。 找到 Skill 后,把 Skill 的完整内容注入到系统提示词,Agent 按照里面的 Workflow 一步步执行。第五步:整合输出。 Skill 执行完成,结果返回给你。系统启动时,只加载所有 Skill 的元数据(名字和描述),每个大约一百个 Token。等到识别到具体任务,才加载完整的 SKILL.md(几千 Token)。如果任务还需要外部参考资料,才在执行过程中按需加载(可能几万 Token)。这种设计让 Agent 能"知道"几百个 Skill 的存在,但只在真正需要的时候才"学习"具体内容。既保持了广度,又控制了成本。
理解了调用机制,我们来看 Skill 本身的结构。对用户来说,Skill 就是"我说一句话,Agent 按某套流程处理,然后给我结果"。不需要知道里面是什么。my-skill/
├── SKILL.md # 必需:核心文件
├── scripts/ # 可选:可执行脚本
├── references/ # 可选:参考文档
├── assets/ # 可选:静态资产
└── templates/ # 可选:输出模板
只有 SKILL.md 是必须的,其他都是按需添加。---
name: test-driven-development
description: 在实现任何新功能或修复 Bug 时使用,必须在编写实现代码之前调用
---
# 测试驱动开发
## Goal
引导使用 TDD 方法论来实现具体功能。
## Workflow
1. 理解需求:阅读功能描述,识别验收标准
2. 设计测试用例:列举测试场景,按优先级排序
3. 测试先行:用项目指定框架实现测试,确保初始失败
4. 实现代码:编写最小代码使测试通过
5. 重构:在不改变行为的前提下提升代码质量
## Constraints
- 绝对不能在写测试之前写实现代码
- 代码覆盖率最低要求 80%
- 每个测试必须独立、可重复运行
结构很清晰:frontmatter 是路由的入口,body 是执行的指南。description 字段尤其关键,它直接决定了这个 Skill 会不会在合适的时机被找到。写好和写差的区别很大:- 简单型:只有一个 SKILL.md,3-5 步线性流程,比如生成 Git 提交信息。五分钟就能写完。
- 多步骤工作流型:仍然只有 SKILL.md,但 Workflow 有分支逻辑,5-10 步,比如 TDD 开发流程。
- 资源依赖型:SKILL.md 加上外部资源目录,适合需要参考文档、执行脚本、使用模板的复杂任务。
理论说完了,来看代码。我们用一个具体任务串起来:实现一个天气查询 Skill,分别用 OpenAI SDK 和 LangChain 两套框架落地。---
name: get-weather
description: 获取指定城市的天气信息。在用户询问天气、气温或出行建议时使用。
---
# 获取天气信息
## Goal
根据用户询问,提供准确的天气信息。
## Workflow
1. 从用户请求中提取城市名称
2. 获取该城市当前天气数据(温度、天气状况、湿度、风速)
3. 以自然对话口吻返回结果
4. 如需对比多城市,分别获取后整合展示
## Constraints
- 默认使用摄氏度
- 只提供当前天气,不做长期预测
- 空气质量差时主动提醒
## Examples
用户:"北京今天天气怎么样?"
回答:"北京今天晴天,25°C,空气质量良好,适合出行。"
SkillRegistry(加载所有 Skill)
↓
SkillRouter(根据用户输入选择 Skill)
↓
SkillExecutor(注入 Skill 文档并执行)
import os, re, json
from pathlib import Path
from typing import Dict, List, Optional, Tuple
from dataclasses import dataclass
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com")
)
@dataclass
class SkillMetadata:
name: str
description: str
file_path: str
full_content: Optional[str] = None
class SkillRegistry:
"""扫描目录,加载所有 Skill 文件"""
def __init__(self, skills_dir: str):
self.skills_dir = Path(skills_dir)
self.skills: Dict[str, SkillMetadata] = {}
self._load_all_skills()
def _parse_skill_file(self, file_path: Path) -> Optional[SkillMetadata]:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 提取 YAML frontmatter
match = re.search(r'^---\s*\n(.*?)\n---', content, re.DOTALL)
ifnot match:
returnNone
frontmatter = match.group(1)
name_match = re.search(r'name:\s*(.+)', frontmatter)
desc_match = re.search(r'description:\s*(.+)', frontmatter)
ifnot name_match ornot desc_match:
returnNone
return SkillMetadata(
name=name_match.group(1).strip(),
description=desc_match.group(1).strip(),
file_path=str(file_path),
full_content=content
)
def _load_all_skills(self):
skill_files = (
list(self.skills_dir.glob("*.skill")) +
list(self.skills_dir.glob("*.md"))
)
for f in skill_files:
skill = self._parse_skill_file(f)
if skill:
self.skills[skill.name] = skill
def get_all_skills_summary(self) -> str:
return"\n".join(
f"- {s.name}: {s.description}"
for s in self.skills.values()
)
class SkillRouter:
"""调用 LLM,根据用户输入选择合适的 Skill"""
def __init__(self, registry: SkillRegistry):
self.registry = registry
def route(self, user_input: str) -> Optional[str]:
prompt = f"""
你是一个 Skill 路由器。根据用户输入选择最合适的 Skill。
可用 Skills:
{self.registry.get_all_skills_summary()}
用户输入:{user_input}
只返回 Skill 名称,没有合适的返回 NONE。
"""
response = client.chat.completions.create(
model=os.getenv("DEEPSEEK_MODEL", "deepseek-chat"),
messages=[{"role": "user", "content": prompt}],
temperature=0,
max_tokens=50
)
skill_name = response.choices[0].message.content.strip()
return skill_name if skill_name in self.registry.skills elseNone
class SkillExecutor:
"""加载完整 Skill 文档,注入系统提示词后执行"""
def __init__(self, registry: SkillRegistry):
self.registry = registry
def execute(self, skill_name: str, user_input: str) -> str:
skill = self.registry.skills.get(skill_name)
ifnot skill:
returnf"Skill '{skill_name}' 不存在"
system_prompt = f"""
你现在要执行以下 Skill:
{skill.full_content}
严格按照 Workflow 执行,遵守所有 Constraints,直接返回结果。
"""
response = client.chat.completions.create(
model=os.getenv("DEEPSEEK_MODEL", "deepseek-chat"),
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_input}
],
temperature=0.7
)
return response.choices[0].message.content
class AgentSkillsEngine:
"""系统入口,协调 Registry / Router / Executor"""
def __init__(self, skills_dir: str):
self.registry = SkillRegistry(skills_dir)
self.router = SkillRouter(self.registry)
self.executor = SkillExecutor(self.registry)
def process(self, user_input: str) -> Tuple[str, Optional[str]]:
skill_name = self.router.route(user_input)
ifnot skill_name:
return"抱歉,没有找到合适的 Skill 处理这个请求。", None
result = self.executor.execute(skill_name, user_input)
return result, skill_name
def list_skills(self) -> List[str]:
return list(self.registry.skills.keys())
engine = AgentSkillsEngine(skills_dir="./skills")
result, skill = engine.process("北京今天天气怎么样?")
print(f"回复:{result}")
print(f"使用 Skill:{skill}")
result, skill = engine.process("对比北京和长沙的天气")
print(f"回复:{result}")
LangChain 版本在架构上完全一致,换成 LCEL(LangChain Expression Language)的写法,用 | 操作符串联各组件:from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
class SkillRouter:
def __init__(self, registry):
self.registry = registry
self.llm = ChatOpenAI(
model=os.getenv("DEEPSEEK_MODEL", "deepseek-chat"),
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com"),
temperature=0
)
self.prompt = ChatPromptTemplate.from_messages([
("system", """你是一个 Skill 路由器。
{skills_summary}
规则:只返回 Skill 名称,没有合适的返回 NONE。"""),
("human", "{user_input}")
])
# LCEL 链:提示词 → 模型 → 解析输出
self.chain = self.prompt | self.llm | StrOutputParser()
def route(self, user_input: str) -> Optional[str]:
result = self.chain.invoke({
"skills_summary": self.registry.get_all_skills_summary(),
"user_input": user_input
})
skill_name = result.strip()
return skill_name if skill_name in self.registry.skills elseNone
class SkillExecutor:
def __init__(self, registry):
self.registry = registry
self.llm = ChatOpenAI(
model=os.getenv("DEEPSEEK_MODEL", "deepseek-chat"),
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com"),
temperature=0.7
)
self.prompt = ChatPromptTemplate.from_messages([
("system", """执行以下 Skill:
{skill_content}
严格按照 Workflow 执行,直接返回结果。"""),
("human", "{user_input}")
])
self.chain = self.prompt | self.llm | StrOutputParser()
def execute(self, skill_name: str, user_input: str) -> str:
skill = self.registry.skills.get(skill_name)
ifnot skill:
returnf"Skill '{skill_name}' 不存在"
return self.chain.invoke({
"skill_content": skill.full_content,
"user_input": user_input
})
LangChain 版本和 OpenAI SDK 版本的逻辑完全相同,差别只是表达方式。如果你的项目里已经在用 LangChain 的生态,直接接入就好;如果是新项目,两种都可以,OpenAI SDK 版本更轻量。
怎么选:Skills、Function Calling、MCP 的边界用了这么久,有一个绕不开的问题:这三个东西什么时候用哪个?- Function Calling:代码级函数调用。你定义函数签名,AI 决定什么时候调用它,调用后你处理结果。执行是确定的,代码写什么就跑什么。
- MCP(Model Context Protocol):协议级能力接入。标准化的接口协议,让 AI 能接入各种外部系统(数据库、文件系统、第三方服务)。解决"如何连接"的问题。
- Agent Skills:语义级能力模块。用 Markdown 描述"做什么、怎么做、不能做什么",AI 按照描述执行。解决"如何专业地完成"的问题。
确定性要求高不高? 金融交易、数据库写入、触发支付——这些场景不允许任何随机性,必须用 Function Calling。给定相同输入,一定要得到相同输出。需不需要快速迭代? 如果你还在验证阶段,需求每周都在变,Agent Skills 的优势很明显。改 Markdown 比改代码快,也不需要重新部署。等流程稳定了,再考虑要不要换成 Function Calling。团队里有没有非技术人员? 产品经理、运营想定义工作流,但不会写代码——Agent Skills 是唯一的选项。描述清楚流程和规则,就能用起来。需不需要跨平台复用? 同一套能力要在多个 AI 系统里用,MCP 的标准化协议价值才体现出来。如果只在一个系统里用,MCP 的开发成本未必值得。实际项目里,这三个通常是组合使用的:高层工作流用 Skills,底层精确操作用 Function Calling,跨系统集成用 MCP。 不是非此即彼,是各司其职。
当你的 Skill 库积累到几十个,如果各个 Skill 的 description 语义重叠,Agent 就会开始"选择困难"。用户说"处理这个文件",Agent 在 file-processor、document-analyzer、data-extractor 之间反复横跳。解法:每个 Skill 的 description 要有清晰的边界,而且要加"负向触发器"——明确写出"本 Skill 不处理 X 类任务"。比如:description: |
当用户需要提取文本或处理 PDF 结构时使用。
不用于处理纯文本文件或代码仓库扫描。
Skill 里定义了"读取 references/ 目录下的文档",但没有限制读取量。执行时 Agent 把整个目录的内容全加载进来,几万 Token 一下就打满了。解法:在 SKILL.md 里明确限制:"每次最多读取 5000 Token,使用 grep 过滤后再读取,不要全量加载。"新手最常见的错误:把 description 写得很详细,一段话解释背景、功能、使用场景、注意事项。结果适得其反——description 太长太复杂,路由器反而判断不准了。description 要短、精、关键词密度高。一两句话,清晰说明触发时机和核心能力。Skill 里引用了某个外部接口的格式,接口升级了,Skill 没更新。或者团队的代码规范变了,Skill 里的标准没跟上。这种"静默降级"很隐蔽——系统不报错,但结果越来越偏。解法:建立定期审计机制。每隔一段时间,人工检查 Skill 的 Workflow 和 Constraints 是否还与实际情况对齐。
Agent Skills 不是什么革命性的新概念。它做的事情,说穿了很朴素:把专家的知识和流程,结构化地写下来,让 AI 能稳定地照着执行。就像公司有了流程手册,新人上手更快,老员工犯错更少,团队整体输出更稳定。AI 也一样。给它一本好的手册,它就能更好地工作。Prompt 是你告诉 AI"去做这件事"。Skill 是你提前准备好了"这件事怎么做"。
Anthropic 最新播客 如何打造下一代 Claude